Text Summarization Techniques A Brief Survey
在NJU的NLP夏令营从事文本生成方向的项目
这里对基本的概述生成论文阅读笔记
Part1
利用词频等计算权重
- 关键词 cue word在句子里出现权重和
- 标题 标题里的词在句子里出现权重和
- 位置 在段首和文章头部的句子相关性更高
抽取式和启发式的概述生成
启发式限于自然语言处理技术和语义表达有难度
抽取式数据驱动简单一些
Part2
抽取式
- 构造中间表达
- 基于表达评分
- 选择句子
两种办法
- Topic representation
- indicator representation.
打分
topic打分表现了句子对主题的表达情况
indicate就是用feature(如句子长度,位置等)计算。这种feature的weight是可学习的
选句子
贪心算法,最大化重要性和凝聚性,最小化冗余
Part3
Frequency-driven Approaches
基于词频的方法
- Word probability
- TF-IDF
Word probability
第一种方案简单的概述就是
对每一个词计算词频
对应的句子权重就是词频的平均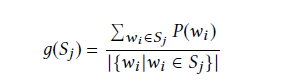
然后选中最高频的词,在含有这些词的句子中选中最高权的句子
对句子里的所有词做权重更新,就是旧的权重的平方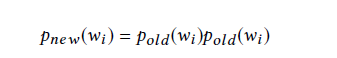
重复上述工作直到选够自己要的句子数
TF-IDF
对于词频计算需要摒弃Stop Word,但是怎么确立这个Stop Word List是个问题
所以有了TF-IDF既能算权重又能识别StopWord
D是文档数目,fD(w)是由w的文档数目
我的理解就是如果每一篇都有w那就趋近于1,log的结果就趋近于0,从而实现了对StopWord赋予低权重的思路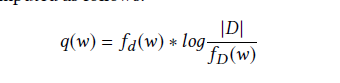
基于TF-IDF的算法:Centroid-based summarization
计算TF-IDF,每一个文章有了TF-IDF向量
去掉阈值过低的词汇,然后一系列的算法作用于TF-IDF向量,把文章加入集合并重新计算中心值
用中心值判断句子是否概述文章主题,引入了
two metrics are defined [54]: cluster-based relative utility(CBRU) and cross-sentence informational subsumption (CSIS). CBRU decides howrelevant a particular sentence is to the general topic of the entire cluster and CSIS measure redundancy among sentences.

Latent Semantic Analysis
构造n*m的矩阵,n是词汇数,m是句子数,填充值就是TF-IDF计算结果。词不在句子里填充0.
然后做SVD矩阵分解 利用D=ΣV(T) 描述句子代表主题的程度。d[i][j] 在句子j 中显示主题i 的权重。
利用D=ΣV(T) 描述句子代表主题的程度。d[i][j] 在句子j 中显示主题i 的权重。
对应的每一个Topic选择一个句子,问题就是句子的数目就是固定的,同时一个Topic可能是多个句子来表达的
所以就做了Enhancement,对Topic做了权重评级确定所需的句子长度,也就是动态变化的
对句子权重进行了定义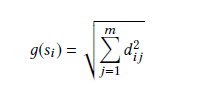
Bayesian Topic Models
现有的方法有若干的局限
- 句子认为是相互独立的,忽视了文档里嵌入的主题
- 句子分值的计算是没有明确的解释性
贝叶斯模型可以揭露和表达文章的主题同时提取到其他的方法忽略的信息
引入了Kullbak-Liebler (KL). 用来描述概率分布的差异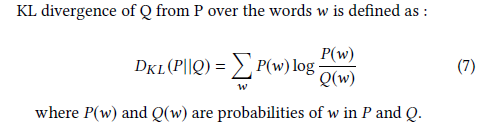
上述的差异分布计算能够比较好的对句子进行评分
因为好的概述就是要和输入的原文差异较小
LDA模型,从一些文章中无监督的抽取出主题信息
文章信息是潜在的一些主题构成的,主题又是由一些单词的分布构成的
对应的有一个模型,发掘文本的主题结构,然后利用基于树的计分函数计算和标注数据的相似度
接着利用分数训练一个回归模型(根据词汇和句子结构)
然后利用这个来对新的文章的句子进行评分
Part4
知识库和自动摘要
普通摘要并不理解单词的语义,使用知识库可以优化这个过程
现存的人类知识库对文本摘要有强化可能
Part5
THE IMPACT OF CONTEXT IN SUMMARIZATION
对于发掘文本最关键的信息,往往可以利用一些额外的数据信息,例如博客的评论
Web Summarization
网页的包含大量不可概括的资源(图片),文本资源相对稀缺,摘要工具难以应用
网页里就是查看有链接指向特定网页的网页,对这些网页进行分析
Scientific Articles Summarization
对科学论文进行计算的一个增强方法就是找到引用了目标论文的论文
抽取出发生了引用的句子:为了发掘出原文的重点主题
有一个方法是对引用的句子里的单词计算概率,使用KL方法对句子的重要性进行评分(找到相似度)
Email Summarization
邮件有一定明显的特征可以指示文章的主题
邮件的概括可以关注于会话信息,对一系列的文本进行分析
Part6
直接利用feature对句子打分和排名,而不再关注于对Topic的表达
基于图的和机器学习的算法用于这个
Graph based
基于图的方案被PageRannk算法影响,用连通图表达文章
句子是图的节点,节点之间的边表达句子的相似度
一个常用的方法就是对TF-IDF计算余弦相似度,高于阈值就链接两个点
这个算法最后得到两个结果
- 子图建立了离散的Topic,覆盖原文的内容
- 对句子进行筛选,句子和其他的很多句子相连的很有可能是概述的部分
图算法可以应用于多文档和单文档的
他们也不需要语言语法处理,可以应用于多个语种。
使用TF-IDF有一定的局限性,因为TF-IDF只是基于词频,没有考虑语义信息
对此可以做一些修改,考虑到语义信息,可以有一定的增强
Machine Learning for Summarization
机器学习方法把概述任务作为了一个分类问题(早期的时候)
有一个方案就是对句子的评估分类,目标就是训练标注句子是否在结果里
使用贝叶斯做分类,用feature评估句子在Summary里的概率
本质上也是对句子进行打分
常用的指标有:句子长度,句子位置,大写单词位置,和标题相似度

其他的一些常用的模型
- 朴素贝叶斯
- 决策树
- 支持向量机
- 隐藏马尔可夫模型
- 条件随机场
一个基本区别就是假设句子是相对独立的被判断是否在摘要里
一个基本的条件就是利用监督数据来训练分类器,数据并不好弄
解决方案
- 建立有注释的语料库,可以作为评估不同的模型性能的指标,但是花费大而且标准不统一
- 半监督的方案,半监督的方案就是利用了无标注的数据和有标注的数据结合。一个方案是训练两个分类器,然后迭代的对无监督数据进行分离,每一轮把得分最好的无监督数据加入有监督数据集,然后继续在新的数据集上训练
Part7
评估自动生成概述
有若干的问题
- 评估工具需要识别原文的重要信息来保留
- 在候选的内容里还需要找到重要信息,这些信息可能被不同的表达法表达
- 概述的可读性需要被评估
人工评估
最简单的办法就是人工评估评估方法
ROUGE is the most widely used metric for automatic evaluationROUGE
和人类的概述结果比对,有若干的方法ROUGE-n
使用n-gram进行评估
n-gram是一系列的滑动窗口,窗口大小就是n
然后在reference和结果之间进行比对,相同的数目除于reference的切割出的数目ROUGE-L
LCS最长公共子序列
越长越相似,对上述的对比更灵活但是要求n-gram连续ROUGE-SU
不要求序列连续,可以跳过,也就是可以在中间插入词

若有收获,就点个赞吧
0 人点赞
