引入了新的数据DuIE进行重新训练
使用脚本对数据的格式进行转化
对测试数据的转化见先前
import jsondef find_all(sub, s):index_list = []index = s.find(sub)while index != -1:index_list.append([index,index+len(sub)-1])index = s.find(sub, index + 1)if len(index_list) > 0:return index_listelse:#print("err")return index_list#sen="生生不息CSOL生化狂潮让你填弹狂扫"#print(find_all("CSOL",sen))def func1():with open("D:\\New_desktop\\train_data.json", 'r', encoding='utf-8') as load_f:labels = {}info=[]error=0total=0l=['机构', '影视作品', '电视综艺', '网络小说', '歌曲', '生物', '历史人物', '人物', '图书作品', '学校', '音乐专辑', '企业', '书籍', '国家', '出版社', '目', '地点']for i in l:labels[i]=0import randomfor line in load_f.readlines():total+=1dic = json.loads(line)after={}after['text']=dic['text']after['label'] = {}append_flag=1for j in dic['spo_list']:if j['object_type'] in l:labels[j['object_type']]+=1after['label'][j['object_type']] = {}result1 = find_all(j['object'], dic['text'])if len(result1) != 0:after['label'][j['object_type']][j['object']] = find_all(j['object'], dic['text'])else:append_flag = 0else:append_flag=0if j['subject_type'] in l:labels[j['subject_type']] += 1after['label'][j['subject_type']]={}result2=find_all(j['subject'], dic['text'])if (len(result2))!=0:after['label'][j['subject_type']][j['subject']] =find_all(j['subject'], dic['text'])else:append_flag=0else:append_flag=0if append_flag:info.append(after)sub_train = []for i in range(20000):sub_train.append(random.choice(info))print(len(info),total)with open("D:\\New_desktop\\train.json", "w",encoding='utf-8') as dump_f:for i in sub_train:a = json.dumps(i, ensure_ascii=False)dump_f.write(a)dump_f.write("\n")with open("D:\\New_desktop\\dev_data.json", 'r', encoding='utf-8') as load_f:labels2 = {}for i in l:labels2[i] = 0info=[]error=0total=0for line in load_f.readlines():total += 1dic = json.loads(line)after = {}after['text'] = dic['text']append_flag = 1after['label'] = {}for j in dic['spo_list']:if j['object_type'] in l:labels2[j['object_type']] += 1after['label'][j['object_type']] = {}result1 = find_all(j['object'], dic['text'])if len(result1) != 0:after['label'][j['object_type']][j['object']] = find_all(j['object'], dic['text'])else:append_flag = 0else:append_flag = 0if j['subject_type'] in l:labels2[j['subject_type']] += 1after['label'][j['subject_type']] = {}result2 = find_all(j['subject'], dic['text'])if (len(result2)) != 0:after['label'][j['subject_type']][j['subject']] = find_all(j['subject'], dic['text'])else:append_flag = 0else:append_flag = 0if append_flag:info.append(after)print(len(info),total)for i in labels:print(i, labels[i],labels2[i])sub_info=[]for i in range(2000):sub_info.append(random.choice(info))with open("D:\\New_desktop\\dev.json", "w",encoding='utf-8') as dump_f:for i in sub_info:a = json.dumps(i, ensure_ascii=False)dump_f.write(a)dump_f.write("\n")func1()
数据特性
共计28类的数据
观察到部分的类别的数量极度的不平衡
对应的结果发现有很大的偏差,或许是因为这个原因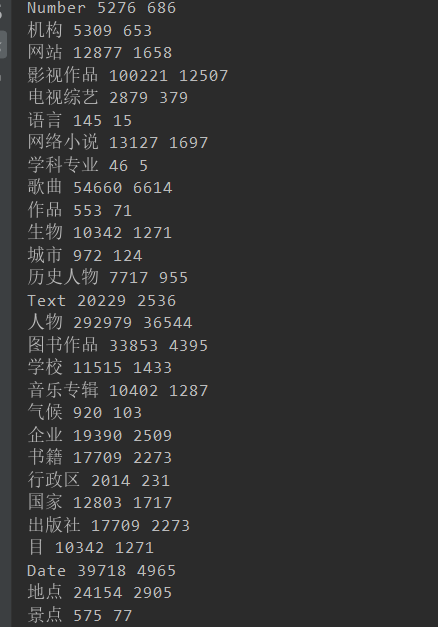
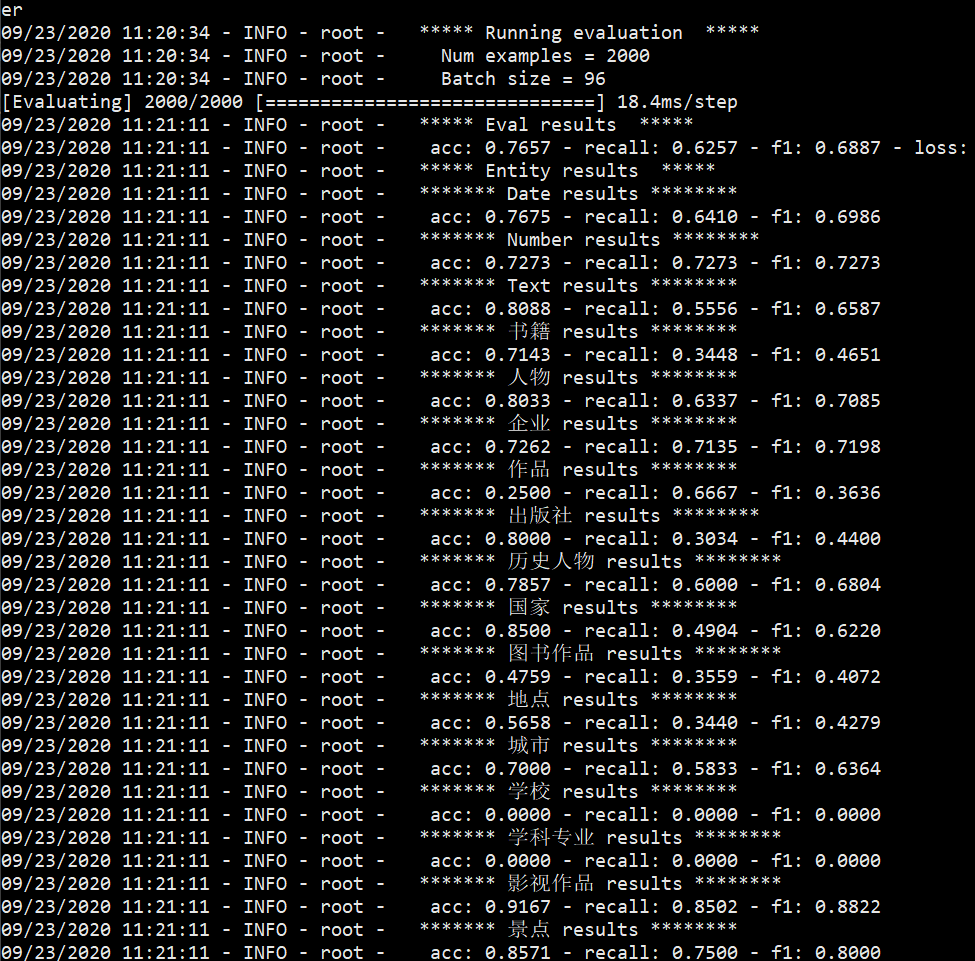
解决方案
对应的对类别进行了裁剪
对应的多分类问题里,类别过多以及类别的数据量差异极大的影响了算法性能,因此对数据进行修剪得到新数据
- ‘机构’,
- ‘影视作品’,
- ‘电视综艺’,
- 网络小说’,
- ‘歌曲’,
- ‘生物’,
- 历史人物’,
- 人物’,
- ‘图书作品’,
- ‘学校’, ‘
- 音乐专辑’,
- ‘企业’,
- ‘书籍’,
- ‘国家’,
- ‘出版社’,
- ‘目’,
- 地点’
同时由于先前的数据量过大(17w+ 的Train以及 2w+的dev)
进行缩小至2w的train以及2k的dev
随后得到数据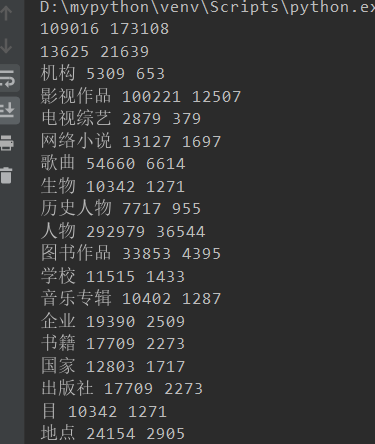
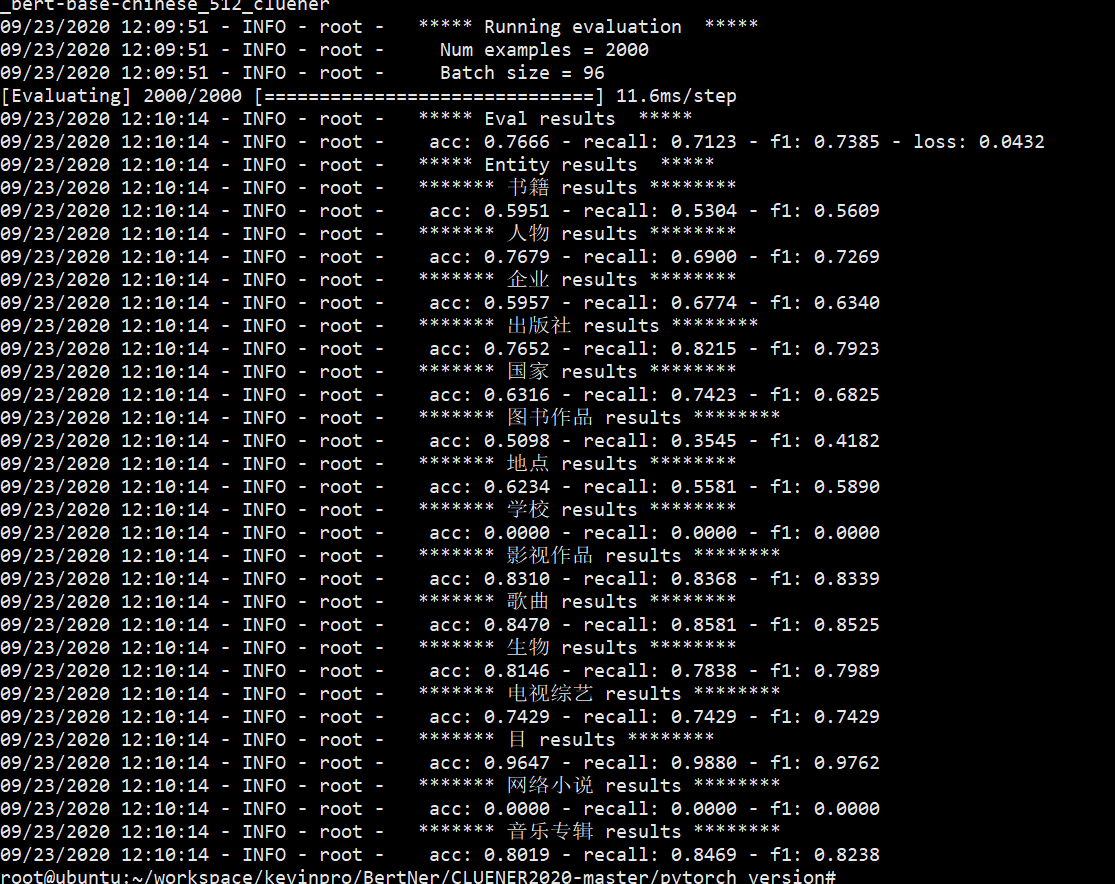
实际测试


若有收获,就点个赞吧
0 人点赞
