和GAN的异同
前面看到的GAN是
- 现有一个随机分布
- 采样一个值,生成一个样本
- 利用 { True Sample,True Label } 以及 { False Sample,False Label } 训练判别器
- 再生成一个样本
- 冻结判别器,用{ False Sample,True Label } 计算误导成功的概率,更新生成器
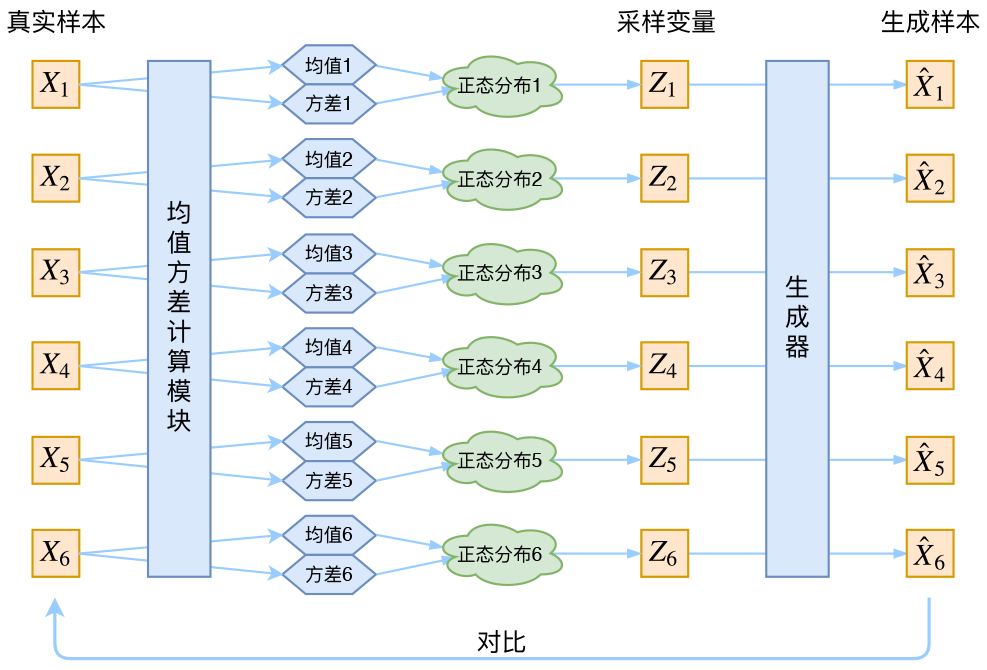
今天看的VAE和GAN有很大的相似性,流程如下
- 输入一些样本
- 利用Encoder对每一个样本生成一个均值和方差
- 假设基于每一个样本生成的每一个后验分布(因为基于输入条件)是正态分布
- 则在标准正态分布中采样,利用均值和方差平移放缩得到隐变量分布采样结果
- 利用隐变量分布采样值,构造样本
- 由于输入和输出样本存在一一对应的关系,因此输出要和输入相同
首先相同点在于
- 二者认为直接获取数据分布是困难的,所以从隐变量中获取,隐变量是已知分布,唯一需要学习的是一个后验分布转化函数。即都是希望从一个分布映射到另一个分布。
- 二者坚信,生成样本由一些Feature构成,可以认为这些Feature符合某种已知分布,则可以利用已知分布重构
- 二者在学习映射上都觉得困难,因此直接用神经网络来学习
不同之处
- GAN的没有输入到输出的一一对应,因为他就没有输入,而VAE假设了输入编码隐变量符合一个正态分布,用了一个Encoder,先把输入转化为一一对应的概率分布。
- 二者的本质目的是想拥有生成器,GAN没有输入,因此他不好构造损失函数,VAE可以直接输出和输入对比。因此GAN是训练一个判别器来对抗学习。VAE则可以利用输入和输出的同质性来学习。
VAE亮点:
从原文编码为一个均值和方差,而不是直接一个隐变量的值或者向量。
我的第一反应是 Hidden = Encoder(input),然后output = Decoder(Hidden)
实际上是(注:E是期望,Sigma是方差)
- E,Sigma = Encoder(input)
- Sample = Normal()
- RealSample = Reparameter(Sample,E,Sigmal)
- Output = Decoder(Hidden)
因此,显然在重构的时候,由于是从一个随机分布采样的,Sigma决定了方差,即采样波动的大小,可以理解为噪声的大小)
对于模型而言,自然是希望我估计的Sigma越小越好,采样的波动越小,隐变量非常接近输入,重构的轻松。
因此VAE使用了第二个Loss,利用KL计算当前正态和标准正态的分布差异。
当Encoder-Decoder训练的很糟的时候,重构的一塌糊涂,即ReConstruct-Loss很大,模型会倾向于低估Sigma,比如让Sigma为0,保证输入的稳定性。当模型重构的好,模型会高估Sigma以降低KL-Loss,因此实现了一个对抗的感觉。
Condition VAE
说白了,GAN和VAE的一个很大的目的,就是希望从无到有。就是从一个虚空的,已知的分布中去映射到数据集分布上,进而可以从已知分布采样,映射到数据集样本,实现了自动样本构造。
VAE支持条件生成,比如有一些样本标签已知,如何把已知标签加入生成,生成这个标签的样本。
举个最简单的例子,前面利用KL-Loss要求生成分布类似正态分布,这个均值是0(方差是前面提到的噪声大小)
我们可以直接让目标类别具有一个自己的均值,测试生成的时候用新的类别分布进行采样,就可以生成这个类别的数据。
个人感觉
我感觉在NLP领域有很多的低资源任务,假如可以利用GAN和VAE做一些自动样本构造的工作可能会比较合适。
尤其是可以做到基于条件的生成,感觉可以对一些模型处理的很糟糕的输出来专门生成。比如之前我们做的对话摘要,就是一个低资源任务,数据集稀缺,同时存在人称转化等等的问题,假如可以构造出大量的人称转化对抗输出,就能从数据驱动的角度解决这些问题。
不过从直觉上来说,因为图像数据相对是连续的任务,而NLP是一个离散任务,所以生成样本的一些难题应该还是比较多的。。。
实现代码
from torch import nnimport torchimport torch.nn.functional as Fclass VAE(nn.Module):def __init__(self, input_dim=784, h_dim=400, z_dim=20):# 调用父类方法初始化模块的statesuper(VAE, self).__init__()self.input_dim = input_dimself.h_dim = h_dimself.z_dim = z_dim# 编码器 : [b, input_dim] => [b, z_dim]self.fc1 = nn.Linear(input_dim, h_dim) # 第一个全连接层self.fc2 = nn.Linear(h_dim, z_dim) # muself.fc3 = nn.Linear(h_dim, z_dim) # log_var# 解码器 : [b, z_dim] => [b, input_dim]self.fc4 = nn.Linear(z_dim, h_dim)self.fc5 = nn.Linear(h_dim, input_dim)def forward(self, x):"""向前传播部分, 在model_name(inputs)时自动调用:param x: the input of our training model [b, batch_size, 1, 28, 28]:return: the result of our training model"""batch_size = x.shape[0] # 每一批含有的样本的个数# flatten [b, batch_size, 1, 28, 28] => [b, batch_size, 784]# tensor.view()方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,# 返回的新tensor与原tensor共享内存,即更改一个,另一个也随之改变。x = x.view(batch_size, self.input_dim) # 一行代表一个样本# encodermu, log_var = self.encode(x)# reparameterization tricksampled_z = self.reparameterization(mu, log_var)# decoderx_hat = self.decode(sampled_z)# reshapex_hat = x_hat.view(batch_size, 1, 28, 28)return x_hat, mu, log_vardef encode(self, x):"""encoding part:param x: input image:return: mu and log_var"""h = F.relu(self.fc1(x))mu = self.fc2(h)log_var = self.fc3(h)return mu, log_vardef reparameterization(self, mu, log_var):"""Given a standard gaussian distribution epsilon ~ N(0,1),we can sample the random variable z as per z = mu + sigma * epsilon:param mu::param log_var::return: sampled z"""sigma = torch.exp(log_var * 0.5)eps = torch.randn_like(sigma)return mu + sigma * eps # 这里的“*”是点乘的意思def decode(self, z):"""Given a sampled z, decode it back to image:param z::return:"""h = F.relu(self.fc4(z))x_hat = torch.sigmoid(self.fc5(h)) # 图片数值取值为[0,1],不宜用ReLUreturn x_hat
参考文献
理论知识来源:
https://kexue.fm/archives/5253
代码来源:
https://blog.csdn.net/qq_41196612/article/details/109528221

若有收获,就点个赞吧
0 人点赞
