这一篇论文主要是对模型训练时期的一些行为进行分析,研究的对象是”Abstractive抽象性“和”Factual 事实正确性“(抽象性指的是生成摘要能够产生和Source input不一样的一些表达词语,达到改写)
主要的思想:
利用source和summary的N-gram重合度表示abstractive的程度(越低重复代表越高的新词生成)
- 模型不管怎么训练都做不到reference的新词生成能力(抽象性)
- 模型一开始的重合度很高,作者认为模型一开始很快的学会了copy来完成一些简单的样本(简单的样本指的是和原文重合度很高的样本)
- 然后模型开始去拟合那些比较困难的样本(对应的困难指的是有比较多新词发现的样本),在拟合的过程里提升了ROUGE,但是对应的丢失了事实正确性。
- 生成错误的样本token的时候,模型给的概率比较低(这个和之前的对比学习改进事实正确性的论文的结论一致,那一篇论文用置信度来生成错误样本进行对比学习)
总结一下:模型过早的学会了copy,此时ROUGE不够好,但是copy了原文,事实正确性不错。后面开始生成新词,但是这个时候丢失了事实正确性。前期过拟合了简单样本,后期过度追求难样本。
下面是在三个数据集上的不同样本的表现,蓝色的是低overlap的难样本,红色则相反。
可以看到在CNNDM这种比较偏向于抽取式的数据集,模型很快在红色样本上具有了高概率输出,代表了已经很好很自信的copy输出。对于蓝色样本则不愠不火的缓慢增长。Xsum这种抽象度比较高的数据集这个现象稍微不明显。证明了上面提到的简单样本过早Overfit,然后逐步优化难样本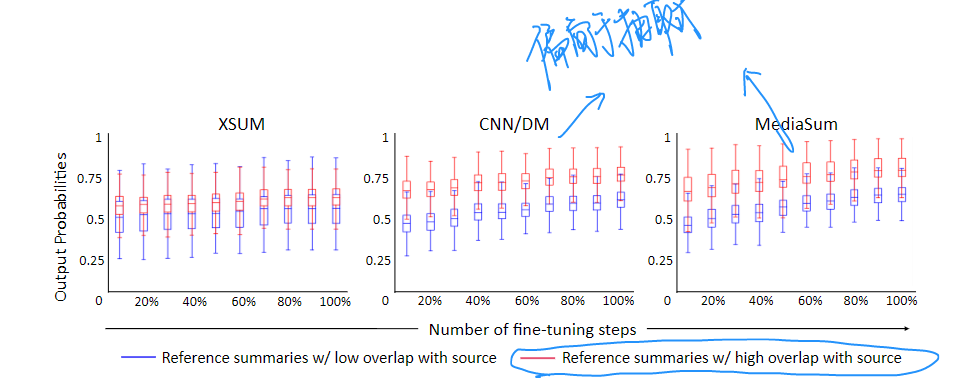
下图是训练过程里,模型在三个数据集上的N-gram OverLap变化,可以看到一开始的Overlap几乎100%,然后模型开始学习选择输出(copy部分),再到后面小幅度的下降(开始学会新词的产生)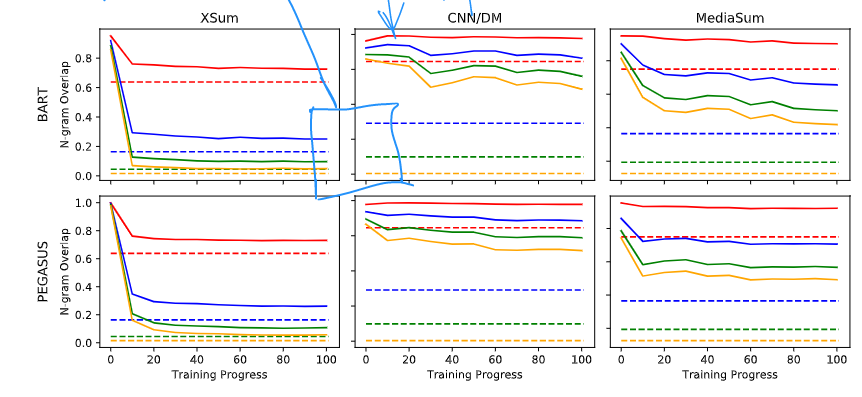
基于上述结论,作者做了实验,先正常训练30%的迭代步数,然后在后面的70%的迭代对Loss进行裁剪。两种策略代表了两种偏好
- 策略1:迭代了30%之后的低loss表示这是一个简单的token,没有必要过度优化,直接丢弃。
- 策略2:相反的,高loss代表这是一个难样本,很难生成,过度的追求这个样本会导致事实正确性下降。
相当于是在事实正确性和Abstractive(其实我感觉Abstractive和ROUGE差不多,毕竟训练到一定程度之后,只有生成新词才能进一步提升ROUGE了)做了一个取舍。

若有收获,就点个赞吧
0 人点赞
