Insight & target problem
全fine-tuing耗时间
Adaptor还是效果不好,而且要tuing的参数更多
Solution
对于自回归模型,加入前缀后的模型输入表示: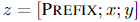
对于编解码器结构的模型,加入前缀后的模型输入表示: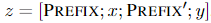
本文构造一个矩阵 ![21.11.26 Prefix-Tuning: Optimizing Continuous Prompts for Generation [ACL2021] - 图3](/uploads/projects/kevinpro@kevinpro.nlp/c510d576dced3e04fbffc1923332a835.svg) (
( ![21.11.26 Prefix-Tuning: Optimizing Continuous Prompts for Generation [ACL2021] - 图4](/uploads/projects/kevinpro@kevinpro.nlp/ecce49cc3fd49f12ccffeb3e208a3608.svg) )去存储前缀参数,该前缀是自由参数。
)去存储前缀参数,该前缀是自由参数。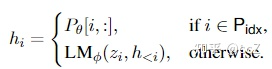
目标函数依旧是公式(2),但是语言模型的参数是固定的,只更新前缀参数。
除此之外,作者发现直接更新前缀参数会出现不稳定的情况,甚至模型表现还有轻微的下降,因此作者对前缀参数矩阵进行重参数化: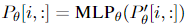
其中 ![21.11.26 Prefix-Tuning: Optimizing Continuous Prompts for Generation [ACL2021] - 图7](/uploads/projects/kevinpro@kevinpro.nlp/e7f1d365955f58dc3b06c57945d13566.svg) 在第二维的维数要比
在第二维的维数要比![21.11.26 Prefix-Tuning: Optimizing Continuous Prompts for Generation [ACL2021] - 图8](/uploads/projects/kevinpro@kevinpro.nlp/8cb0486166bb3df3fa1c012370e7288d.svg) 小,然后经过一个扩大维数的MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留
小,然后经过一个扩大维数的MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留![21.11.26 Prefix-Tuning: Optimizing Continuous Prompts for Generation [ACL2021] - 图9](/uploads/projects/kevinpro@kevinpro.nlp/d35c6e2da3576c2bac946e15b55c578b.svg) 。
。
Highlight
微调的参数更少了
效果还不错
- 低资源很不错
- 跨领域也不错
在摘要上表现的比较差
- 摘要更长
- 摘要数据更多
最后探讨了优点:
- 对于工业界来说,对每一个用户都tuing一个模型不可能,但是单独tuing一个prompt是可以的
- 对于不同用户进入企业云端GPU的时候,不同用户可以只要PrePend Prompt,然后可以打包在一个Batch里送进GPU,Adaptor就不行,因为每一个用户的模型不同
- Prompt最大可能的保留了模型的pretrain后的样子,使得模型的泛化性更强
Others
对比:Deep Continuous Prompt:一般直觉的做法是在词嵌入层,把离散的token变成可训练的virtual token,这样可训练的参数虽然最少,但是效果肯定没有在每一层都加入可微调的参数更好。所以这篇是在每层都加入了可训练的参数,优化的时候就是优化所有层的前缀。
每一层都加的效果显著好于只在输入层
对比2:Prefix好于Infix,即 prefix X Y好于X infix Y (因为编码X的时候也有受Prefix影响)
对比3:prefix的长度有影响,有一个位置最好

若有收获,就点个赞吧
0 人点赞
