1.Introduction
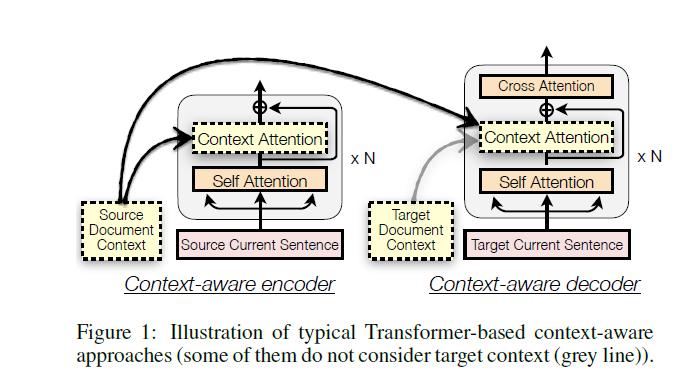
传统的利用上下文的方法就是直接把整个文档编码,然后作为一个额外的输入和Local句子的编码放到一起
二者被深度的混在一起输入到网络里
这样子有一些问题
- 模型虽然可以观测到全局的信息,但是由于完全混在一起导致对上下文噪声敏感。这同样可以解释先前的研究得到的全局信息导致翻译结果变差的理由
- 模型翻译了整个文档,但是不能翻译单独的句子,由于需要接收额外的全局信息的输入导致的不兼容
解决上述的问题
新模型不单纯的混合信息,而是分开有取舍的混合
HighLight
- 新框架得以解决任意句子数目的文档,包括单句子的
- 在四个大规模数据上实验效果好
- 基于上述结果得到了上下文重要性,排除了上下文导致性能下降的观点
2. Related Work
现存的模型有两种
- Context Aware Model
- Post processsing Model
后者引入了额外的模块来规整不可见上下文的翻译结果,容易实现但是可能错误累积
实际上后者是可以嵌入到所有NMT模型的
先前的工作
- 使用一些原句子拼接
- 改进简单的拼接,使用独立的encoder用于少量上下文
- 使用了分层RNN概括上下文
- 使用动态内存记忆先前的翻译结果
一直认为对全局文章建模务必要,都是对临近的文章句子进行建模
本模型不这么想,同时上面的模型都有额外的模块处理全局信息,使得对句子级别翻译不兼容
3. BackGround
- 句子级别翻译:使用encoder-decoder结构,用极大似然估计最大化正确翻译在观测到原文的概率(NLP常见的一些公式和方法

- 文档级别翻译:给点了文档级别的平行语料,原文档和目标文档的句子数目相等,同样的可以看作是一个句子一个句子翻译过程中的极大似然概率,也就是基于观测到的原句子以及原句子周边的上下文还有在此之间翻译好的句子,来最大化当前正确翻译出现的概率

4.Approach
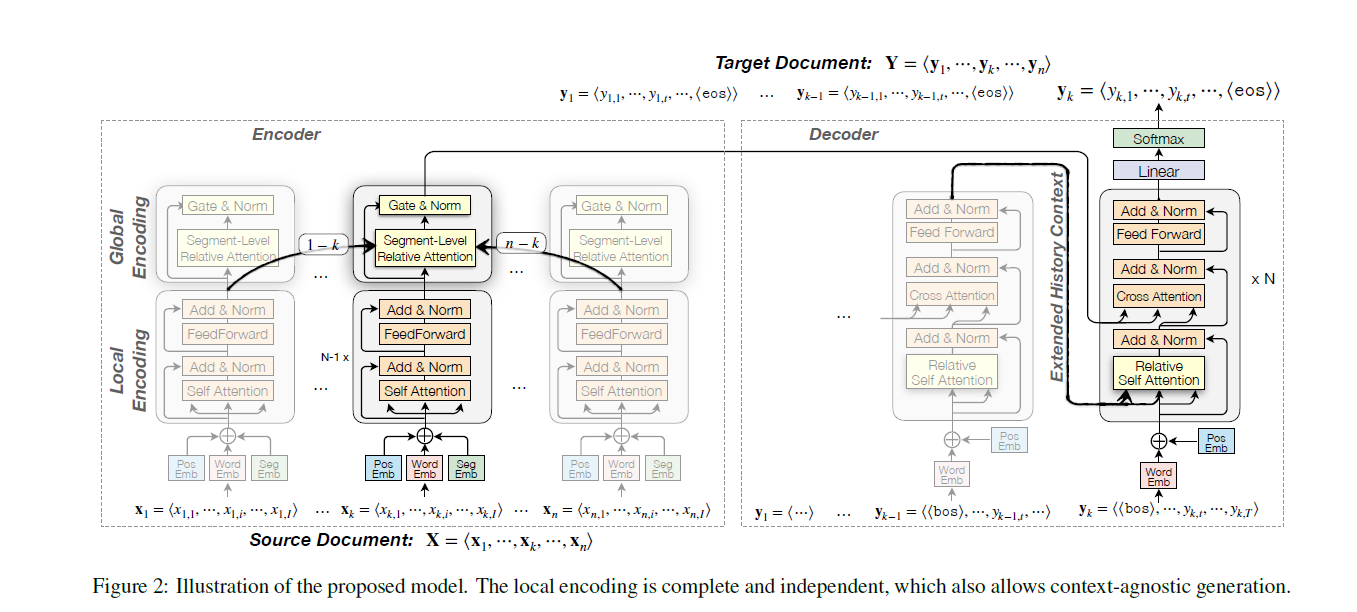
4.1 Encoder
Lexical and Positional Encoding
编码器里的Embedding是有3个部分构成的,字本身的编码,加上词位置的编码以及句子在文档位置的编码,后两个的“位置编码”是共享权重的,也就是第一个句子和第二个句子的第一个词的位置编码是一样的
这三个部分的编码加在一起构成了Embedding
如下,k是第k句子,i是句子中词的位置。第一部分是原先的编码,第二个是表示segment级别的embedding也就是句子的位置对应的向量,最后一个是word级别的,也就是在句子里位置的embedding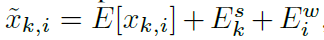
Local Context Encoding
利用多层堆叠的Multi-Head Attention作为局部文章编码,第零层表达就是输入,第N-1层的就是输出的表达
Global Context Encoding
利用Segment级别的Attention在整个文档中获取全局信息
最终的输出表示基于全局和局部的信息混合
利用了“gated context fusion mechanism”技术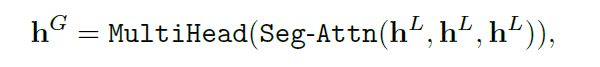
Segment-level Relative Attention
也就是上一节所提到的Segment级别的Attention
这里就是对应的原理公式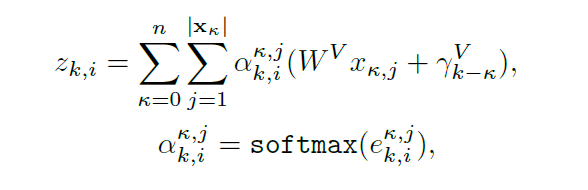
最原始的Transformer的Attention是针对一个句子里的两个词之间计算权重,然后得到词和其他所有词的权重比
这里类比就是对句子两两计算,token级别的计算是用原先的word embedding和WQ,WK,WV得到Q,K,V
这里就是用上面得到句子embedding做一样的事情。计算的时候就是对所有的句子的所有token做,实际上是一个2维的权值分布
下面的公式就是具体的权值计算方法
两个K分别是代表两个句子的位置,i和j就是句子里对应词的位置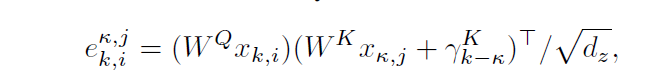
最后引入的一个新的未知数是用来表征两个句子位置的embedding,对应的就是两个句子的位置作为索引,用来表征两个句子的相对位置的信息
a parameter vector corresponding to the relative distance between the k-th and K-th sentences
Gated Context Fusion
这一层的信息应该就是关于论文里提到的所谓的动态的加入全局的数据信息的“动态”,这一层的结果就是所谓的全局信息的输出
其实就是把前面的使用全局信息(Segment Attention)与否的两个输出矩阵拼接,然后使用全连接层转化,接着Sigmoid化简到0-1之间,然后利用这个对两个数据矩阵做加权,也就是所谓的动态“取舍”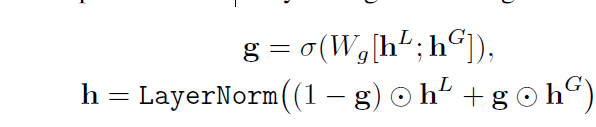
4.2 Decoder
这里的Decoder的一个创新就是他希望能够使用到之前已经翻译出来的信息,于是使用了一个缓存的机制,缓存了之前的Hidden State,作为Decoder额外可以接触的信息
A natural idea is to store the hidden states of previous target translations and allow the self attentions of the decoder to access to these hidden states as extended history context.
于是论文使用了Transformer-XL模型,听起来是Transformer的变种,确实没用过不懂

Analysis and Discussion
Does Bilingual Context Really Matter?
答案是肯定的
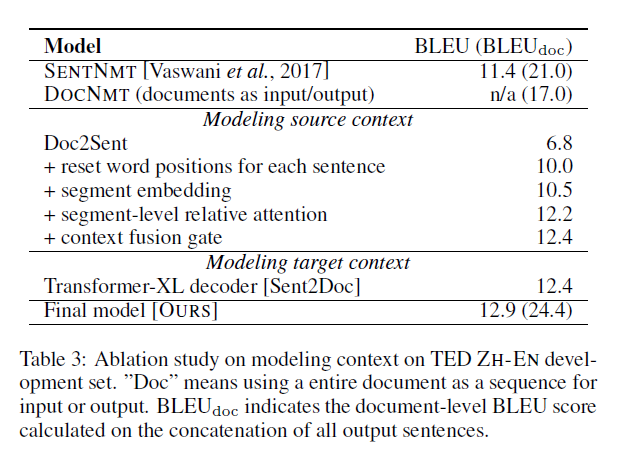
经过实验,直接输入整个文档,在输出整个文档是不可行的,生成的翻译结果文档做不到和原文档的句子数目相同,甚至比句子级别的Baseline还要差。
重置位置编码(word positions)和引入段嵌入矩阵(Segment Embedding)有一定的效果缓解问题
也就是证明了几个问题
- 那就是在翻译的时候要更加的专注于局部句子的信息
- 同时也证明了使用segment-level relative attention 和 gated context fusion mechanism来抽取和聚合原文的全局信息是有效的
- 同时使用Transformer-XL来保存和利用历史的全局翻译信息对提高文档级别的翻译结果也是有效的,这个和另一个研究里的结论:使用目标上下文导致传播错误,有一定的差异
- 对原文和目标文档的融合建模对提高表现有帮助
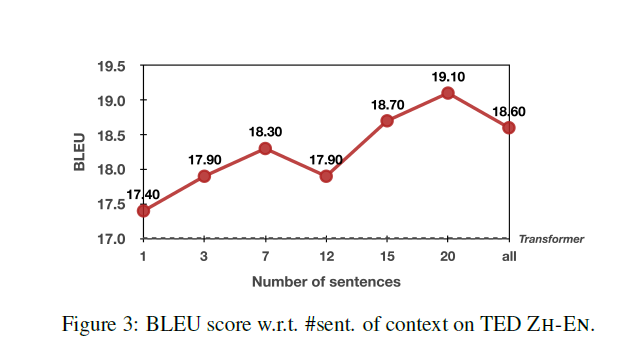
Effect of Quantity of Context: the More, the Better
上下文数量的影响:越多越好
实际上这个工作表明了这个模型在聚合上下文的表现
也就是利用了模型能够利用历史信息的能力,使得在利用上下文的时候收获比损失的多
(在纯正有效的局部句子的主导下,带有噪声的上下文被模型提取利大于弊)
We attribute this advantage to our hierarchical model design which leads to more gains than pains from the increasingly noisy global context guided by the well-formed, uncorrupted local context.
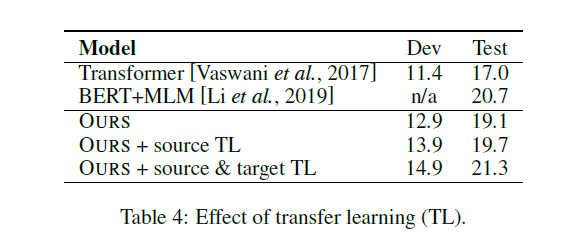
Effect of Transfer Learning: Data Hungry Remains a Problem for Document-level Translation.
迁徙学习缓解文档级翻译数据不足的问题
对于文档级翻译的平行语料还是太少
论文作者在WMT18上进行pretrain(句子级别的平行语料,把句子认为是文档)
然后在TED文档级别的平行语料上进行Fine-Tuning,然后效果更好
比较对象包括仅初始化了Source的encoder以及source和target都初始化的
我的理解就是用微调后的encoder来替换?
没有迁移学习的encoder就是Transformer原来的,然后考虑替换为pretrain+Fine-Tuning后的?
We also compare to a variant only whose encoder is initialized (source TL).
What Does Model Learns about Context? A Case Study.
论文作者对模型是如何学习所谓的上下文,进而把所谓的全局上下文信息利用起来的
于是打印了句子到句子之间的Attention权重图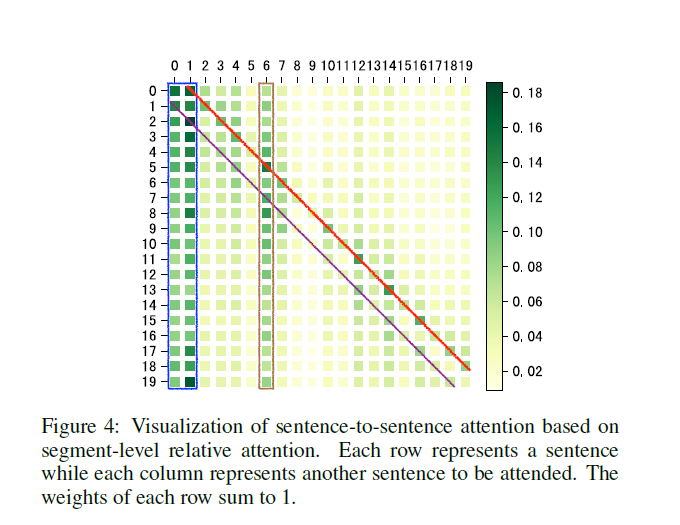
这个图里就是两个句子之间的权重分布,这个权重的得到见前文,实际上是两个句子的每一个字(两两之间)的权重之和,最后除于句子长度
在可视化的图里发现了比较有意思的patten:
- 对于文档的前2句话(蓝色框),也就是大多数文档的中心句在其他句子的翻译里起到比较大的帮助
- 前后临近的句子有相对大的权重(两条对角线),也就是上下文的重要性
- 对于后面的句子的权重大于前面句子的权重,可能是由于在翻译的过程里,由于Decoder只有前面的句子翻译信息(Target文档只能看到历史信息,未来的信息看不到),所以就导致了在句子间Attention的时候需要更多的吸取后面的信息
- 看上去在Segment Attention的时候模型并不关心本地局部句子的信息,可能是因为前面的Local 句子已经直接流动到了后面,不需要在句子间Attention来获取,这里的Attention就会更加倾向于去获取所谓的有用的全局信息
- 第六句在其他的句子有大权重,可能是因为比较重要,特殊角色
Analysis on Discourse Phenomena
想要分析知道,到底这个模型有没有解决那些不可知到上下文(没有利用文档信息的)模型的问题(Discourse)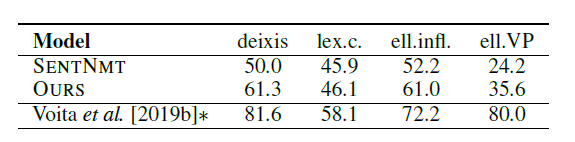
最后一栏的使用上下文不可知的baseline跑了一个草稿,然后做了一些后期的处理
这个没法直接比较,但是可能可以嵌入到论文模型达到更好的效果
Conclusion
总结就是推出了一个模型可以成功的利用广大的上下文信息,把本地和全局信息结合起来
进而未来可以尝试把这个用到文本生成上面

若有收获,就点个赞吧
0 人点赞
