指导对象
- 模型结构设计
- 预训练策略
- 训练策略
主要特征
Constituent Factors
Positional Information
位置信息,对摘要对应原文的位置进行分析,然后分析数据集之后这种位置分布的差异性Content Information
信息覆盖,原文和摘要之间n-gram相同,说明二者的信息相对一致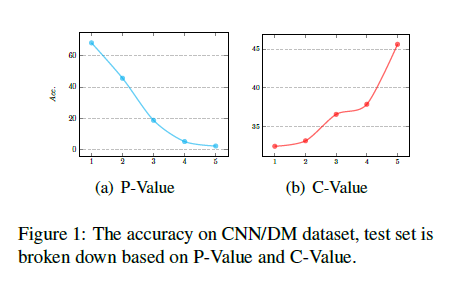
Style Factors
Density
共现词的频率,比较高的数据对抽取式算法比较友好
Density高的时候,LCS在前三句子的占比会更好,使得抽取是比较简单的
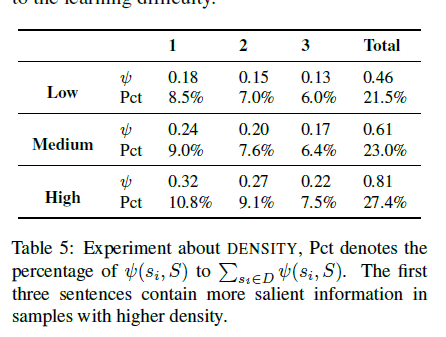
Compression
压缩度,文章长度的比例
Integrated Gradients方法
特征的结果还是比较符合直觉的,自己和自己最相近,以及新闻类相近,科学文章相似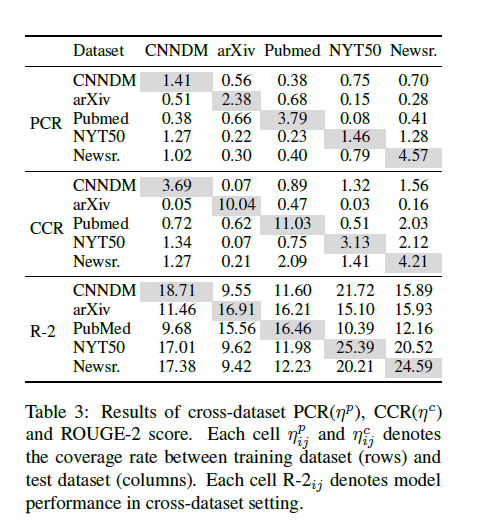
当信息的压缩度比较高的时候,位置信息提供的帮助比较少,更多的会依赖于语义信息
(这个部分的实验是把实际句子加上位置信息和Padding Token加上位置信息对比)
分析
基于上述的指标对模型分析
- 在数据比较难的时候(低Density和高Compression)LSTM的表现优于Transformer
- pretrain信息带来提升,但是当数据难的时候,增益减小
- 难的数据里好的模型结构和pretrain信息都很有限了,考虑转型抽取式到生成式
基于上述的指标对训练策略分析
实验方法:在CNN/DM上训练,然后在CNN/DM以及其他的数据集上测试,测试对象包括:joint training, multi-domain learning with explicit information (tag embedding), implicit information (BERT) and meta-learning.
实验结果
- 加上领域信息有提升:Domain tag
- MetaLearning在原数据集上差,但是在跨数据集测试上不错,尤其是和CNN/DM特征类似的数据集
- Bert带来的外部知识帮助模型找到有价值的pattern进而改进了在高Density高Compression数据的表现
对数据进行划分后加上Tag带来的提升,实验方法是随机加无意义Tag,CNN和DM分开两种Tag,以及根据之前的PV值划分的Tag。最后的结论如下
- 随机划分没意义,也没有提升
- 根据Domain划分有大提升,和Bert带来的提升互补可叠加
- 根据PV划分的结果是最好的,即对于数据特性的分析有好效果

若有收获,就点个赞吧
0 人点赞
