Insight
对话摘要需要抽取出很多的辅助知识,去建模
很多先前的方法使用的都是公开的工具包,对于对话的类型不大适合
使用PTM是一个很好的思路来抽取
solution
使用pretrain model做一些标注工作
用的是DiaGPT,基于GPT在大规模的对话语料上做的一个模型。语料是类似于论坛的那种对话语料,所以就是一个一个的pair。
做法如下:
- 处理对话为DiaGPT的格式,抹去对话人,后面加上EOS分割
- 利用Context生成Response,计算每一个token的loss以及整个句子的loss(token avg)
- 同理运行,获取每一个EOS位置的表示(认为是对话句子的整体表示,和BERT的CLS一样的道理)
- 开始处理标注
- 高loss的token是Keyword
- 高loss的句子是new topic的开始位置
- 从后向前计算两两EOS的相似度,相似度太高的后一个EOS对话标注为冗余
然后就是用一些Special token表示一下标注结果,然后用BART或者PGN跑就行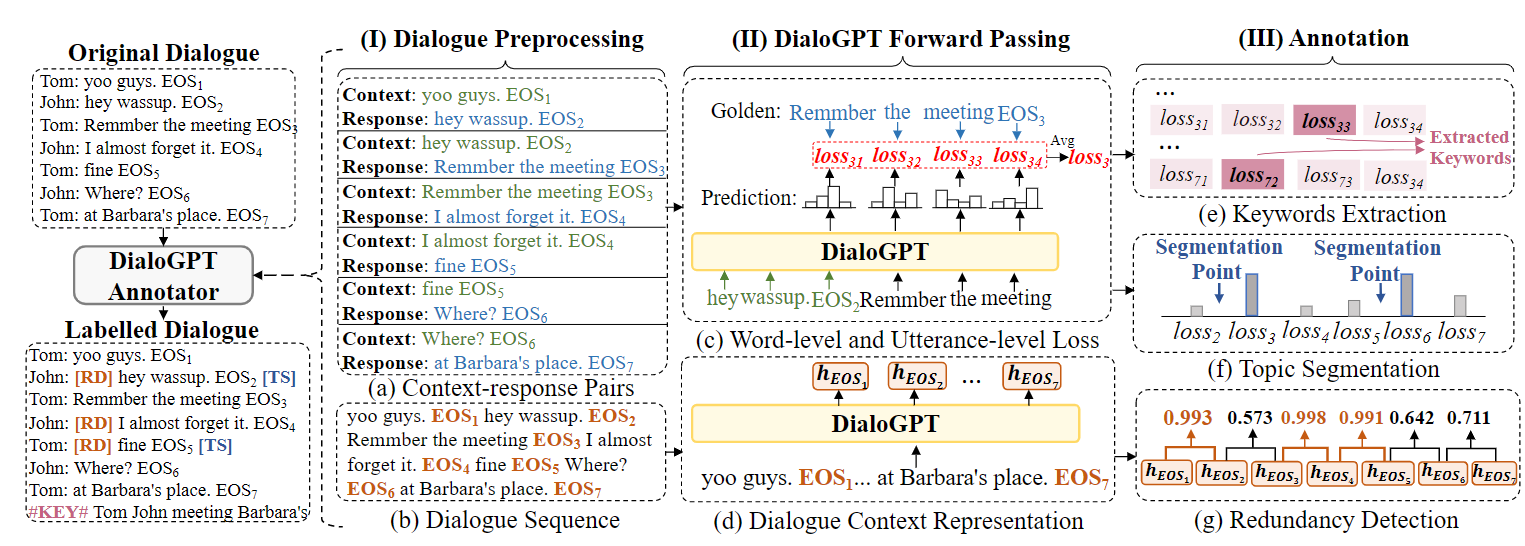
Highlight
这里的annotate并不是直接去训练一个模型,然后把模型的结果作为标注
而是相反的,把模型不fine-tuing,而是把模型做的不好的地方作为进一步的信号
比如说,预测下文的时候,loss大的反而是需要上下文才能够做好的数据,是比较富含有信息的,作为关键词。
同理,在句子的loss比较大的作为Topic开始的位置,取相似度作为冗余的检测
这一些做法相对的更有创新性了,和先前的一些直接用模型作为标注的思路并不一样
对于关键词,我感觉还有一个解释就是,可能是对不好学习的数据进行强调
因为从之前的论文我们可以知道,PTM可以做的比较好的一般都是copy过来的简单样本,对于Dialog不能够做好的样本可能就是一个难样本,对难样本认为是“关键词”进行强调,进而增加了性能是完全可以理解的

若有收获,就点个赞吧
0 人点赞
