数据处理
原文本格式
{"text": "他们需要1分确保小组出线。出线形势要求赫塔必须全力争胜。interwetten相同赔率下,", "label": {"organization": {"赫塔": [[19, 20]], "interwetten": [[28, 38]]}}}{"text": "20雷池,本场无冷迹象。", "label": {"address": {"雷池": [[2, 3]]}}}
使用readjson进行读取
def _read_json(self,input_file):lines = []with open(input_file,'r',encoding='UTF-8') as f:for line in f:line = json.loads(line.strip())text = line['text']label_entities = line.get('label',None)words = list(text)labels = ['O'] * len(words)if label_entities is not None:for key,value in label_entities.items():for sub_name,sub_index in value.items():for start_index,end_index in sub_index:assert ''.join(words[start_index:end_index+1]) == sub_nameif start_index == end_index:labels[start_index] = 'S-'+keyelse:labels[start_index] = 'B-'+keylabels[start_index+1:end_index+1] = ['I-'+key]*(len(sub_name)-1)lines.append({"words": words, "labels": labels})return lines
最终的读取结果是标注的BIOS或者是BIO的格式,一个是每一个字的序列,另一个是标签序列
这里用的是BIOS
简单的说就是B开头的tag是一个词的开始,I开头的Tag是一个词的身体
一个实体就是B开头一直到O,或者是B,反正不是I就说明读取到头了
S没太注意代表啥,应该是只有一个字的实体吧?猜的。
接着读取的结果进入_create_examples,进而进入get_entities
由于上述的读取函数的处理,使得后面的两个函数支持标准的数据集格式读写
class CluenerProcessor(DataProcessor):"""Processor for the chinese ner data set."""def get_train_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_json(os.path.join(data_dir, "train.json")), "train")def get_dev_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_json(os.path.join(data_dir, "dev.json")), "dev")def get_test_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_json(os.path.join(data_dir, "test.json")), "test")def get_labels(self):"""See base class."""return ["O", "address", "book","company",'game','government','movie','name','organization','position','scene']def _create_examples(self, lines, set_type):"""Creates examples for the training and dev sets."""examples = []for (i, line) in enumerate(lines):guid = "%s-%s" % (set_type, i)text_a = line['words']labels = line['labels']subject = get_entities(labels,id2label=None,markup='bios')examples.append(InputExample(guid=guid, text_a=text_a, subject=subject))return examplesner_processors = {'cluener':CluenerProcessor}
def get_entities(seq,id2label,markup='bios'):''':param seq::param id2label::param markup::return:'''assert markup in ['bio','bios']if markup =='bio':return get_entity_bio(seq,id2label)else:return get_entity_bios(seq,id2label)
def get_entities(seq,id2label,markup='bios'):''':param seq::param id2label::param markup::return:'''assert markup in ['bio','bios']if markup =='bio':return get_entity_bio(seq,id2label)else:return get_entity_bios(seq,id2label)
def get_entity_bios(seq,id2label):"""Gets entities from sequence.note: BIOSArgs:seq (list): sequence of labels.Returns:list: list of (chunk_type, chunk_start, chunk_end).Example:# >>> seq = ['B-PER', 'I-PER', 'O', 'S-LOC']# >>> get_entity_bios(seq)[['PER', 0,1], ['LOC', 3, 3]]"""chunks = []chunk = [-1, -1, -1]for indx, tag in enumerate(seq):if not isinstance(tag, str):tag = id2label[tag]if tag.startswith("S-"):if chunk[2] != -1:chunks.append(chunk)chunk = [-1, -1, -1]chunk[1] = indxchunk[2] = indxchunk[0] = tag.split('-')[1]chunks.append(chunk)chunk = (-1, -1, -1)if tag.startswith("B-"):if chunk[2] != -1:chunks.append(chunk)chunk = [-1, -1, -1]chunk[1] = indxchunk[0] = tag.split('-')[1]elif tag.startswith('I-') and chunk[1] != -1:_type = tag.split('-')[1]if _type == chunk[0]:chunk[2] = indxif indx == len(seq) - 1:chunks.append(chunk)else:if chunk[2] != -1:chunks.append(chunk)chunk = [-1, -1, -1]return chunks
def collate_fn(batch):"""batch should be a list of (sequence, target, length) tuples...Returns a padded tensor of sequences sorted from longest to shortest,"""all_input_ids, all_input_mask, all_segment_ids, all_start_ids,all_end_ids,all_lens = map(torch.stack, zip(*batch))max_len = max(all_lens).item()all_input_ids = all_input_ids[:, :max_len]all_input_mask = all_input_mask[:, :max_len]all_segment_ids = all_segment_ids[:, :max_len]all_start_ids = all_start_ids[:,:max_len]all_end_ids = all_end_ids[:, :max_len]return all_input_ids, all_input_mask, all_segment_ids, all_start_ids,all_end_ids,all_lens
下面使用的处理函数
使用注释简单的说明做的事情
def convert_examples_to_features(examples,label_list,max_seq_length,tokenizer,cls_token_at_end=False,cls_token="[CLS]",cls_token_segment_id=1,sep_token="[SEP]",pad_on_left=False,pad_token=0,pad_token_segment_id=0,sequence_a_segment_id=0,mask_padding_with_zero=True,):""" Loads a data file into a list of `InputBatch`s`cls_token_at_end` define the location of the CLS token:- False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]- True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]`cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)"""label2id = {label: i for i, label in enumerate(label_list)}features = []for (ex_index, example) in enumerate(examples):if ex_index % 10000 == 0:logger.info("Writing example %d of %d", ex_index, len(examples))textlist = example.text_asubjects = example.subjecttokens = tokenizer.tokenize(textlist)start_ids = [0] * len(tokens)end_ids = [0] * len(tokens)subjects_id = []for subject in subjects:label = subject[0]start = subject[1]end = subject[2]# Subjuct examples# subject [['organization', 3, 4]]# fist Name , Second start pos , third end posstart_ids[start] = label2id[label]end_ids[end] = label2id[label]subjects_id.append((label2id[label], start, end))# Account for [CLS] and [SEP] with "- 2".special_tokens_count = 2# 截断if len(tokens) > max_seq_length - special_tokens_count:tokens = tokens[: (max_seq_length - special_tokens_count)]start_ids = start_ids[: (max_seq_length - special_tokens_count)]end_ids = end_ids[: (max_seq_length - special_tokens_count)]# The convention in BERT is:# (a) For sequence pairs:# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1# (b) For single sequences:# tokens: [CLS] the dog is hairy . [SEP]# type_ids: 0 0 0 0 0 0 0## Where "type_ids" are used to indicate whether this is the first# sequence or the second sequence. The embedding vectors for `type=0` and# `type=1` were learned during pre-training and are added to the wordpiece# embedding vector (and position vector). This is not *strictly* necessary# since the [SEP] token unambiguously separates the sequences, but it makes# it easier for the model to learn the concept of sequences.## For classification tasks, the first vector (corresponding to [CLS]) is# used as as the "sentence vector". Note that this only makes sense because# the entire model is fine-tuned.#加上末尾标志tokens += [sep_token]start_ids += [0]end_ids += [0]# 这个Segment_id有社么用?????segment_ids = [sequence_a_segment_id] * len(tokens)if cls_token_at_end:tokens += [cls_token]start_ids += [0]end_ids += [0]segment_ids += [cls_token_segment_id]else:tokens = [cls_token] + tokensstart_ids = [0]+ start_idsend_ids = [0]+ end_idssegment_ids = [cls_token_segment_id] + segment_idsinput_ids = tokenizer.convert_tokens_to_ids(tokens)# The mask has 1 for real tokens and 0 for padding tokens. Only real# tokens are attended to.input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)input_len = len(input_ids)# Zero-pad up to the sequence length.padding_length = max_seq_length - len(input_ids)if pad_on_left:input_ids = ([pad_token] * padding_length) + input_idsinput_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_masksegment_ids = ([pad_token_segment_id] * padding_length) + segment_idsstart_ids = ([0] * padding_length) + start_idsend_ids = ([0] * padding_length) + end_idselse:input_ids += [pad_token] * padding_lengthinput_mask += [0 if mask_padding_with_zero else 1] * padding_lengthsegment_ids += [pad_token_segment_id] * padding_lengthstart_ids += ([0] * padding_length)end_ids += ([0] * padding_length)assert len(input_ids) == max_seq_lengthassert len(input_mask) == max_seq_lengthassert len(segment_ids) == max_seq_lengthassert len(start_ids) == max_seq_lengthassert len(end_ids) == max_seq_length'''if ex_index < 5:logger.info("*** Example ***")logger.info("guid: %s", example.guid)logger.info("tokens: %s", " ".join([str(x) for x in tokens]))logger.info("input_ids: %s", " ".join([str(x) for x in input_ids]))logger.info("input_mask: %s", " ".join([str(x) for x in input_mask]))logger.info("segment_ids: %s", " ".join([str(x) for x in segment_ids]))logger.info("start_ids: %s" % " ".join([str(x) for x in start_ids]))logger.info("end_ids: %s" % " ".join([str(x) for x in end_ids]))'''features.append(InputFeature(input_ids=input_ids,input_mask=input_mask,segment_ids=segment_ids,start_ids=start_ids,end_ids=end_ids,subjects=subjects_id,input_len=input_len))return features
没看明白Segment_id是为了做什么的
看上去和普通的Token差不多
后续说的是XLM和RoBerta不用这个,Xlnet和Bert用。。。没看懂
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long)all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long)all_start_ids = torch.tensor([f.start_ids for f in features], dtype=torch.long)all_end_ids = torch.tensor([f.end_ids for f in features], dtype=torch.long)all_input_lens = torch.tensor([f.input_len for f in features], dtype=torch.long)dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_start_ids,all_end_ids,all_input_lens)
后面输入给模型
inputs = {"input_ids": batch[0], "attention_mask": batch[1],"start_positions": batch[3],"end_positions": batch[4]}if args.model_type != "distilbert":# XLM and RoBERTa don"t use segment_idsinputs["token_type_ids"] = (batch[2] if args.model_type in ["bert", "xlnet"] else None)
模型构造
class BertSpanForNer(BertPreTrainedModel):def __init__(self, config,):super(BertSpanForNer, self).__init__(config)self.soft_label = config.soft_labelself.num_labels = config.num_labelsself.loss_type = config.loss_typeself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.start_fc = PoolerStartLogits(config.hidden_size, self.num_labels)if self.soft_label:self.end_fc = PoolerEndLogits(config.hidden_size + self.num_labels, self.num_labels)else:self.end_fc = PoolerEndLogits(config.hidden_size + 1, self.num_labels)self.init_weights()def forward(self, input_ids, token_type_ids=None, attention_mask=None, start_positions=None,end_positions=None):outputs = self.bert(input_ids = input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)sequence_output = outputs[0]sequence_output = self.dropout(sequence_output)start_logits = self.start_fc(sequence_output)if start_positions is not None and self.training:if self.soft_label:batch_size = input_ids.size(0)seq_len = input_ids.size(1)label_logits = torch.FloatTensor(batch_size, seq_len, self.num_labels)label_logits.zero_()label_logits = label_logits.to(input_ids.device)label_logits.scatter_(2, start_positions.unsqueeze(2), 1)else:label_logits = start_positions.unsqueeze(2).float()else:label_logits = F.softmax(start_logits, -1)if not self.soft_label:label_logits = torch.argmax(label_logits, -1).unsqueeze(2).float()end_logits = self.end_fc(sequence_output, label_logits)outputs = (start_logits, end_logits,) + outputs[2:]if start_positions is not None and end_positions is not None:assert self.loss_type in ['lsr', 'focal', 'ce']if self.loss_type =='lsr':loss_fct = LabelSmoothingCrossEntropy()elif self.loss_type == 'focal':loss_fct = FocalLoss()else:loss_fct = CrossEntropyLoss()start_logits = start_logits.view(-1, self.num_labels)end_logits = end_logits.view(-1, self.num_labels)active_loss = attention_mask.view(-1) == 1active_start_logits = start_logits[active_loss]active_end_logits = end_logits[active_loss]active_start_labels = start_positions.view(-1)[active_loss]active_end_labels = end_positions.view(-1)[active_loss]start_loss = loss_fct(active_start_logits, active_start_labels)end_loss = loss_fct(active_end_logits, active_end_labels)total_loss = (start_loss + end_loss) / 2outputs = (total_loss,) + outputsreturn outputs
模型的输出为一个Tuple类型
第一项的 output0 : torch.Size([8, 50, 768])应该是序列数据对应的输出
第二项的 output1 :torch.Size([8, 768])应该是整个句子的编码
本次用的是第一项,之前用Bert做句子分类的时候
看demo似乎用的就是第二项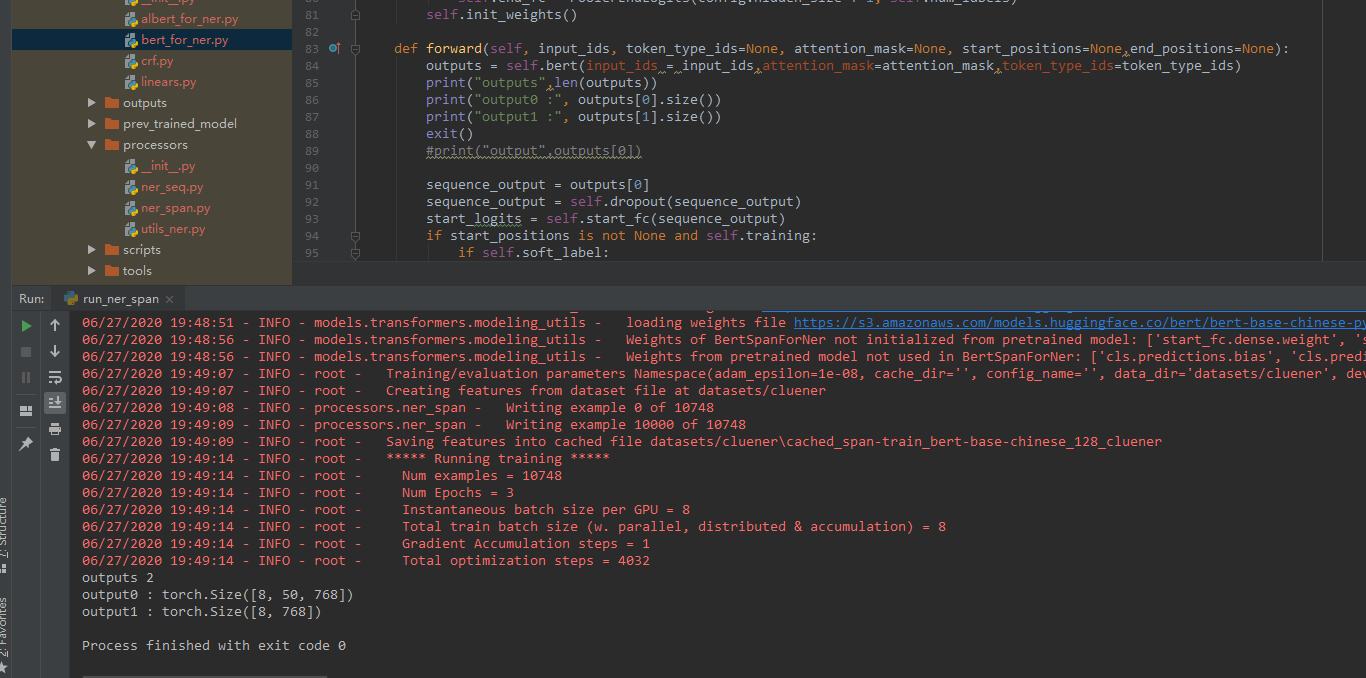
输出分为两个部分
第一个是计算开始的位置
start_position是传进来的参数
使用scatter的用法,初步的理解就是在对应的开始的位置填充上1,每一个句子里可能的实体对应的位置为1
sequence_output = outputs[0]sequence_output = self.dropout(sequence_output)start_logits = self.start_fc(sequence_output)if start_positions is not None and self.training:if self.soft_label:#print("hit here")batch_size = input_ids.size(0)seq_len = input_ids.size(1)label_logits = torch.FloatTensor(batch_size, seq_len, self.num_labels)label_logits.zero_()label_logits = label_logits.to(input_ids.device)label_logits.scatter_(2, start_positions.unsqueeze(2), 1)
之前的attention mask标记了句子的真实长度
这里相当于就是截断,重新得到真实的句子长度
active_loss = attention_mask.view(-1) == 1active_start_logits = start_logits[active_loss]active_end_logits = end_logits[active_loss]
最后计算得到了X个Batch里句子的具体长度和Y的每一个位置的值,以及对应的Start_id的分布
比如句子长度是100,则每一个位置的值start_logits就是100个奇奇怪怪的数字,start_id就是这句子里所有的实体的开始位置上有着对应实体类别的值,对应的送入损失函数计算。同理计算得到的end_id和对应end_label进入计算
输入的格式就是【length,labels_nums】和【length】,多种损失函数,默认交叉熵损失函数
这里还是第一次这么这种的多个分类问题的损失函数
最后的最后就是用两个Loss的平均值作为最后的loss
训练准备
一系列的预处理
可能是由于需要自己构造模型,所以在训练前进行了大量的指定
关于优化器和参数decay
还有一个新的东西就是指定了Warmup
""" Train the model """args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size,collate_fn=collate_fn)if args.max_steps > 0:t_total = args.max_stepsargs.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1else:t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs# Prepare optimizer and schedule (linear warmup and decay)no_decay = ["bias", "LayerNorm.weight"]optimizer_grouped_parameters = [{"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],"weight_decay": args.weight_decay,},{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},]optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps,num_training_steps=t_total)
预测设置
最后在predict的时候需要函数转化出可视化的结果
由于先前的计算可以知道start_logits和end_logits就是当前batch的句子的计算结果:
【batch_num,length,labels_num】
在预测的时候batch_num设置为1,也就是一次一个句子
torch.argmax会得到在labels_num维度上的最大值的下标,也就是最大的值所在的索引,最后就是一个列表,长度是【length】。里面如果不是实体的起点或者是终点就是0(应该也是类型的预设之一:无类型),反之就是类型的编号。最后如果找到了不为1的数字,就到end列表里找标号相等的结尾标记。算法结束。
def bert_extract_item(start_logits, end_logits):S = []start_pred = torch.argmax(start_logits, -1).cpu().numpy()[0][1:-1]end_pred = torch.argmax(end_logits, -1).cpu().numpy()[0][1:-1]for i, s_l in enumerate(start_pred):if s_l == 0:continuefor j, e_l in enumerate(end_pred[i:]):if s_l == e_l:S.append((s_l, i, i + j))breakreturn S
注
这一段话说的是type_id是用来指示这是第一句话还是第二句话
第一句话是0,第二句话是1。
对应的0/1向量在预训练里被学习,然后加入词向量和位置向量
由于SEP明确的区分了两个句子,所以这个并不是严格有用的,但是这让模型更加容易的理解序列的概念
对于分类任务而言,句子首向量(CLS对应的向量)被作为代表整个句子的向量。
这个只有在整个模型被微调后才有效
# The convention in BERT is:# (a) For sequence pairs:# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1# (b) For single sequences:# tokens: [CLS] the dog is hairy . [SEP]# type_ids: 0 0 0 0 0 0 0## Where "type_ids" are used to indicate whether this is the first# sequence or the second sequence. The embedding vectors for `type=0` and# `type=1` were learned during pre-training and are added to the wordpiece# embedding vector (and position vector). This is not *strictly* necessary# since the [SEP] token unambiguously separates the sequences, but it makes# it easier for the model to learn the concept of sequences.## For classification tasks, the first vector (corresponding to [CLS]) is# used as as the "sentence vector". Note that this only makes sense because# the entire model is fine-tuned.

若有收获,就点个赞吧
0 人点赞
