Lead算法
Lead算法是摘要算法中比较简单快速,但是又高效的算法
基本原理就是只选择文章的前若干句话作为摘要,经常设置为3
于是对应的实现也比较简单
class Lead:def __init__(self, name, n):self.name = nameself.n = ndef get_summary(self,document):sentences=possess_sentence(document)if len(sentences) < self.n:return sentenceselse:return sentences[0:self.n]def get_labels(self,label):sentences = possess_sentence(label)return sentencesdef train_eval(self,path1,path2,pairs_num):fo = open(path1, "r",encoding='gb18030', errors='ignore')fl = open(path2, "r",encoding='gb18030', errors='ignore')rouge1=0rouge2=0rougeL=0rouge = Rouge()for i in range(pairs_num):line1 = fo.readline()line2 = fl.readline()result=self.get_summary(line1)label=self.get_labels(line2)result=" ".join(result)label=" ".join(label)rouge_score = rouge.get_scores(result, label)#print(rouge_score[0]["rouge-1"])rouge1+=rouge_score[0]["rouge-1"]['r']rouge2+=rouge_score[0]["rouge-2"]['r']rougeL+=rouge_score[0]["rouge-l"]['r']print("Rouge1 Recall",rouge1/pairs_num)print("Rouge2 Recall",rouge2/pairs_num)print("RougeL Recall",rougeL/pairs_num)model=Lead('lead3',3)model.train_eval(file_path,label_path,1000)
数据集
这里使用的文本数据是CNN_Daily Mail
基本的观察发现
- 对应的Train.txt.src里放的是原文,并用##SENTEN##对句子进行分割,一行是多个句子
- 对应的Train.txt.tgt里放的是对应的概述,同样做分割处理,一行多个句子
文本语种为英语,数据集较大,本次仅仅使用部分
同时对文本进行简单的初步的数据清洗和分割处理
def normalizeString(s):#s = re.sub(r"([.!?])", r" \1", s)#s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)s=s.strip()s = s.replace("\n", "")return sdef possess_sentence(s):lines=s.split("##SENT##")for i in lines:i=normalizeString(i)return lines
ROUGE评估
对应的python里有这个包,最简单的就是pip install rouge之后快乐的使用
使用方法如下
支持传入列表和字符串
输出结果是f1和recall 和precision
rouge = Rouge()rouge_score = rouge.get_scores(a, b)print(rouge_score[0]["rouge-1"])print(rouge_score[0]["rouge-2"])print(rouge_score[0]["rouge-l"])
对应的自己实现,这里参考了网上的实现版本,进行了一定的适配修改
RougeL似乎要求LCS感觉很麻烦。。。算了不弄
对应的求值等于上面的Recall项的值
class MyRouge:def rouge1_score(self,sentence,label):line1 = sentence.split(" ")line2 = label.split(" ")ngram_all = len(line2)temp=0for x in line2:if x in line1: temp = temp + 1rouge_1 = temp / ngram_allreturn rouge_1def rouge2_score(self,sentence,label):gram_2_model = []gram_2_reference = []temp = 0sentence = sentence.split(" ")label = label.split(" ")ngram_all = len(label) - 1for x in range(len(sentence) - 1):gram_2_model.append(sentence[x] + sentence[x + 1])for x in range(len(label) - 1):gram_2_reference.append(label[x] + label[x + 1])for x in gram_2_model:if x in gram_2_reference: temp = temp + 1rouge_2 = temp / ngram_allreturn rouge_2
结果
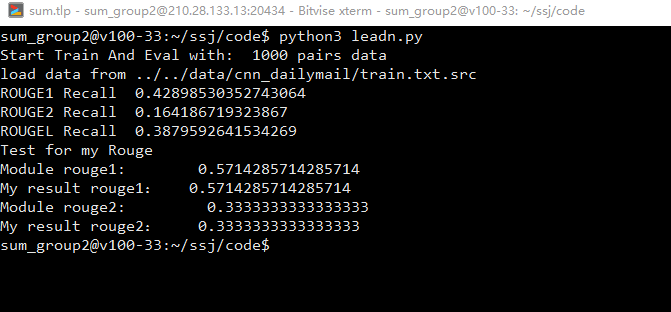
其他
感觉结果并不理想
- 一个是我感觉实现上有问题
- 另一个是我对数据的清洗可能有点问题,这里只是做了基本的去点空格和换行,但是观察到原文里有大量的固定格式的一些句子成分,感觉和数据本身的特性有关,而我没有对应的进行处理
- 第三点就是在Lead算法里我只是用切割符切割,然后用空格链接多个句子作为摘要,可能这么粗糙的拼接,对结果有所影响

若有收获,就点个赞吧
0 人点赞
