学会提问的BERT:端到端地从篇章中构建问答对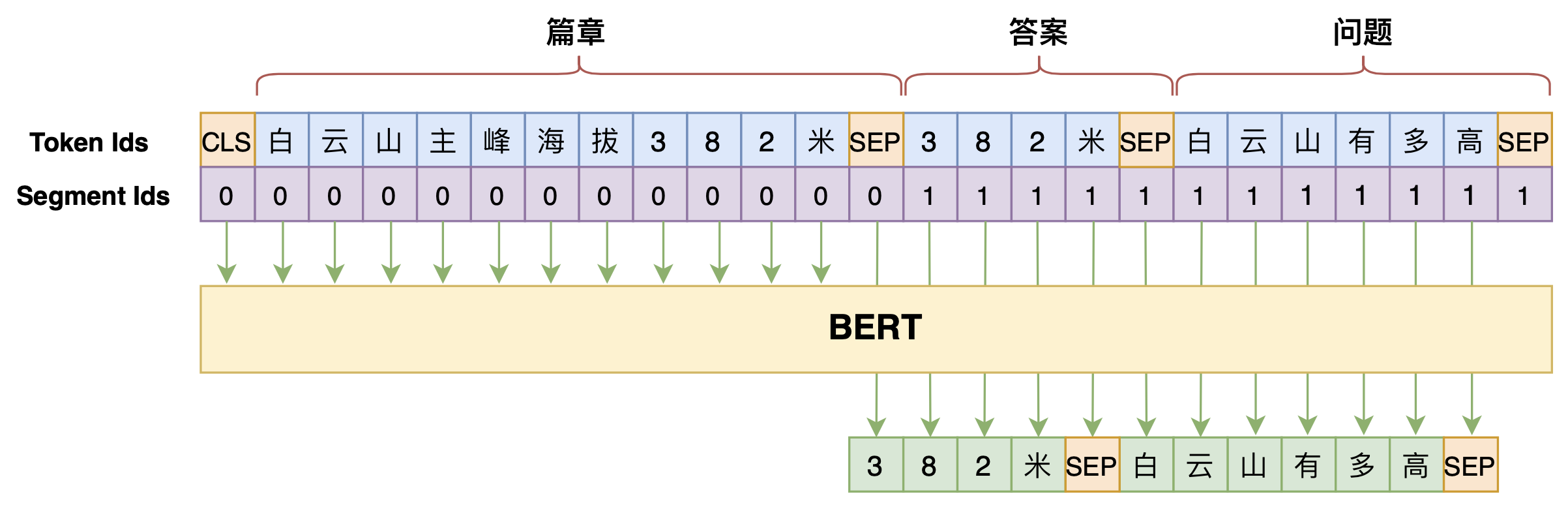
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率
如何划分一个跟测试集更接近的验证集?
用一个分类器
- 参数更少,不容易过拟合;
- 不依赖于分词算法,避免边界切分错误;
没那么严重的稀疏性,基本上不会出现未登录词。
序列变短,处理速度更快;
- 在文本生成任务上,能缓解Exposure Bias问题;
- 词义的不确定性更低,降低建模复杂度。
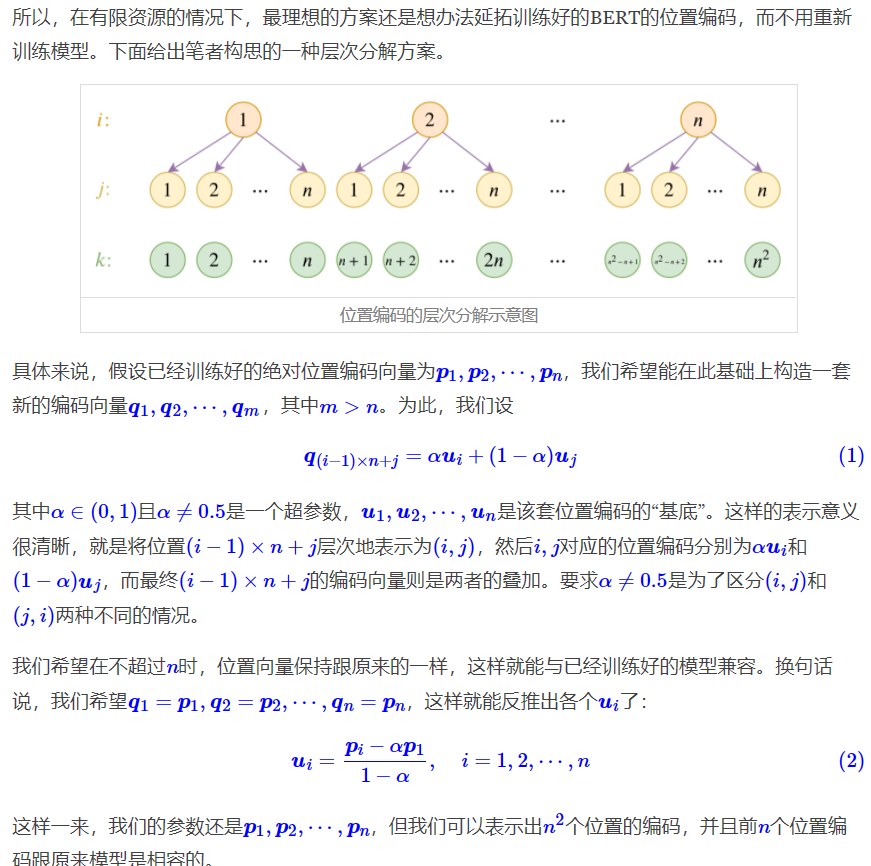
跟风玩玩目前最大的中文GPT2模型(bert4keras)
挺好的,如果有实际使用的时候可以用一用

若有收获,就点个赞吧
0 人点赞
