赛题
https://www.kaggle.com/c/nlp-getting-started/
升级方案
原模型实现混乱,训练集没有很好的划分出测试集
网络较为简单,过拟合现象严重
升级:
- 再加上一层线性层
- 再加上一层Dropout层
- 加上若干层的激活函数
- 调整选取最佳训练效果的代码
- 调整测试集划分
模型
datalabel len: 6000
evallabel len: 1613
datalist len: 6000
evallist len: 1613
datalen: 25
using GPU
embedding_dim=300
hidden_dim=256
vocab_size=len(dict)
target=2
Batchsize=16
stringlen=25
Epoch=20
lr=0.005
LSTMTagger((word_embeddings): Embedding(45802, 300)(lstm): LSTM(300, 256)(dropout1): Dropout(p=0.5, inplace=False)(dense): Linear(in_features=6400, out_features=256, bias=True)(op_prelu): PReLU(num_parameters=1)(dropout2): Dropout(p=0.5, inplace=False)(hidden2tag): Linear(in_features=256, out_features=2, bias=True)(op_tanh): Tanh())
代码
import pandas as pdimport numpy as npfrom sklearn.preprocessing import MinMaxScalerimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchimport timeUSE_CUDA = torch.cuda.is_available()base_path=""read_train=pd.read_csv(base_path+'train.csv')train_data=read_train.iloc[0:read_train.shape[0],[1,2,3]]train_label=read_train.iloc[0:read_train.shape[0],[4]]train_label=[i for i in train_label.target]read_test = pd.read_csv(base_path + 'test.csv')test_data = read_test.iloc[0:read_train.shape[0], [1, 2, 3]]a=[]sentence=""for i in range(0, len(train_data)):sentence=sentence+str(train_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(train_data.iloc[i]['location'])sentence += " "sentence=sentence+str(train_data.iloc[i]['text'])sentence += " "for i in range(0, len(test_data)):sentence=sentence+str(test_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(test_data.iloc[i]['location'])sentence += " "sentence=sentence+str(test_data.iloc[i]['text'])sentence += " "dict = sentence.split()dict=set(dict)print(len(dict))w2i={}def word2index():index=0for i in dict:w2i[i]=indexindex+=1word2index()train_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in train_data.keyword]train_data['location'] = [[w2i[i] for i in str(x).split()] for x in train_data.location]train_data['text'] = [[w2i[i] for i in str(x).split()] for x in train_data.text]#print(train_data[:read_train.shape[0]])test_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in test_data.keyword]test_data['location'] = [[w2i[i] for i in str(x).split()] for x in test_data.location]test_data['text'] = [[w2i[i] for i in str(x).split()] for x in test_data.text]data_list=[]max_len=25for x in train_data.text:if len(x)>=max_len:x=x[0:max_len-1]while len(x)<max_len:x.append(0)data_list.append(x)eval_list=data_list[6000:]data_list=data_list[0:6000]eval_label=train_label[6000:]train_label=train_label[0:6000]print("datalabel len: ",len(data_list))print("evallabel len: ",len(eval_list))print("datalist len: ",len(data_list))print("evallist len: ",len(eval_list))print("datalen: ",len(data_list[0]))train_label=torch.tensor(train_label)eval_label=torch.tensor(eval_label)traindata_tensor = torch.Tensor(data_list)eval_tensor= torch.Tensor(eval_list)traindata_tensor = torch.Tensor(data_list)if USE_CUDA:print("using GPU")traindata_tensor =traindata_tensor.cuda()train_label = train_label.cuda()eval_tensor=eval_tensor.cuda()eval_label = eval_label.cuda()#print(a.shape)#train_data=torch.tensor(train_data[:read_train.shape[0]].values,dtype=torch.float)#print(train_data)#print (len(train_data.iloc[0]))'''输入数据格式:input(seq_len, batch, input_size)h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)输出数据格式:output(seq_len, batch, hidden_size * num_directions)hn(num_layers * num_directions, batch, hidden_size)cn(num_layers * num_directions, batch, hidden_size)'''class LSTMTagger(nn.Module):def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size,batch_size,str_len):super(LSTMTagger, self).__init__()self.hidden_dim = hidden_dimself.str_len=str_lenself.batch_size=batch_sizeself.word_embeddings = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim)self.dropout1 = nn.Dropout(0.5)self.dense= nn.Linear(str_len*hidden_dim, hidden_dim)self.op_prelu=nn.PReLU()self.dropout2 = nn.Dropout(0.5)self.hidden2tag=nn.Linear(hidden_dim, tagset_size)self.op_tanh=nn.Tanh()self.hidden = self.init_hidden()def init_hidden(self):if USE_CUDA:return (torch.zeros(1, self.batch_size, self.hidden_dim).cuda(),torch.zeros(1, self.batch_size, self.hidden_dim).cuda())else:return (torch.zeros(1, self.batch_size, self.hidden_dim),torch.zeros(1, self.batch_size, self.hidden_dim))def forward(self, sentence,state,train_flag):embeds = self.word_embeddings(sentence)#print(embeds.shape)self.hidden=statelstm_out, self.hidden = self.lstm(embeds.view(self.str_len, len(sentence), -1), self.hidden)#print("ls",lstm_out.shape)if train_flag:lstm_out=self.dropout1(lstm_out)tag_space = self.dense(lstm_out.view(self.batch_size,-1))tag_space=self.op_prelu(tag_space)if train_flag:tag_space=self.dropout2(tag_space)tag_space=self.hidden2tag(tag_space)tag_space=self.op_tanh(tag_space)#print(tag_space.shape)#tag_scores = F.log_softmax(tag_space,dim=1)return tag_space ,self.hiddendef out_put(net,batchsize):test_list = []max_len = 25i=0for x in test_data.text:if len(x) >= max_len:x = x[0:24]while len(x) < max_len:x.append(0)test_list.append(x)test_data_tensor = torch.Tensor(test_list)if USE_CUDA:print("using GPU to out")test_data_tensor = test_data_tensor.cuda()result=[]state = Nonewith torch.no_grad():result_dataset = torch.utils.data.TensorDataset(test_data_tensor)result_dataloader = torch.utils.data.DataLoader(result_dataset, batch_size=batchsize, shuffle=False)index=0for X in result_dataloader:X=X[0]#print(type(X))#print(X.shape)if state is not None:if isinstance(state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()if X.shape[0]!=batchsize:breakX = X.long()(output, state) = model(X, state,False)_, predicted = torch.max(output.data, 1)#print("predicttype",type(predicted))#print(predicted)temp=predicted.cpu().numpy()for i in temp:result.append(i)print(len(result))while len(result)<3263:result.append(0)df_output = pd.DataFrame()aux = pd.read_csv(base_path + 'test.csv')df_output['id'] = aux['id']df_output['target'] = resultdf_output[['id', 'target']].to_csv(base_path + 's1mple.csv', index=False)print("reset the result csv")def eval(net,eval_data, eval_label,batch_size,pre):net.eval()print("enter",net.state_dict()["hidden2tag.bias"])dataset = torch.utils.data.TensorDataset(eval_data, eval_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=False)total=0correct=0state=Nonewith torch.no_grad():index = 0for X, y in train_iter:X = X.long()if X.size(0)!= batch_size:breakif state is not None:if isinstance(state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()(output, state) = model(X, state,False)_, predicted = torch.max(output.data, 1)total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = (((1.0*correct.numpy())/total))print("right",correct,"total",total,"Test Acc:",s)if s>pre:print("flush the result csv ")out_put(net,batch_size)return sdef train(net, train_data, train_label,eval_tensor,eval_label,num_epochs, learning_rate, batch_size):net.train()state = Noneloss_fct = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0)dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)pre=0for epoch in range(num_epochs):correct = 0total=0iter = 0net.train()start = time.time()for X, y in train_iter:iter += 1X = X.long()if X.size(0)!= batch_size:breakif state is not None:if isinstance (state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()optimizer.zero_grad()#print(type(y))#print(y)(output, state) = net(X, state,True)loss = loss_fct(output.view(-1, 2), y.view(-1))_, predicted = torch.max(output.data, 1)loss.backward()optimizer.step()total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = ("Acc:%.3f" %((1.0*correct.numpy())/total))if iter %50==0:print("epoch ", str(epoch)," loss: ", loss.mean(),"right", correct, "total", total, "Train Acc:", s)torch.save(net.state_dict(), 'LSTMmodel.pth')print("before",net.state_dict()["hidden2tag.bias"])pre=eval(net,eval_tensor, eval_label,batch_size,pre)return#def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size,batch_size,str_len):embedding_dim=300hidden_dim=256vocab_size=len(dict)target=2Batchsize=16stringlen=25Epoch=20lr=0.005model = LSTMTagger(embedding_dim, hidden_dim, vocab_size,target,Batchsize,stringlen)if USE_CUDA:model=model.cuda()print(model)"""for param in net.parameters():nn.init.normal_(param, mean=0, std=0.01)""""""for name,parameters in model.named_parameters():print(name,':',parameters.size())"""train(model,traindata_tensor,train_label,eval_tensor,eval_label,Epoch,lr,Batchsize)
结果
本地训练
15epoch时达到峰值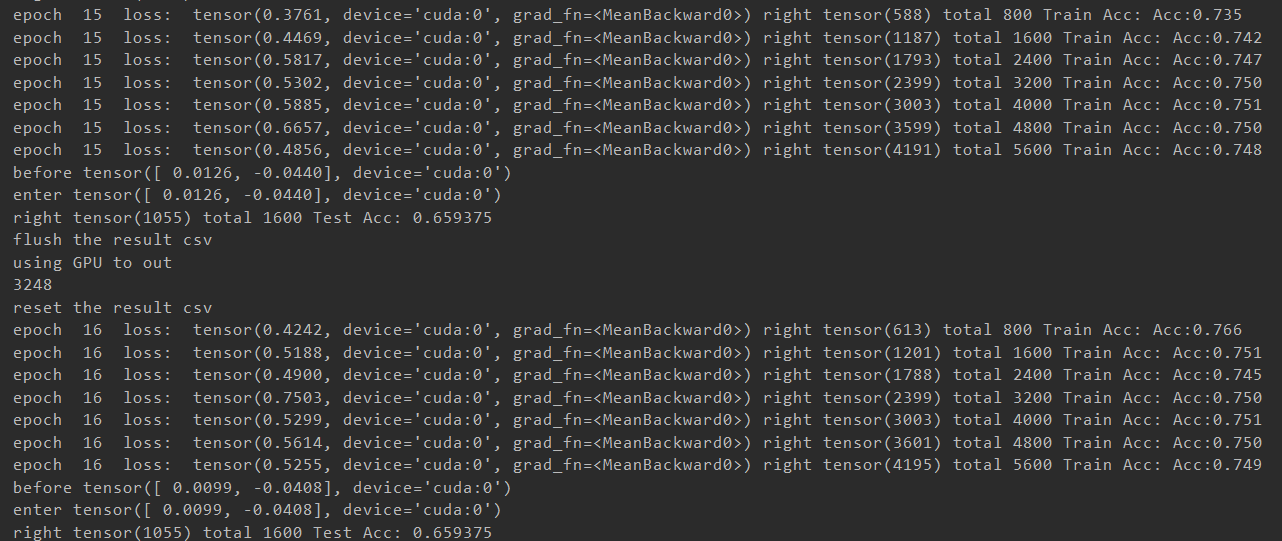
在线跑分
虽然比不上bert
但是也比原来的好多了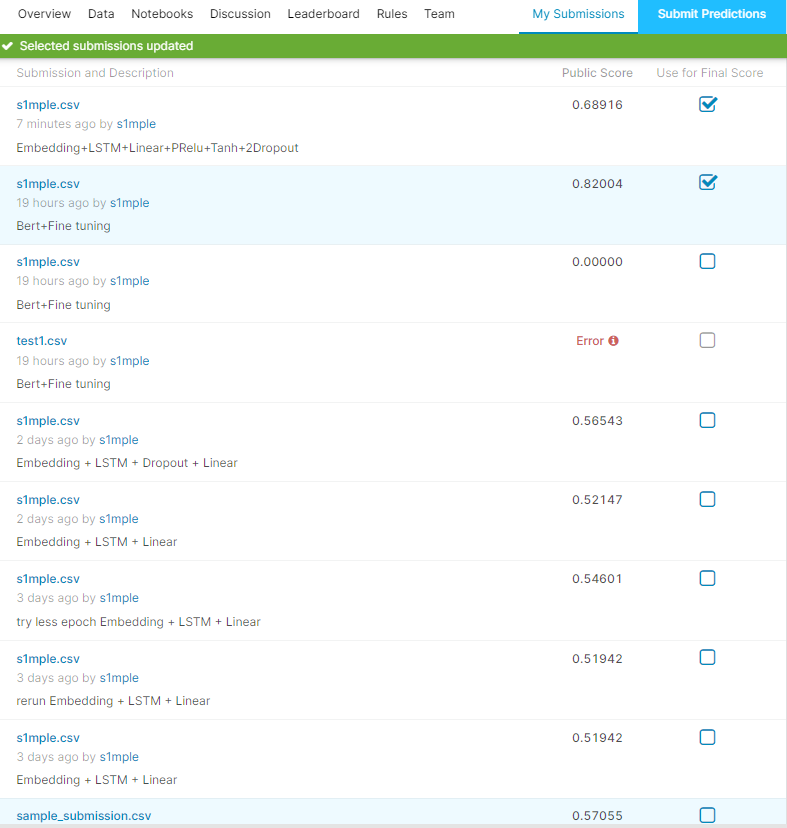

若有收获,就点个赞吧
0 人点赞
