注出处:下面内容参考阅读苏神的博客https://kexue.fm/category/Big-Data/3/
Prompt方法概述
在知乎“随机游走”阅读的时候,看到了Prompt方法好像有点流行,于是看看
大致意思就是先前,大伙一直把Mask Language Model以及Next Sentence Predict作为一个初始化模型的好方法(预训练提供的一个优良初始化,微调就可以很快)
但是有聪明人就发现了我能不能下游任务做的时候,直接把下游任务转化为预训练任务呢?
于是就有模版(英文常称Pattern或Prompt)
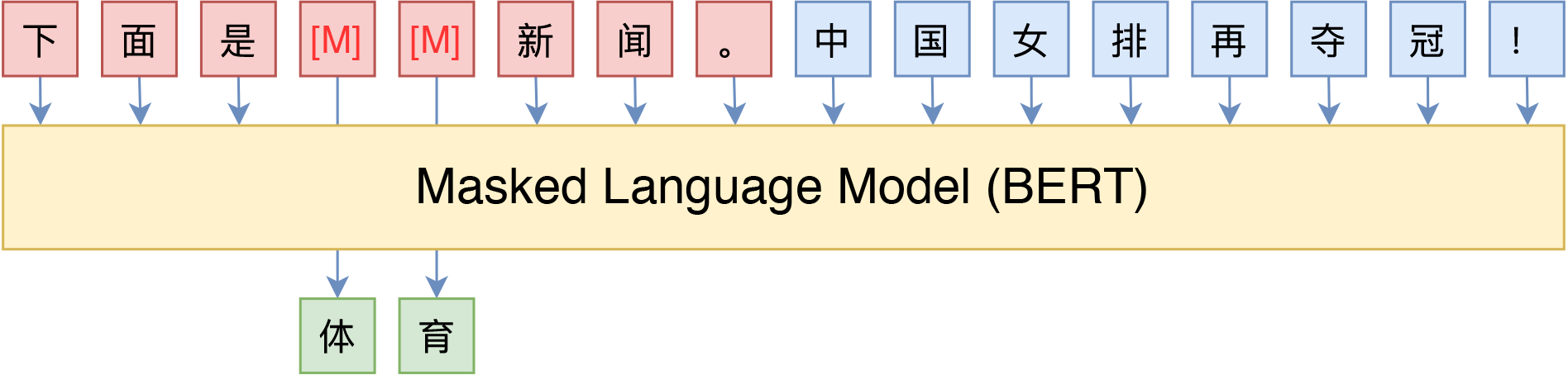
比如说一个情感分析任务,给定句子,输出情感类别正向还是负面。假如我在后面加上 “ I [MASK] it”
再让模型预测MASK部位,输出的like或者hate其实就是情感。
其实在MLM的预训练的时候,模型就有机会这样学习并输出带有情感的动词,因此这个pattern相当于是很直接的挖掘了模型在MLM里学习的东西,因此Prompt方法甚至可以做到Zero Shot,不需要微调就会有很好的效果。

P-Prompt
简单的说就是不使用人工构造的模板
而是插入一些新的Token,然后让模型也可以自己的去学习这些unused token的表示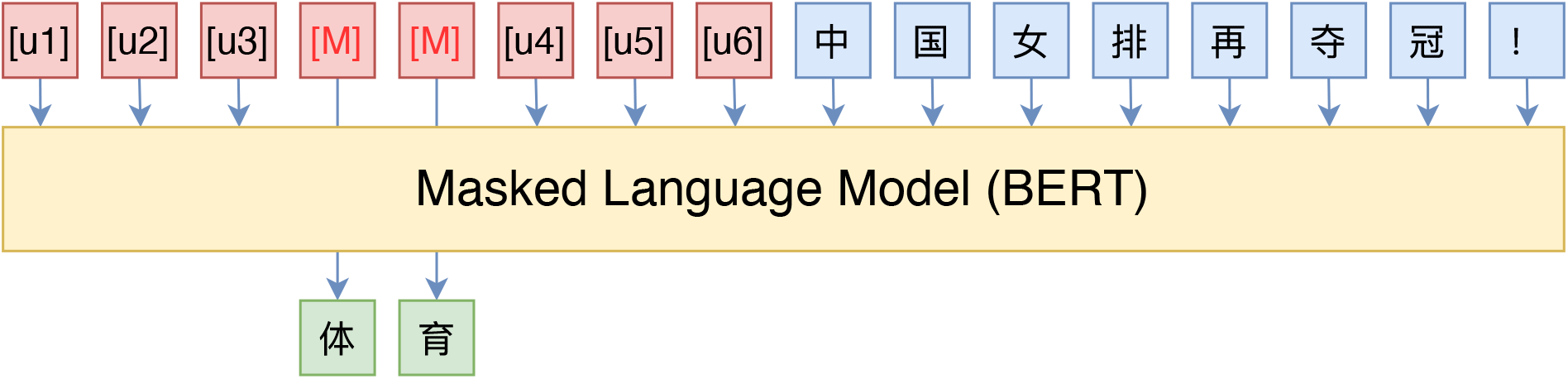
等等,我们真的在乎模版是不是“自然语言”构成的吗? 并不是。本质上来说,我们并不关心模版长什么样,我们只需要知道模版由哪些token组成,该插入到哪里,插入后能不能完成我们的下游任务,输出的候选空间是什么。模版是不是自然语言组成的,对我们根本没影响,“自然语言”的要求,只是为了更好地实现“一致性”,但不是必须的。于是,P-tuning考虑了如下形式的模版:
和Adapter的关系
我们还可以从Adapter的角度来理解P-tuning。BERT出来后不久,Google在论文《Parameter-Efficient Transfer Learning for NLP》中提出了一种名为Adapter的微调方式,它并不是直接微调整个模型,而是固定住BERT原始权重,然后在BERT的基础上添加一些残差模块,只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。Adapter的思路实际上来源于CV的《Learning multiple visual domains with residual adapters》,不过这两年似乎很少看到了,也许是因为它虽然提高了训练速度,但是预测速度却降低了,精度往往还有所损失。 在P-tuning中,如果我们不将新插入的token视为“模版”,是将它视为模型的一部分,那么实际上P-tuning也是一种类似Adapter的做法,同样是固定原模型的权重,然后插入一些新的可优化参数,同样是只优化这些新参数,只不过这时候新参数插入的是Embedding层。因此,从这个角度看,P-tuning与Adapter有颇多异曲同工之处。
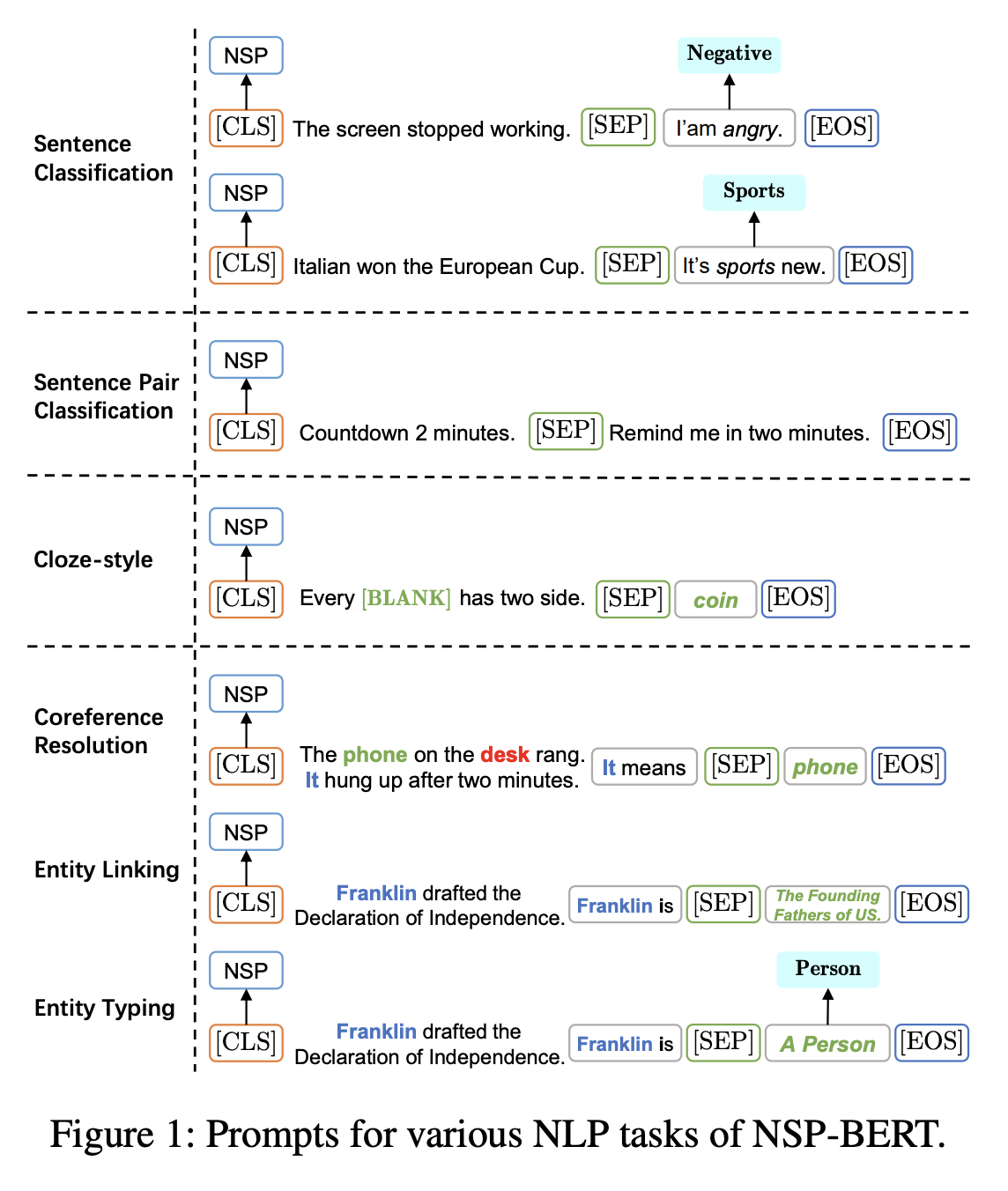
NSP Prompt

若有收获,就点个赞吧
0 人点赞
