Model
图构造
模型的基本理念就是输入原文,把原文转化为一个图
图的基本结构:
Concept:原文的命名实体,concept之间存在关系,我的理解是concept是文档之间的联系
基本组织:一个Action,Action有着对应的attribute描述
- Actor
- Receiver
- Time
- Location
本质就是一个事件,有着发起人,接受人,时间,地点
然后在event之间存在关系,包括导致,原因,条件,含义,序列等等的关系种类
最后得到一个ESLN网络图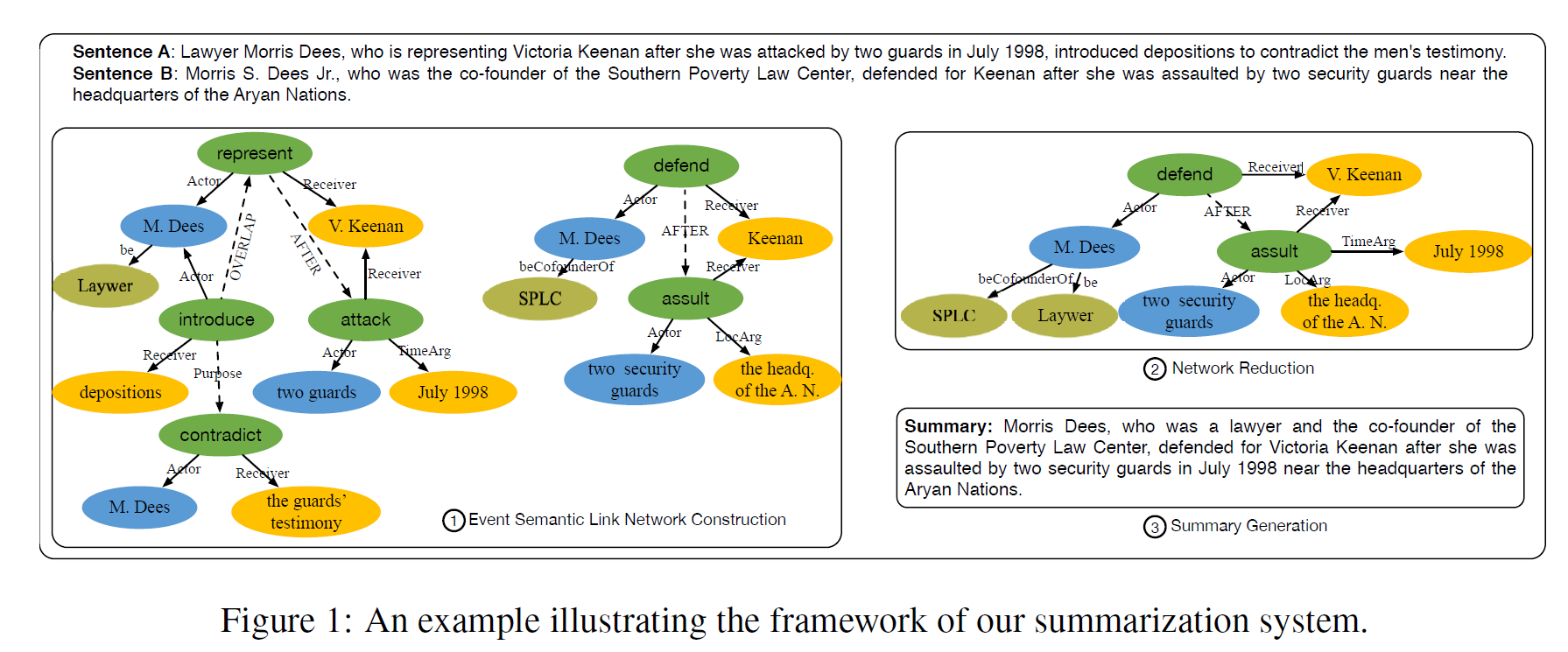
图修改
得到了一个图来表示原文之后,下一步就是对图进行剪切得到缩略图
使用的方法是特征工程那样对信息打分,选择event节点和concept节点,同时应用了一些规则限制如:
- 选了某个event就跟着选event的argument(actor等信息)
- 还有比如选择的子图应该是要联通的,用来Flow-base方法


摘要生成
摘要生成就是基于上面已经被裁剪后的图
生成方式我的理解就是用模板的方法,因为之前的图已经是结构化的数据
可以为不同种类的节点构造模板生成对应的句子
然后本论文的另一个点就是他生成了很多个候选的句子,然后贪心的选择
候选的摘要句子由上述的节点和对应的模板生成
最后选择的时候选择语言条件最好的,然后删除内容重复的节点生成的句子
这个选择的策略是:利用在大语料上训练的3-gram概率分布
我的理解就是这个句子如果3-gram更加符合语料分布说明句子更通顺,质量更好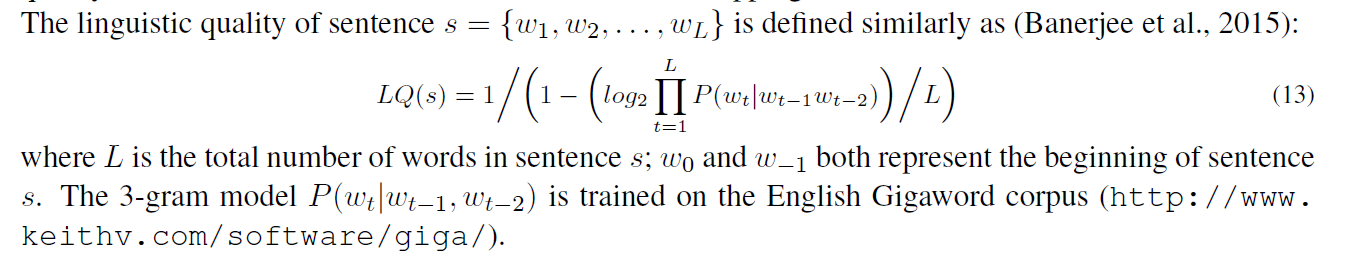
优点
- 由于用图结构,同时在实体之间融合操作,使得摘要的信息可以来自不同的位置
- 前面生成图的约束规则使得摘要更加的连贯和一致
- 这种图结构使得对实体的描述更加清晰
- 语法错误少一些,因为有大量生成和最后3-gram的选择操作

若有收获,就点个赞吧
0 人点赞
