Insight & target problem
现在很多摘要评估算法
因此提出一个算法和数据集来评估和分析这一些评估算法,以便于后面进一步的发展和改进
Solution
首先是选择了分析的对象
主要可以分为两个类别
- 把评估任务转化为一个自然语言推断任务
- 把评估任务转化为一个QA任务
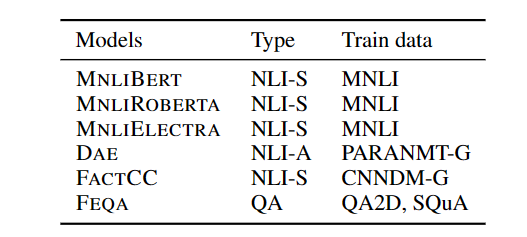
对于评测数据,首先现存的数据就有四个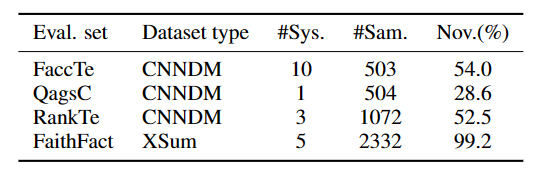
然后进一步的做了case study,分析了一下常见的评测错误
- VANs replacement
- Numerical inference
- Entity coreference
- Missing details
- Paraphrase
- Background knowledge
- Truncate
然后统计了一下分布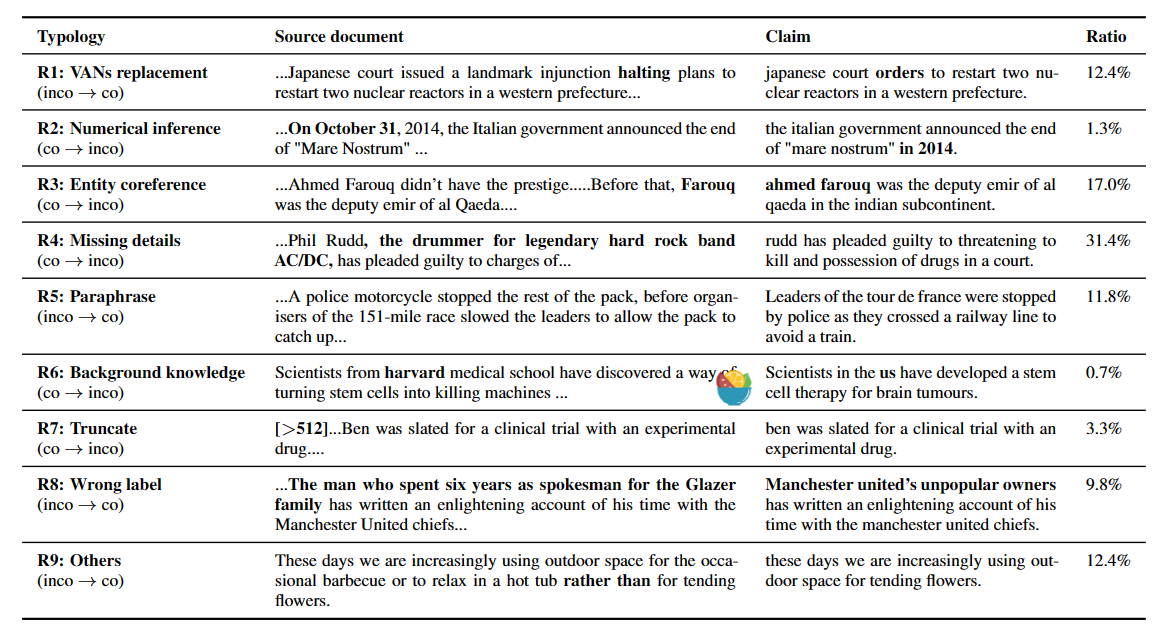
进一步的可以构造一个大的测试集,除了上面提到了4个数据集,进一步的把Document和reference作为claim可以再得到两个数据集,然后一共6个,加上4种transfomation可以得到24种数据集,然后测试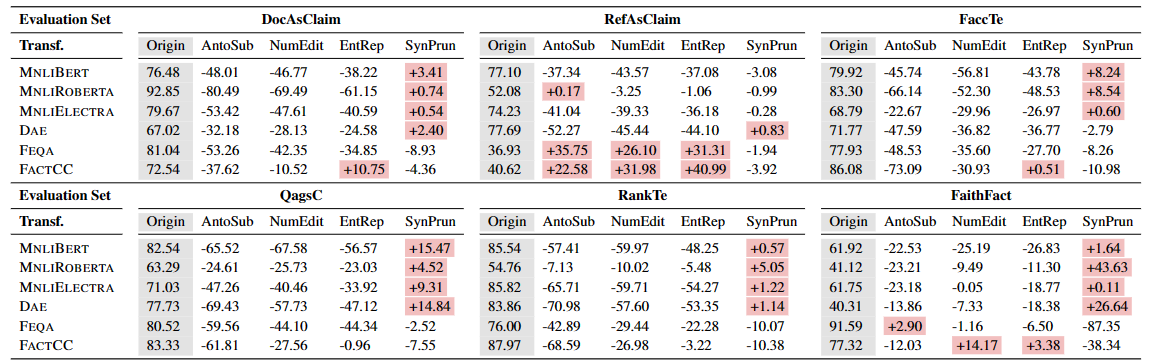
- FactCC对paraphrase不太友好,因为实现和训练导致的匹配不上,对应的就是在RefAsClaim上表现的很不好,然后反而是AntoSub和NumEdit,EntityRep因为施加之后会多出很多的标注为错误的摘要,反而是拯救了FactCC,这么看来FactCC的paraphrase能力还是很差。
- 对于Entity Rep,FactCC因为专门的数据增强方法训练,所以看起来还可以,衰落的比较少
- 模型对于数字的推断和变化都做的不好
- 因为MNLI的数据集有关于Paraphrase的内容,所以在SynaticPrun上,MNLI的算法都比较好,反而是FActCC因为之前的理由,表现的很差
进一步的,上面的增强算法可以用来增广训练集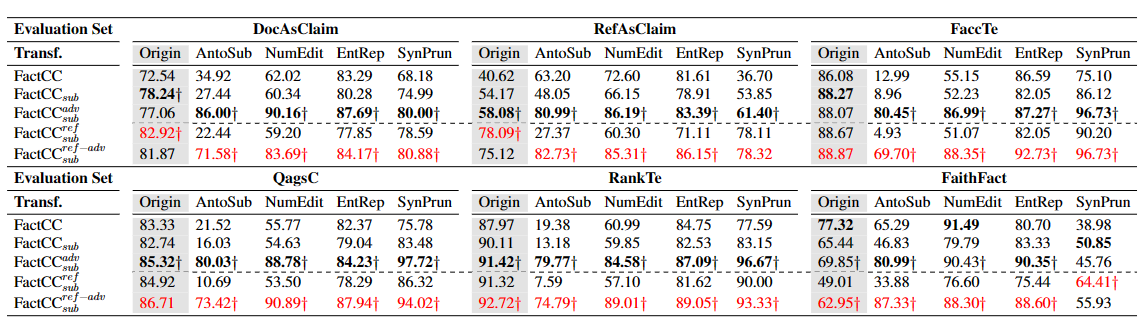
- 数据集的减小不会带来模型的退步
- 用RefAsClaim提升了模型的Paraphrase能力
- 进一步的使用对抗的方法进行增广之后可以提升模型的能力
Highlight
Others

若有收获,就点个赞吧
0 人点赞
