赛题

思路
- 由于数据脱敏且没有映射词表,使得难以使用bert模型进行处理
- 要解决的是相似度的判断,就计算相似度,然后和类型做损失函数
解决方案
LSTM
使用LSTM计算句子特征,使用距离公式计算相似度
两个句子分别输入且不共享除embedding外参数
然后结果和label做MSELoss计算
Bert
利用2G的无监督语料训练自己的bert模型
利用run_pretrain和另一个接口实现
实验
LSTM
初步实验结果
效果还行,没有过度的过拟合现象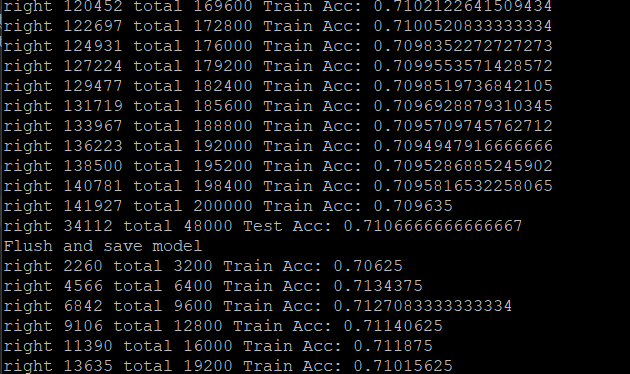
改进
- loss函数还是有点问题
- 可以实验Bi-LSTM
- 可以实验预训练Skip_Gram提供词向量
- 修改网络层,增加embedding维数等
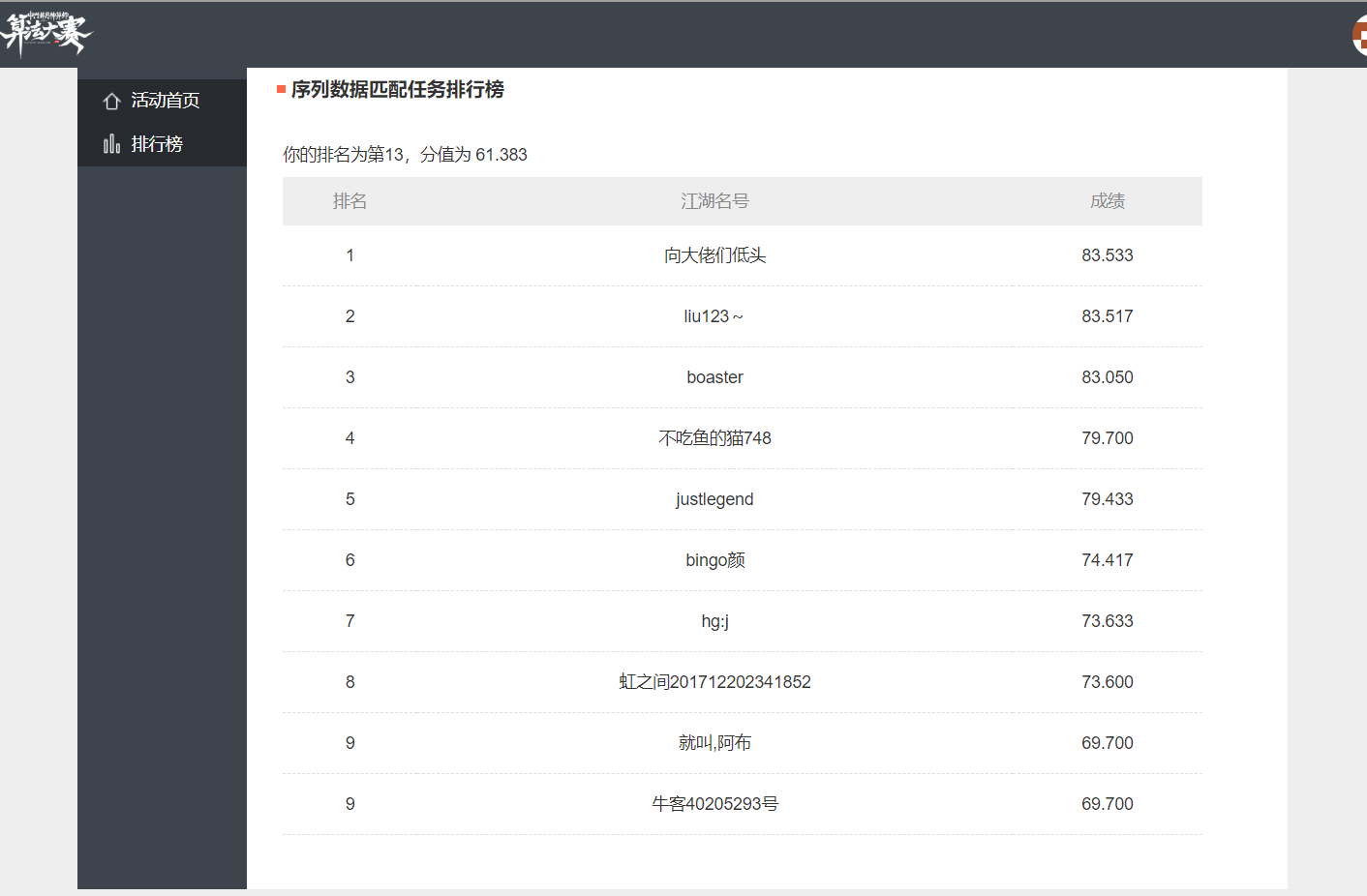
- 可以看到在本地训练和测试集上表现的都很不错,但是在实际中拉了跨,还有问题
BiLSTM
如昨天的认识,今天试一试BiLSTM,大体感觉收敛变慢了,但是最终的效果会略好一些
日志
2020/4/9
尝试了BiLSTM
看了调参的方法
重构了代码,发现代码里有大量的语义错(复制粘贴的锅)(就这样还能拿到60分。。。。)
消去了在LSTM后的dropout(感觉这个dropout会导致较多的信息丢失)
跑分创新高:重构代码前只去掉dropout: 67.683分

若有收获,就点个赞吧
0 人点赞
