早期的把预训练模型作为外部信息输入的方法过于浅层和简单,单独训练并加入实体(entity)的embedding的方法过于独立,收益甚小,因此提出CoLAKE模型,把上下文信息和外部信息联合(joint)训练,提出了一种新的数据结构,效果不错
早期方法
- 单独训练entity表示向量,用的时候fix。显然把上下文语义信息和外部信息割裂开
- 单独的只是用entity embedding强化预训练模型,无法完全捕获实体在上下文里的信息表示,同时之前训练的entity embedding质量极大影响后续的使用
- 固定的实体表示,新的实体加入使得原来的训练结果都无效了
新模型如下:word-knowledge graph (WK graph).
- 把原句子表示出来为基本图
- 原句子里的实体变为锚点,通过关系向外联结拓展子图
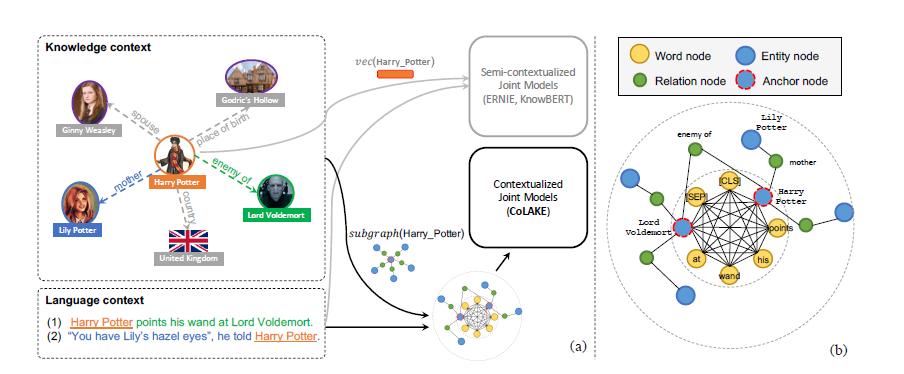
优点:
- 优秀的数据结构,同时接受Sentence input和外部知识输入
- 同时学习实体等外部知识和上下文
- 使用MLM对CoLAKE pretrain,作为一个便于拓展的pretrained GNN
上述的GNN又被改造拉直到普通的Transformer接受的形状,并完成MLM pretrain
改造有
- 三种Embedding相加
- 对于关系和外部联结实体(外部游离的节点)使用了soft-position index也映射到了一个Position Embedding上(这里引用了一个20年的东西,不太清楚具体原理,对应的上图Position 右半部分的2,3,2,3,2序列
其他的细节还有很多没有听说过的Trick
- CPU-GPU联合训练,共享内存
- 负例采样和3/4次方(我觉得这里用的和Skip-Gram一样的trick策略)
实验主要是预测实体类别,预测关系,知识探针(从预训练模型看看他含有多少事实信息,比如预测mask,能够预测出说明预训练模型含有这个信息),语言理解(GLUE),以及WK图补全(预测关系,分为给定两个实体和给定一个实体以及另一个实体的邻居两种)
我的理解就是主要围绕两部分
- 模型预训练后到底含有多少信息(不需微调就能够完成一些任务)
- 模型根据有限的上下文和外部信息能够抽取到多少有用的信息用于完成后续任务

若有收获,就点个赞吧
0 人点赞
