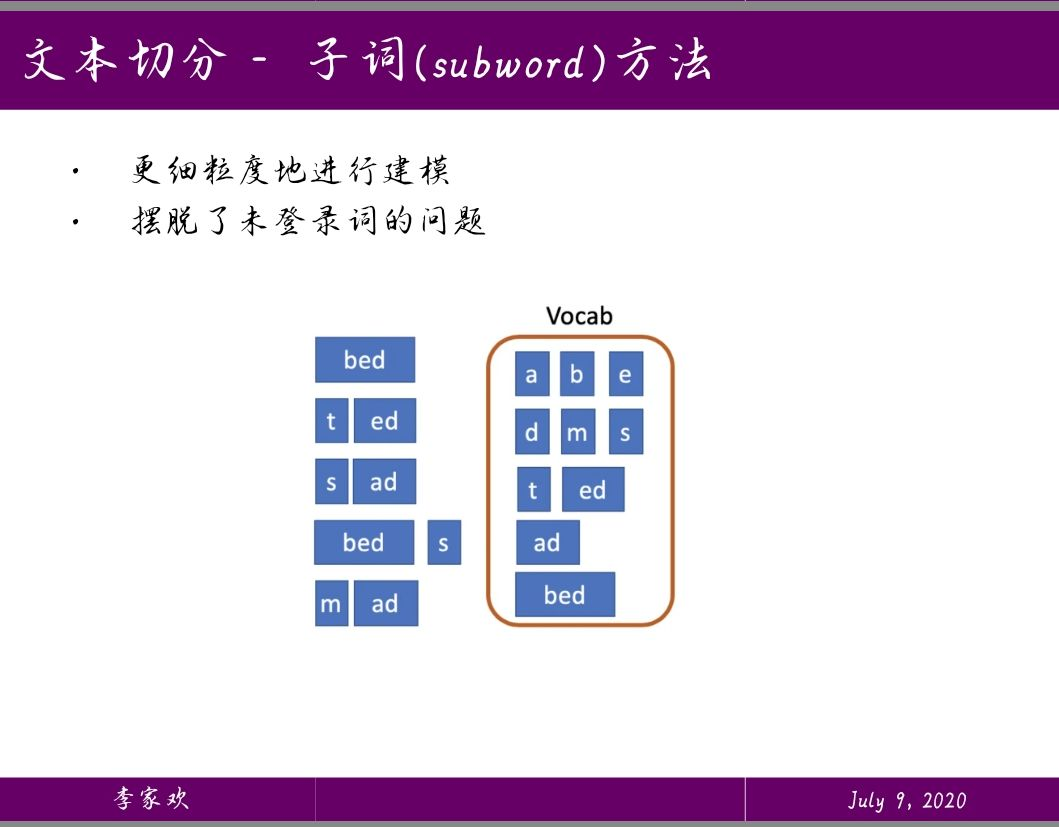
当前的分词策略可能就是简单的用空格进行分割,然后建立词表
引入BPE分词算法
引用链接:
概述
比如我们想编码: aaabdaaabac 我们会发现这里的aa出现的词数最高(我们这里只看两个字符的频率),那么用这里没有的字符Z来替代aa: ZabdZabac Z=aa 此时,又发现ab出现的频率最高,那么同样的,Y来代替ab: ZYdZYac Y=ab Z=aa 同样的,ZY出现的频率大,我们用X来替代ZY: XdXac X=ZY Y=ab Z=aa 最后,连续两个字符的频率都为1了,也就结束了。就是这么简单。 解码的时候,就按照相反的顺序更新替换即可。
具体
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
停止符”“的意义在于表示subword是词后缀。举例来说:”st”字词不加”“可以出现在词首如”st ar”,加了”“表明改字词位于词尾,如”wide st“,二者意义截然不同。 每次合并后词表可能出现3种变化:
- +1,表明加入合并后的新字词,同时原来的2个子词还保留(2个字词不是完全同时连续出现)
- +0,表明加入合并后的新字词,同时原来的2个子词中一个保留,一个被消解(一个字词完全随着另一个字词的出现而紧跟着出现)
- -1,表明加入合并后的新字词,同时原来的2个子词都被消解(2个字词同时连续出现)
实际上,随着合并的次数增加,词表大小通常先增加后减小。 例子 输入:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
Iter 1, 最高频连续字节对”e”和”s”出现了6+3=9次,合并成”es”。输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}
Iter 2, 最高频连续字节对”es”和”t”出现了6+3=9次, 合并成”est”。输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w est </w>': 6, 'w i d est </w>': 3}
Iter 3, 以此类推,最高频连续字节对为”est”和”“ 输出:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w est</w>': 6, 'w i d est</w>': 3}
…… Iter n, 继续迭代直到达到预设的subword词表大小或下一个最高频的字节对出现频率为1。
优势
- 对词表大小的压缩
- 可以识别出词的派生和复数等形式
- 对未出现的陌生的词有识别到,而不用
代表


若有收获,就点个赞吧
0 人点赞
