怀疑现在的模型不会推理
做法:
- 统计Pretrain Corpus里数字出现的数量
- 用Top10%的数字构造出数据,用Buttom10%的数字再构造出数据
- 然后在Few-shot(控制训练样本的数量k)下看看模型的预测结果
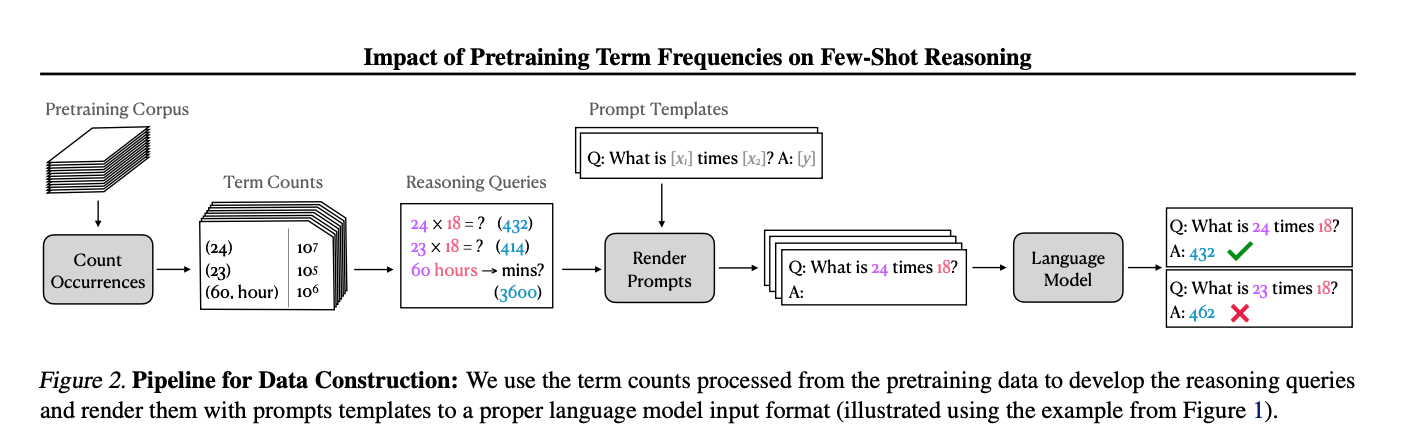
在数据里出现的频率很大的影响了模型的性能
因此看上去模型并没有总结出规律并推导,而只是从预训练中记住
在few shot数据增多的时候,频率带来的Gap变大了,得出结论模型是依赖于预训练数据里的知识解决问题的
第三是观察到了大模型对结果很有帮助,尤其是在低频率的数据上,小的模型在低频率的数据上做的很差

若有收获,就点个赞吧
0 人点赞
