资料收集
step1. create-pretraining-data
paper的源码是用c++写的,这里用py又实现了一遍。。实现masked lm和next sentence prediction。
输入文件的格式:一行一句话(对于next sentence prediction这很重要),不同文档间用空行分隔。例如sample_text.txt:
1. Something glittered in the nearest red pool before him.2. Gold, surely!3. But, wonderful to relate, not an irregular, shapeless fragment of crude ore, fresh from Nature's crucible, but a bit of jeweler's handicraft in the form of a pla4. in gold ring.5. Looking at it more attentively, he saw that it bore the inscription, "May to Cass."6. Like most of his fellow gold-seekers, Cass was superstitious.7.8. The fountain of classic wisdom, Hypatia herself.9. As the ancient sage--the name is unimportant to a monk--pumped water nightly that he might study by day, so I, the guardian of cloaks and parasols, at the sacred10. doors of her lecture-room, imbibe celestial knowledge.11. From my youth I felt in me a soul above the matter-entangled herd.12. She revealed to me the glorious fact, that I am a spark of Divinity itself.
输出是一系列的TFRecord的tf.train.Example。
注意:这个脚本把整个输入文件都放到内存里了,所以对于大文件,你可能需要把文件分片,然后跑多次这个脚本,得到一堆tf_examples.tf_record*,然后把这些文件都作为下一个脚本run_pretraining.py的输入。
参数:
- max_predictions_per_seq:每个序列里最大的masked lm predictions。建议设置为
max_seq_length*masked_lm_prob(这个脚本不会自动设置) ```
- python create_pretraining_data.py \
- —input_file=./sample_text.txt \
- —output_file=/tmp/tf_examples.tfrecord \
- —vocab_file=$BERT_BASE_DIR/vocab.txt \
- —do_lower_case=True \
- —max_seq_length=128 \
- —max_predictions_per_seq=20 \
- —masked_lm_prob=0.15 \
- —random_seed=12345 \
- —dupe_factor=5
输出如下:
- INFO:tensorflow: Example
- INFO:tensorflow:tokens: [CLS] indeed , it was recorded in [MASK] star that a fortunate early [MASK] ##r had once picked up on the highway a solid chunk [MASK] gold quartz which the [MASK] had freed from its inc [MASK] ##ing soil , and washed into immediate and [MASK] popularity . [SEP] rainy season , [MASK] insult show habit of body , and seldom lifted their eyes to the rift ##ed [MASK] india - ink washed skies [MASK] them . “ cass “ beard [MASK] elliot early that morning , but not with a view to [MASK] . a leak in his [MASK] roof , - - quite [MASK] with his careless , imp ##rov ##ide ##nt habits , - - had rouse ##d him at 4 a [MASK] m [SEP]
- INFO:tensorflow:input_ids: 101 5262 1010 2009 2001 2680 1999 103 2732 2008 1037 19590 2220 103 2099 2018 2320 3856 2039 2006 1996 3307 1037 5024 20000 103 2751 20971 2029 1996 103 2018 10650 2013 2049 4297 103 2075 5800 1010 1998 8871 2046 6234 1998 103 6217 1012 102 16373 2161 1010 103 15301 2265 10427 1997 2303 1010 1998 15839 4196 2037 2159 2000 1996 16931 2098 103 2634 1011 10710 8871 15717 103 2068 1012 1000 16220 1000 10154 103 11759 2220 2008 2851 1010 2021 2025 2007 1037 3193 2000 103 1012 1037 17271 1999 2010 103 4412 1010 1011 1011 3243 103 2007 2010 23358 1010 17727 12298 5178 3372 14243 1010 1011 1011 2018 27384 2094 2032 2012 1018 1037 103 1049 102
- INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- INFO:tensorflow:masked_lm_positions: 7 12 13 25 30 36 45 52 53 54 68 74 81 82 93 99 103 105 125 0
- INFO:tensorflow:masked_lm_ids: 17162 2220 4125 1997 4542 29440 20332 4233 1037 16465 2030 2682 2018 13763 5456 6644 1011 8335 1012 0
- INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0
- INFO:tensorflow:next_sentence_labels: 0
- INFO:tensorflow: Example
- INFO:tensorflow:tokens: [CLS] and there burst on phil ##am ##mon ‘ s astonished eyes a vast semi ##ci ##rcle of blue sea [MASK] ring ##ed with palaces and towers [MASK] [SEP] like most of [MASK] fellow gold - seekers , cass was super ##sti [MASK] . [SEP]
- INFO:tensorflow:input_ids: 101 1998 2045 6532 2006 6316 3286 8202 1005 1055 22741 2159 1037 6565 4100 6895 21769 1997 2630 2712 103 3614 2098 2007 22763 1998 7626 103 102 2066 2087 1997 103 3507 2751 1011 24071 1010 16220 2001 3565 16643 103 1012 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- INFO:tensorflow:masked_lm_positions: 10 20 23 27 32 39 42 0 0 0 0 0 0 0 0 0 0 0 0 0
- INFO:tensorflow:masked_lm_ids: 22741 1010 2007 1012 2010 2001 20771 0 0 0 0 0 0 0 0 0 0 0 0 0
- INFO:tensorflow:masked_lm_weights: 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
- INFO:tensorflow:next_sentence_labels: 1
- INFO:tensorflow:Wrote 60 total instances
```
step2. run-pretraining
- 如果你是从头开始pretrain,不要include init_checkpoint
- 模型配置(包括vocab size)在bert_config_file中设置
- num_train_steps在现实中一般要设置10000以上
- max_seq_length和max_predictions_per_seq要和传给create_pretraining_data的一样 ```
- python run_pretraining.py \
- —input_file=/tmp/tf_examples.tfrecord \
- —output_dir=/tmp/pretraining_output \
- —do_train=True \
- —do_eval=True \
- —bert_config_file=$BERT_BASE_DIR/bert_config.json \
- —init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
- —train_batch_size=32 \
- —max_seq_length=128 \
- —max_predictions_per_seq=20 \
- —num_train_steps=20 \
- —num_warmup_steps=10 \
- —learning_rate=2e-5
跑的时候发现会充分利用显存,具体不是特别清楚,显存太小应该也跑不了吧。由于sample_text.txt很小,所以会overfit。log如下(最后会生成一个`eval_results.txt`文件,记录`***** Eval results *****`部分):
- INFO:tensorflow:Done running local_init_op.
- INFO:tensorflow:Evaluation [10/100]
- INFO:tensorflow:Evaluation [20/100]
- INFO:tensorflow:Evaluation [30/100]
- INFO:tensorflow:Evaluation [40/100]
- INFO:tensorflow:Evaluation [50/100]
- INFO:tensorflow:Evaluation [60/100]
- INFO:tensorflow:Evaluation [70/100]
- INFO:tensorflow:Evaluation [80/100]
- INFO:tensorflow:Evaluation [90/100]
- INFO:tensorflow:Evaluation [100/100]
- INFO:tensorflow:Finished evaluation at 2018-10-31-18:13:12
- INFO:tensorflow:Saving dict for global step 20: global_step = 20, loss = 0.27842212, masked_lm_accuracy = 0.94665253, masked_lm_loss = 0.27976906, next_sentence_accuracy = 1.0, next_sentence_loss = 0.0002133457
- INFO:tensorflow:Saving ‘checkpoint_path’ summary for global step 20: ./pretraining_output/model.ckpt-20
- INFO:tensorflow:* Eval results *
- INFO:tensorflow: global_step = 20
- INFO:tensorflow: loss = 0.27842212
- INFO:tensorflow: masked_lm_accuracy = 0.94665253
- INFO:tensorflow: masked_lm_loss = 0.27976906
- INFO:tensorflow: next_sentence_accuracy = 1.0
- INFO:tensorflow: next_sentence_loss = 0.0002133457 ```
pretrain tips and caveats
- 如果你的任务有很大的domain-specific语料,最好从bert的checkpoint开始,在你的语料上进行多一些的pre-train
- paper中的学习率设为1e-4,如果基于已有bert checkpoint继续pretrain,建议把学习率调小(如2e-5)
- 更长的序列的计算代价会非常大,因为attention是序列长度平方的复杂度。例如,一个长度是512的minibatch-size=64的batch,比一个长度为128的minibatch-size=256的batch计算代码要大得多。对于全连接或者cnn来讲,其实这个计算代价是一样的。但对attention而言,长度是512的计算代价会大得多。所以,建议对长度为128的序列进行9w个step的预训练,然后对长度为512的序列再做1w个step的预训练是更好的~对于非常长的序列,最需要的是学习positional embeddings,这是很快就能学到的啦。注意,这样做就需要使用不同的max_seq_length来生成两次数据。
- 如果你从头开始pretrain,计算代价是很大的,特别是在gpu上。建议的是在一个preemptible Cloud TPU v2上pretrain一个bert-base(2周要500美刀…)。如果在一个single cloud TPU上的话,需要把batchsize scale down。建议使用能占满TPU内存的最大batchsize…
https://blog.csdn.net/weixin_39470744/article/details/84373933
https://blog.csdn.net/luoyexuge/article/details/85001859
实验
bert pretrain
根据上周收集到的信息,以及比赛任务的具体的要求
我对bert pretrain进行实验(不管比赛结果怎么样,学会这个方法)
(这个应该挺有用?感觉脱敏词表应该挺常见的)
preparation
训练数据
首先需要有训练数据,无监督,不需要标注,每一行是一个句子
于是直接使用test.txt(提交用的数据)
生成词表
然后生成词表 vacab.txt
由于本次的词是vocab_size=51158
于是直接利用脚本生成
有一个需要注意的就是三个额外词
这三个词绝对不能少,并且格式需要正确,否则报错
filename="vocab.txt"with open(filename, 'w') as file_object:for i in range(52000):file_object.write(str(i) + "\n")file_object.write("[CLS]" + "\n")file_object.write("[ESP]" + "\n")file_object.write("[MASK]")
creat pretrain data
使用如下的指令进行
python create_pretraining_data.py --input_file=./test.txt --output_file=hhh.tfrecord --vocab_file=vocab.txt \ —do_lower_case=True \ —max_seq_length=128 \ —max_predictions_per_seq=20 \ —masked_lm_prob=0.15 \ —random_seed=12345 \ —dupe_factor=5
run pretrain
修改bert_config
预期应该是二分类,直接修改14行为2
共计词数 52003(包含特殊词)
类型词数:2(0和1)
{"attention_probs_dropout_prob": 0.1,"directionality": "bidi","hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"max_position_embeddings": 512,"num_attention_heads": 12,"num_hidden_layers": 12,"pooler_fc_size": 768,"pooler_num_attention_heads": 12,"pooler_num_fc_layers": 2,"pooler_size_per_head": 128,"pooler_type": "first_token_transform","type_vocab_size": 2,"vocab_size": 52003}
使用如下指令
注意到这里不需要使用预训练模型作为预训练的基础
所以不用include init_checkpoint
python run_pretraining.py \--input_file=tf_examples.tfrecord \--output_dir=pretraining_output \--do_train=True \--do_eval=True \--bert_config_file=bert_config.json \--train_batch_size=32 \--max_seq_length=128 \--max_predictions_per_seq=20 \--num_train_steps=20 \--num_warmup_steps=10 \--learning_rate=2e-5
结果如下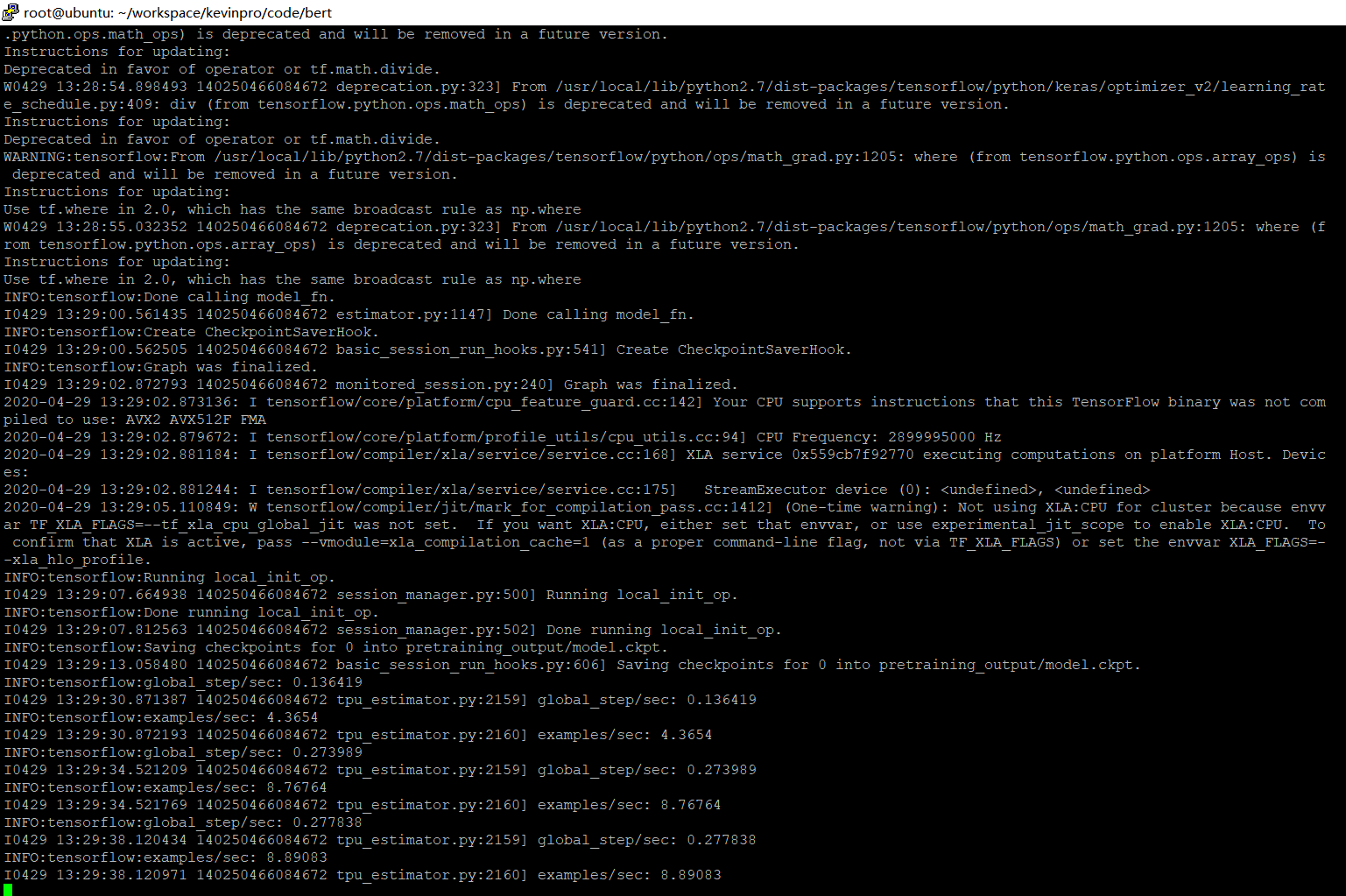
结果不太理想?
不过也正常,数据量小(跑的很快,几分钟就好了),瞎塞一通(没有对数据的进一步处理)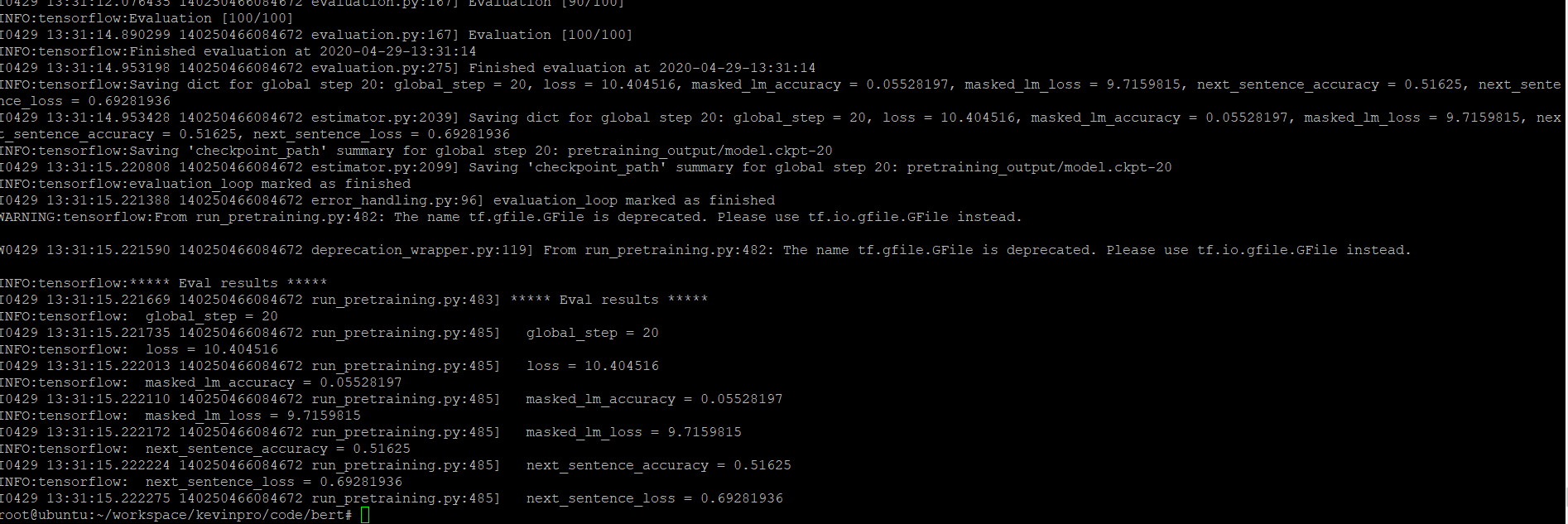

若有收获,就点个赞吧
0 人点赞
