这篇论文主要是利用人称信息来做
概述
希望解决两个问题
- 首先摘要存在的事实不正确,人称等问题
- 现存的所有模型都是从一个第三方的角度做的,摘要希望有一个侧重视角的工作(比如说客服和消费者,从一个消费者的角度)
利用在头部的一个串来注入人称
那这个注入存在一些策略
- 在训练阶段,使用Golden Summary和Source Dialogue的人称的并集作为Entity List(最全)
- 在测试阶段
- 用于分析,使用和训练阶段一样的策略(当然这实际上是不行的,仅仅在分析阶段作为上界)
- 使用Global的,即所有Source里的
- 使用某一个人的,Focus View
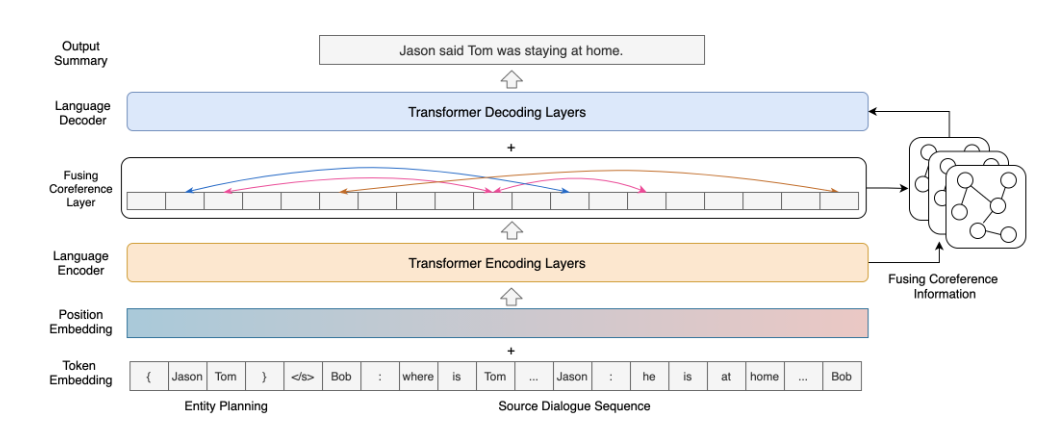
经过Transformer Encoder,然后利用Spanbert获取的多个Cluster(同指代为一个Cluster)
在Cluster里建立双向边。

效果
这篇论文的效果好的离谱。。。不过为啥他的Baseline辣么高?后面的一些结果更离谱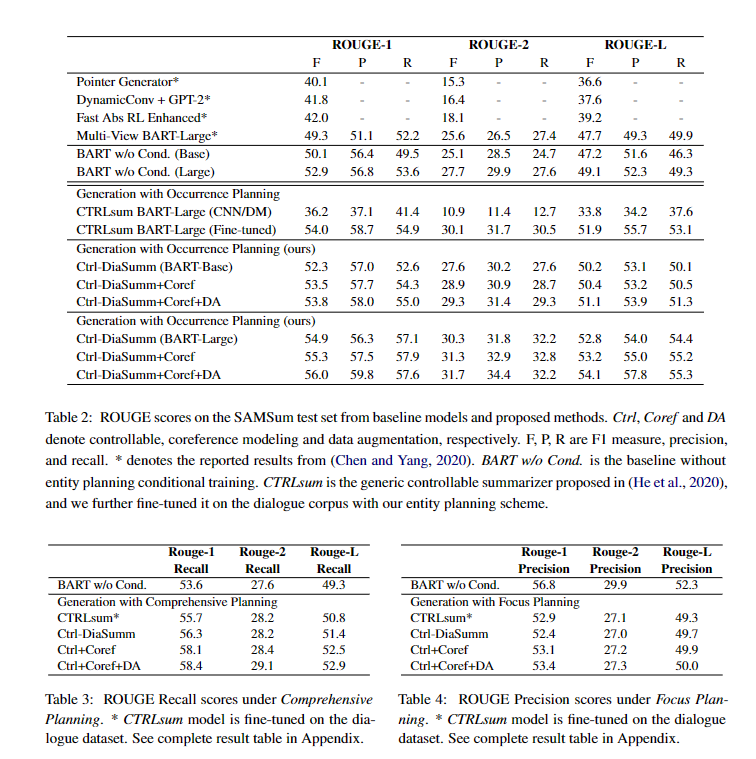
分析
分析的话,有意思的是,他先训练了一个判别器
利用自动构造出正例和负例,正例就是Golden Summary,反例就是调换位置,修改名字等等
然后用BERT做一个分类,居然,分类可以达到91%的F1
然后后面用这个做质量评估就好。
里面还有一个CTRLSum,不知道是啥玩意儿,后面会再看看

若有收获,就点个赞吧
0 人点赞
