Insight & target problem
很多模型很难做到同时faithful和diverse
Solution
用一个额外的对齐方法
对每一个source token的编码,都在vocabulary上计算相似度。
这个相似度和Source-Target的Attention加权之后加到decoder阶段的概率分布上
这样就保证了和原文token相似相关的词语的概率会更大一些。加强了一致性和faithful
然后是topic相关,使用如下公式,我的理解是查找整个词表,如果对齐概率的这个词在Y里,加大,反之减小
比如Source : A,B,C。 Target:A
那么Ha和Ea的概率要大,Ha和Eb,Ec的相似度要小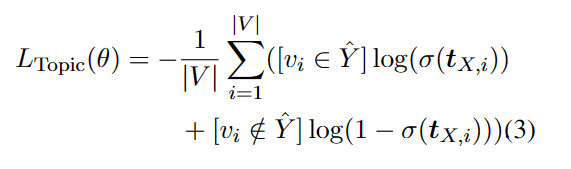
最后是sampling技术
F应该是类似停用词连词这种在所有文章里都出现的,Vk是从V里采样(根据相似度的大小),在这样的集合里用概率来采样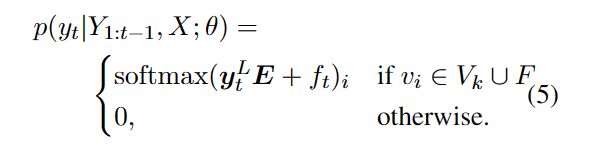
Highlight
Others

若有收获,就点个赞吧
0 人点赞
