Insight & target problem
很多摘要模型会产生幻视
幻视中其实有一些是Factual的
模型在得到Source支撑的时候,生成Entity的概率叫后验概率
在没有source支持的时候,生成Entity的概率叫先验概率
后验概率大于先验概率的多少说明了模型依赖了Source多少,进而可以推断出所谓的事实一致性
Solution
把entity mask,然后用BART恢复,进而训练一个MLM
然后用这个MLM给样本赋值上先,后验概率。加上一个overlap的feature
用KNN把这个feature预测出是不是事实一致
Highlight
标注了BART在Xsum的一些生成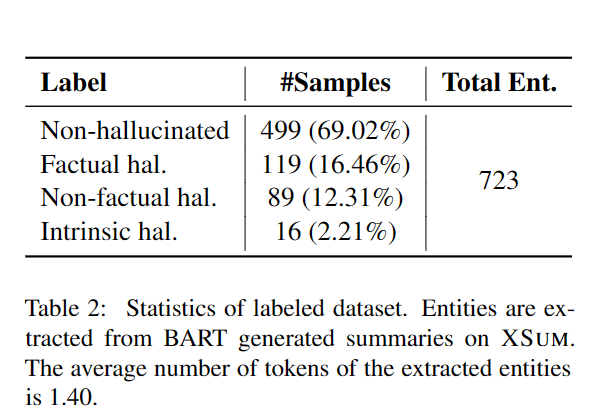
发现有问题的幻视实体里,有一半是事实一致的
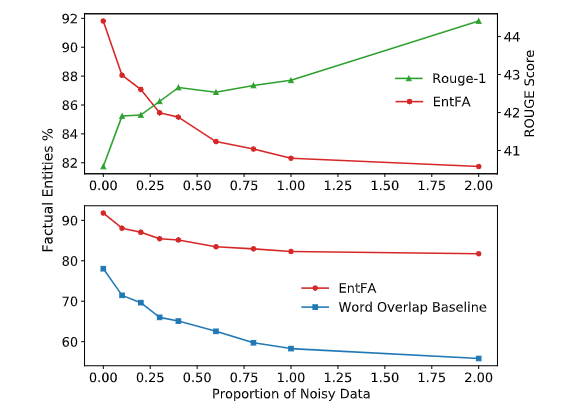
Noise data使得模型获得了更好的ROUGE,说明了MLE优化ROUGE可能有损事实一致性
Noise data多了,基于简单的Overlap的方法就不够有效,因为有更多的是需要推断的。
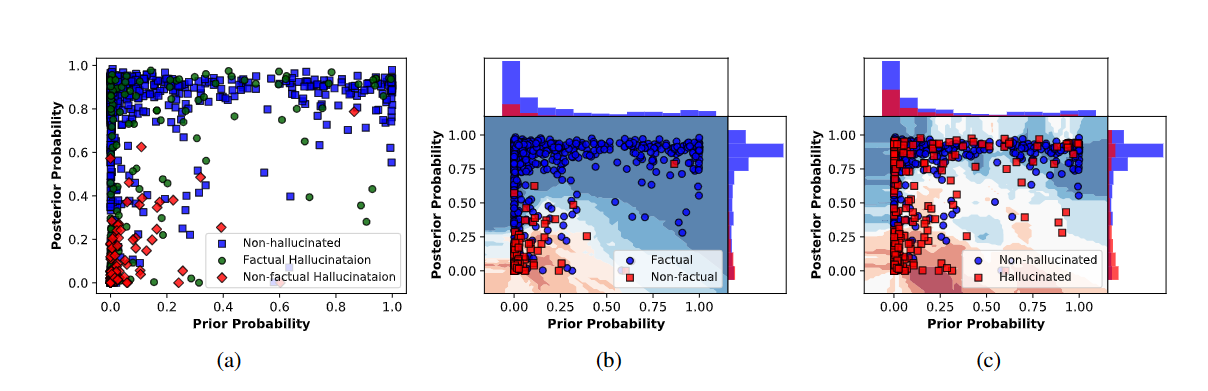
可视化了概率分布,可以看到红色的一般是不正确的幻视,低先验,低后验,既不会被外部知识支持,也不会被内部知识支持,绿色的是正确的幻视,高先验,被外部知识支持。蓝色的是非幻视,高后验,被文本支持。
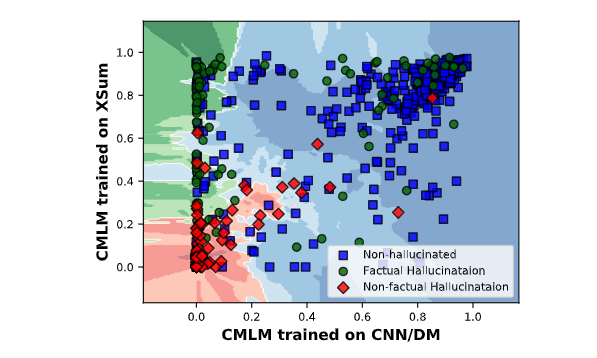
最后探究了知识学习的地方,就是在Xsum上fine-tuing的CMLM和CNNDM的CMLM在Xsum上比较
于是发现了对于非事实的幻视和非幻视,二者差不多
但是在事实一致幻视上,Xsum更容易给出高先验,因为背景知识学习于Fine-tuing阶段
Others

若有收获,就点个赞吧
0 人点赞
