Insight & target problem
现存的用NLI思路来解决consistency问题的方法,都有一些问题,因为NLI是一个句子级别的任务,但是Consistency是一个Document2Document的任务
Solution
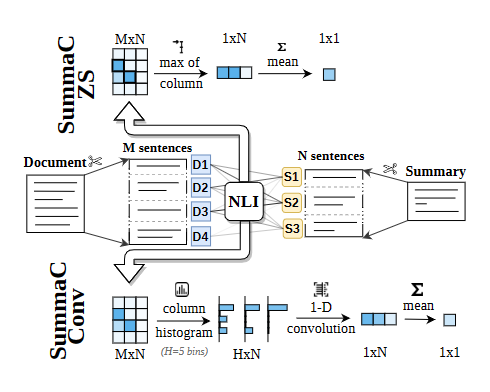
把文档和摘要都进行按照句子级别的划分,然后在这个句子级别的pair上用NLI模型计算概率,得到一个矩阵
然后是聚合算法
- 先对矩阵的行做max,然后对一行概率做min
- 先把概率转化到档位,然后用卷积网络处理为一个概率
一些实验结果没啥惊喜的,略过
Highlight
然后还有一个探究划分粒度的实验
可以看到用Sentence,或者是2-Sentence的效果比较好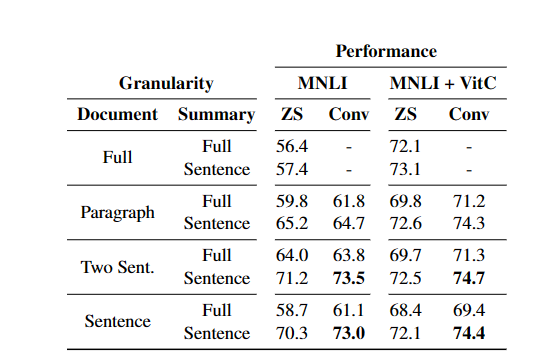
Others
- 提升NLI模型
- 提高可解释性
- 数据集领域拓展(现在的都是新闻)
- 现在能够检测错误了,如何改正?

若有收获,就点个赞吧
0 人点赞
