经验
https://www.zhihu.com/question/41631631
- 可考虑设置batchsize=1
- dropout是神经网络中最有效的正则化方法;
- 传统的dropout在rnn中效果不是很好;dropout在rnn中使用的效果不是很好,因为rnn有放大噪音的功能,所以会反过来伤害模型的学习能力;
- 在rnn中使用dropout要放在时间步的连接上,即cell与cell之间传递,而不是神经元;对于rnn的部分不进行dropout,也就是说从t-1时候的状态传递到t时刻进行计算时,这个中间不进行memory的dropout;仅在同一个t时刻中,多层cell之间传递信息的时候进行dropout
- Dropout在LSTM中https://lonepatient.top/2018/09/24/a-review-of-dropout-as-applied-to-rnns.html
已有的参数
- 句子截断长度,平均的句子有7个单词,截断设为10,32的时候效果奇差,设为25的时候有较好的效果
- 学习率为1过大,直接不学习
调参结果
1.修改similarity计算
embedding_dim=400hidden_dim=256vocab_size=51158target=1Batchsize=256stringlen=25Epoch=20lr=0.1
similarity=(F.pairwise_distance(tag_spacea, tag_spaceb, p=2)) # pytorch求欧氏距离similarity=similarity.view(-1,1)
similarity=-similarity
similarity=torch.exp(similarity, out=None)
similarity=similarity.float()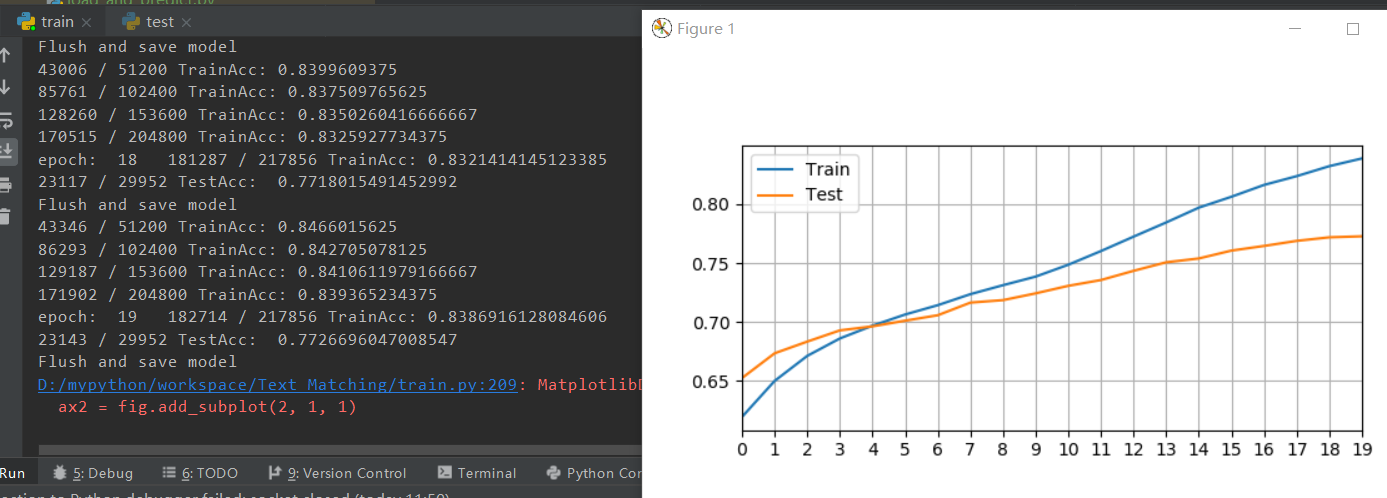
2.初始化向量
initrange = 0.5 / embeddingdim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.word_embeddings.weight.data.uniform(-initrange, initrange)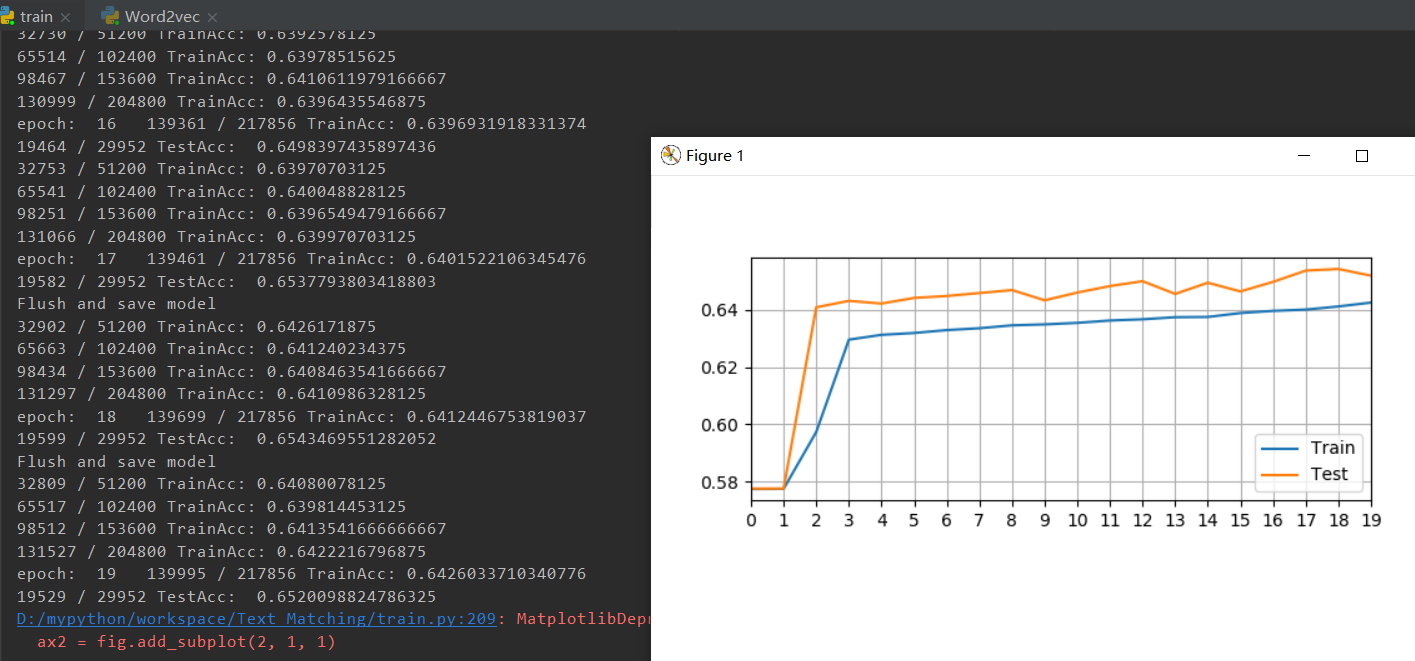

若有收获,就点个赞吧
0 人点赞
