中兴捧月文本匹配(text matching)
数据预处理
数据是脱敏句子,已经抽象编码好了,不再重复编码。
针对句子的不定长的问题进行截断和补0处理
模型设计
数据特征
输入的是脱敏后的句子,没有现成的预训练模型可用
目标是预测相关性
词表有52000个词左右
设计思路
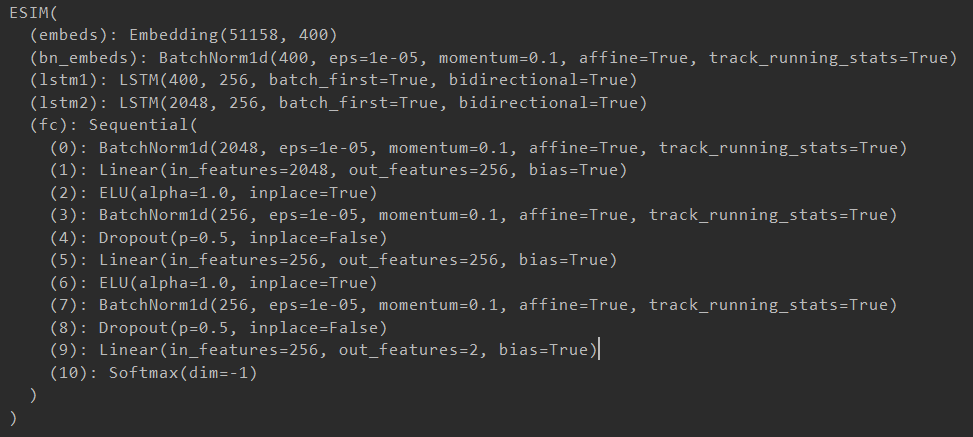
传入数据是一对句子,考虑使用孪生LSTM的思路解决
思路就是
- 输入两个句子
- 分别通过网络
- 嵌入层编码
- 对数据归一化
- 输入LSTM提取特征
- 利用Attention和Mask处理序列
- 经过LSTM2
- 最后经过若干连接层等构成的块
- 最后经过softmax分类输出
模型结构
调参分析
可调的参数有:
- 截断和补全的句子长度
- 词向量维度
- 学习率
- 是否使用预训练词向量
- dropout设置
- 隐藏神经元数目
关于句子长度经过实验设置为25较为合理
句子最短的只有1,最长的有32,极端的句子长度的表现都较差
词向量维度,基于数据量以及先前的一些实验,设置为400维,过大导致数据不够训练的不充分
学习率设置为0.01
不使用预训练词向量
dropout设置为0.5和0.2,过拟合现象,调大dropout。
最终的参数设置
embedding_dim=400hidden_dim=256vocab_size=51158target=1 #预测分类数Batchsize=128stringlen=25 #句子长度Epoch=20lr=0.001
运行方法
文件目录
data是数据集的位置
Model里保存了训练参数
read_txt读取数据集
get_data对数据集预处理
esmi是模型实现
test是训练评估和预测
load加载模型做预测和评估
运行
直接运行test.py即可
该文件会调用其他模块完成数据读写的操作
(前提是保证data目录下有对应的数据文件)
如果不重新训练,只进行评估和预测可以使用load.py
load.py内置了eval和output,分别进行评估和输出预测的功能
最后结果
在测试集表现86%的正确率
前期收敛较快,后期稳定增长
问题分析
- 比赛缺乏经验,数据处理和模型选择不太会
- 代码里有bug,写的时候大量的复制粘贴,有的地方没有改,导致了一些错误,比如预测集读取数据的时候竟然用的是一样的句子,testa=testa,testb=testb。。。难怪初期的跑分数据那么糟,这个问题还到了比赛DDL的时候才发现,最后一次提交就是用修正后的运行。这个问题对调参和模型选择影响很大,也是我那么早就放弃比赛的罪魁祸首之一。。。
- bert很好用,很多人也用,自己竟然太懒了,,,懒的去调试着用。。。
- 词向量预训练上有问题,使用预训练之后效果更差,应该是哪里没配置好
- 代码的组织结构有问题,之前一直就是一个文件从头写到尾,对于平时随便写的神经网络没有啥影响,但是比赛的时候反复的调参以及修改模型,平时的代码结构和文件结构以及运行方式等都明显有问题,版本乱七八糟的,也没有好好的记录,以至于本就低效的调参更差了
read_txt.pySheShuaiJie_NJU_predict.txttest.pyesmi.pyget_data.pyload.py

若有收获,就点个赞吧
0 人点赞
