NLTK入门
首先使用pip install 安装库,随后安装语料包。可以使用如下代码
import nltknltk.download()
没开梯子0下载量,开了梯子也卡的不行,直接下载本地包进行安装
https://blog.csdn.net/Csharp289637169/article/details/54344260
下载之后的放哪里?可以使用代码进行尝试运行,报错信息会给出语料包搜索路径,选一个放置即可
from nltk.corpus import brownprint(brown.categories())
至此已经配置完成,尝试运行第一个简单的程序
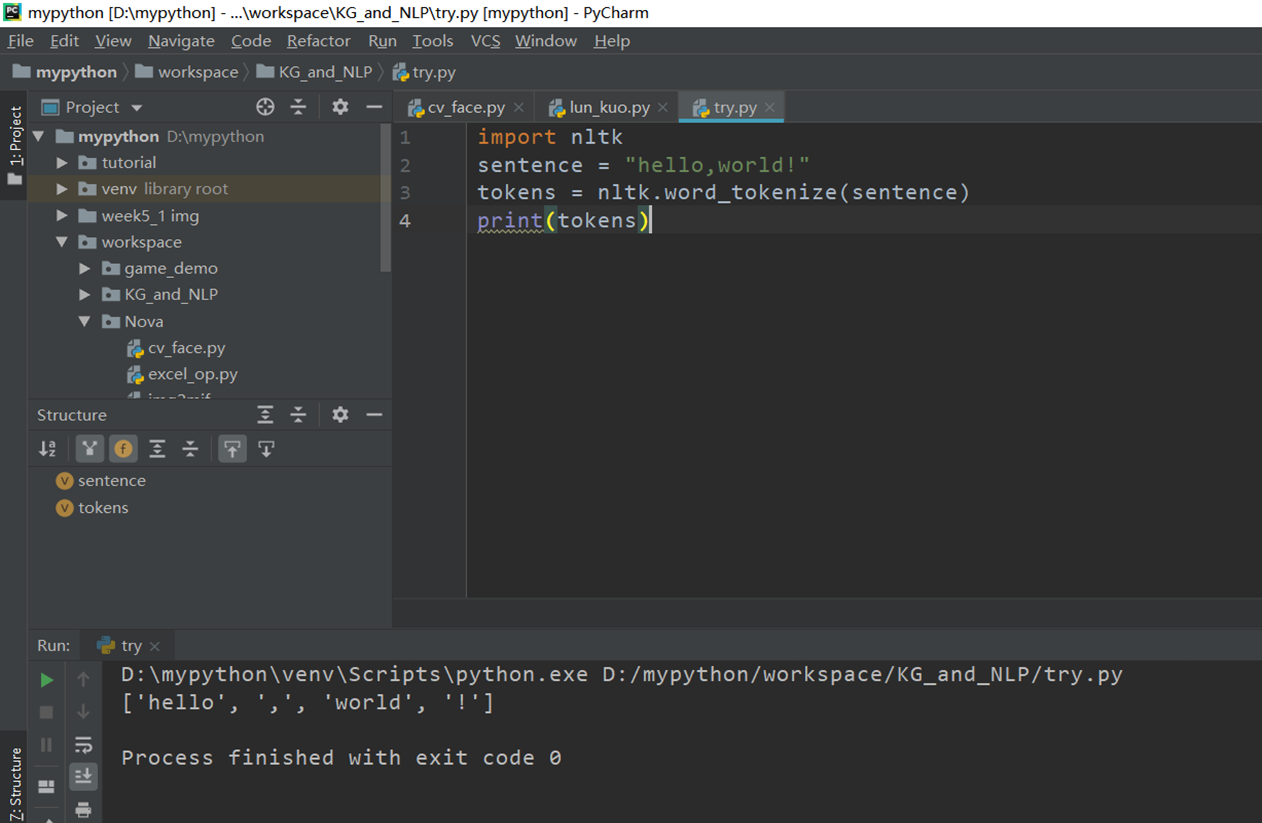
随后开始从尝试统计词频
import nltkimport stringfrom nltk.corpus import stopwordsimport nltk.stemsentence="hello world"f = Nonetry:f = open("D:\\New_desktop\\Alice_s_Adventures_in_Wonderland_057\\Alice's Adventures in Wonderland - Lewis Carroll.txt", 'r', encoding='utf-8')sentence=f.read()except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')finally:if f:f.close()lower = sentence.lower()remove = str.maketrans('','',string.punctuation)without_punctuation = lower.translate(remove)print(without_punctuation)tokens = nltk.word_tokenize(without_punctuation)without_stopwords = [w for w in tokens if not w in stopwords.words('english')]s = nltk.stem.SnowballStemmer('english') #参数是选择的语言cleaned_text = [s.stem(ws) for ws in without_stopwords]print(cleaned_text)freq = nltk.FreqDist(cleaned_text)freq.plot(50, cumulative=False)for key,val in freq.items():print (str(key) + ':' + str(val))
统计的结果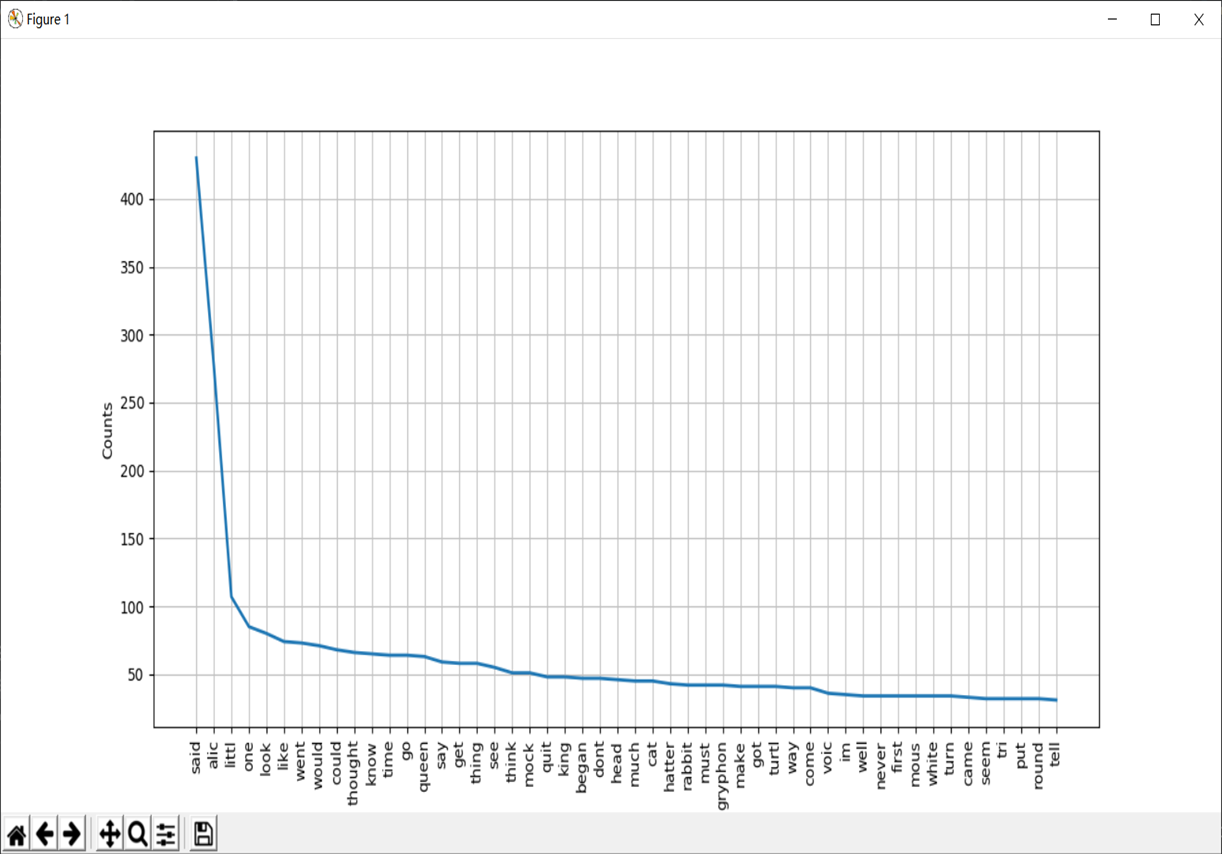
最后附上测试用的各种数据源
123.txt12.txtJane Eyre - Charlotte Bronte.txt

若有收获,就点个赞吧
0 人点赞
