赛题
https://www.kaggle.com/c/nlp-getting-started
解决方案
Bert Fine-tuning 使用base的预训练模型
基本思路
对于7600+条的训练数据,使用6000条做训练,1600+做测试
如果测试成绩达到最大值则刷新结果文件
设置为2分类问题
为了实现的简单,依旧只用text维度的数据
代码
import pandas as pdimport numpy as npfrom sklearn.preprocessing import MinMaxScalerimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchimport timeimport argparseimport os#main.pyfrom transformers import BertTokenizerfrom transformers import BertForSequenceClassificationfrom transformers import BertConfig#from transformers import BertPreTrainedModelfrom transformers import BertModelimport bert_USE_CUDA = torch.cuda.is_available()#USE_CUDA=Falsebase_path="D:\\New_desktop\\nlp-getting-started\\"read_train=pd.read_csv(base_path+'train.csv')train_data=read_train.iloc[0:read_train.shape[0],[1,2,3]]train_label=read_train.iloc[0:read_train.shape[0],[4]]train_label=[i for i in train_label.target]read_test = pd.read_csv(base_path + 'test.csv')test_data = read_test.iloc[0:read_train.shape[0], [1, 2, 3]]tokenizer = BertTokenizer.from_pretrained('bert-base-cased')train_data['text'] = [(tokenizer.encode(x, add_special_tokens=False)) for x in train_data.text]#input_ids = torch.tensor(tokenizer.encode("美国", add_special_tokens=True)).unsqueeze(0) # Batch size 1data_list=[]max_len=40'''for i in range(0, len(train_data)):if len(train_data.iloc[i]['text'])>max_len:max_len=len(train_data.iloc[i]['text'])print("max_strlen: ",max_len)'''for x in train_data.text:if len(x)>=max_len:x=x[0:39]while len(x)<max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)#x=torch.tensor(x)data_list.append(x)eval_list=data_list[6000:]data_list=data_list[0:6000]eval_label=train_label[6000:]train_label=train_label[0:6000]print("datalabel len: ",len(data_list))print("evallabel len: ",len(eval_list))print("datalist len: ",len(data_list))print("evallist len: ",len(eval_list))print("datalen: ",len(data_list[0]))train_label=torch.tensor(train_label)eval_label=torch.tensor(eval_label)traindata_tensor = torch.Tensor(data_list)eval_tensor= torch.Tensor(eval_list)#USE_CUDA=Falseif USE_CUDA:print("using GPU")traindata_tensor =traindata_tensor.cuda()train_label = train_label.cuda()eval_tensor=eval_tensor.cuda()eval_label = eval_label.cuda()def get_train_args():parser=argparse.ArgumentParser()parser.add_argument('--batch_size',type=int,default=32,help = '每批数据的数量')parser.add_argument('--nepoch',type=int,default=30,help = '训练的轮次')parser.add_argument('--lr',type=float,default=0.001,help = '学习率')parser.add_argument('--gpu',type=bool,default=True,help = '是否使用gpu')parser.add_argument('--num_workers',type=int,default=2,help='dataloader使用的线程数量')parser.add_argument('--num_labels',type=int,default=2,help='分类类数')parser.add_argument('--data_path',type=str,default='./data',help='数据路径')opt=parser.parse_args()print(opt)return optdef get_model(opt):model = BertForSequenceClassification.from_pretrained('bert-base-cased',num_labels=opt.num_labels)#model = bert_.BertForSequenceClassification.from_pretrained('bert-base-cased', num_labels=opt.num_labels)#model = bert_LSTM.Net()return modeldef out_put(net,batchsize):test_list = []test_data['text'] = [(tokenizer.encode(x, add_special_tokens=False)) for x in test_data.text]max_len = 40i=0for x in test_data.text:i+=1if len(x) >= max_len:x = x[0:39]while len(x) < max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)# x=torch.tensor(x)test_list.append(x)print(i)test_data_tensor = torch.Tensor(test_list)if USE_CUDA:print("using GPU to out")test_data_tensor = test_data_tensor.cuda()result=[]with torch.no_grad():result_dataset = torch.utils.data.TensorDataset(test_data_tensor)result_dataloader = torch.utils.data.DataLoader(result_dataset, batch_size=batchsize, shuffle=False)index=0for X in result_dataloader:X=X[0]#print(type(X))#print(X.shape)if X.shape[0]!=batchsize:breakX = X.long()outputs = net(X)logits = outputs[:2]_, predicted = torch.max(logits[0].data, 1)#print("predicttype",type(predicted))#print(predicted)for i in range(len(predicted)):result.append(predicted[i])print(len(result))while len(result)<3263:result.append(0)df_output = pd.DataFrame()aux = pd.read_csv(base_path + 'test.csv')df_output['id'] = aux['id']df_output['target'] = resultdf_output[['id', 'target']].to_csv(base_path + 's1mple.csv', index=False)print("reset the result csv")def eval(net,eval_data, eval_label,batch_size,pre):net.eval()print("enter",net.state_dict()["classifier.bias"])dataset = torch.utils.data.TensorDataset(eval_data, eval_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=False)total=0correct=0with torch.no_grad():index = 0for X, y in train_iter:X = X.long()if X.size(0)!= batch_size:breakoutputs= net(X, labels=y)#print("enter2", net.state_dict()["classifier.bias"])loss, logits = outputs[:2]_, predicted = torch.max(logits.data, 1)total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = (((1.0*correct.numpy())/total))print("right",correct,"total",total,"Acc:",s)if s>pre:print("save ")out_put(net,batch_size)return sdef train(net, train_data, train_label,eval_tensor,eval_label,num_epochs, learning_rate, batch_size):net.train()optimizer = optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0)dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)pre=0for epoch in range(num_epochs):correct = 0total=0iter = 0for X, y in train_iter:iter += 1X = X.long()if X.size(0)!= batch_size:breakoptimizer.zero_grad()#print(type(y))#print(y)outputs= net(X, labels=y)loss, logits = outputs[0],outputs[1]_, predicted = torch.max(logits.data, 1)#print("predicted",predicted)#print("answer", y)loss.backward()optimizer.step()#print(outputs[1].shape)#print(output)#print(outputs[1])total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = ("Acc:%.3f" %((1.0*correct.numpy())/total))if iter %50==0:print("epoch ", str(epoch)," loss: ", loss.mean(),"right", correct, "total", total, "Acc:", s)torch.save(net.state_dict(), 'model.pth')print("before",net.state_dict()["classifier.bias"])pre=eval(net,eval_tensor, eval_label,batch_size,pre)returnopt = get_train_args()model=get_model(opt)if USE_CUDA:model=model.cuda()#model.load_state_dict(torch.load('model.pkl'))"""for name,parameters in model.named_parameters():print(name,':',parameters.size())"""train(model,traindata_tensor,train_label,eval_tensor,eval_label,30,0.001,16)#model = torch.load('model.pkl')
结果
本地运行
训练的结果还不错,lr=0.001,batch_size=16,很快就得到收敛
大约在82%的正确率的时候拟合
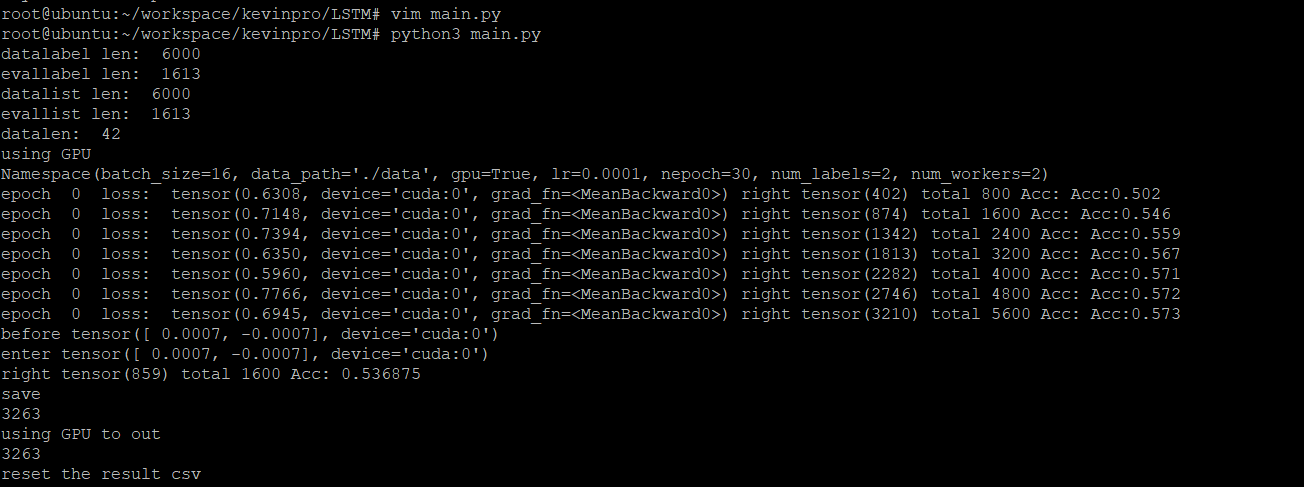
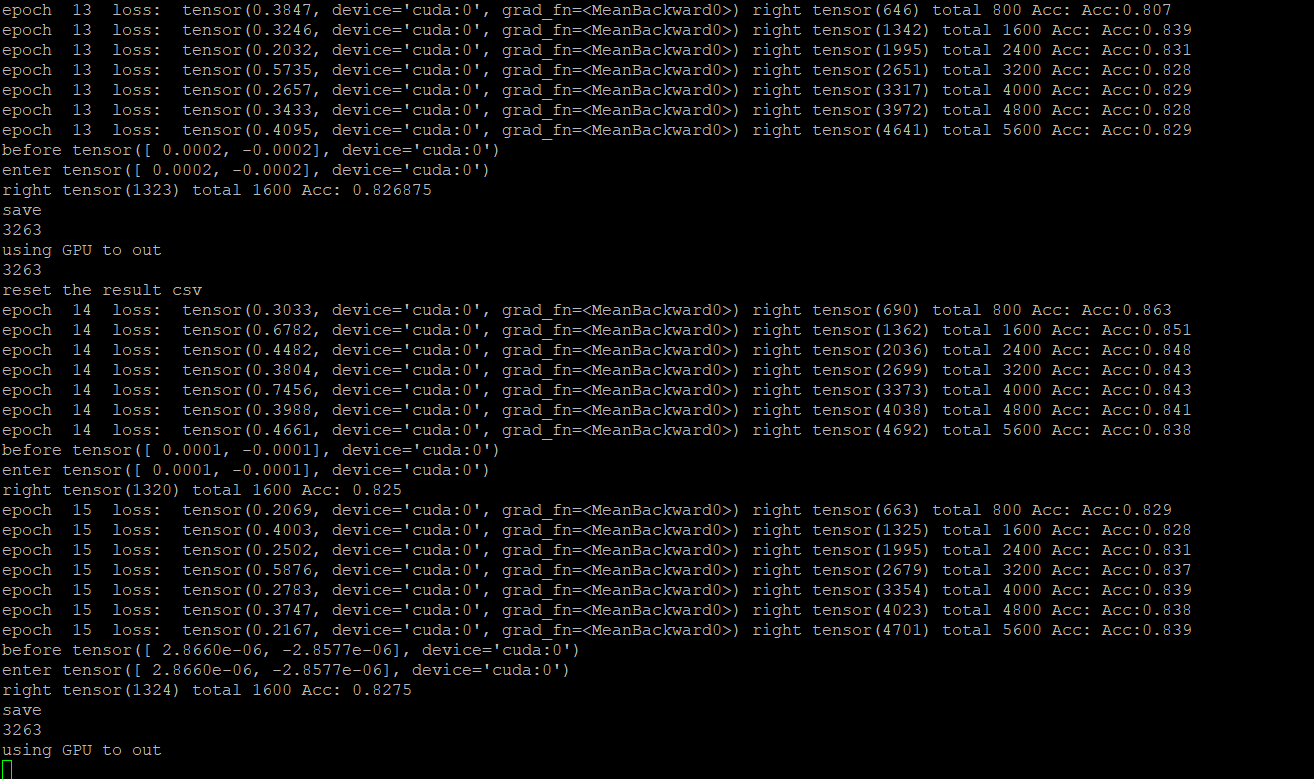
在线跑分
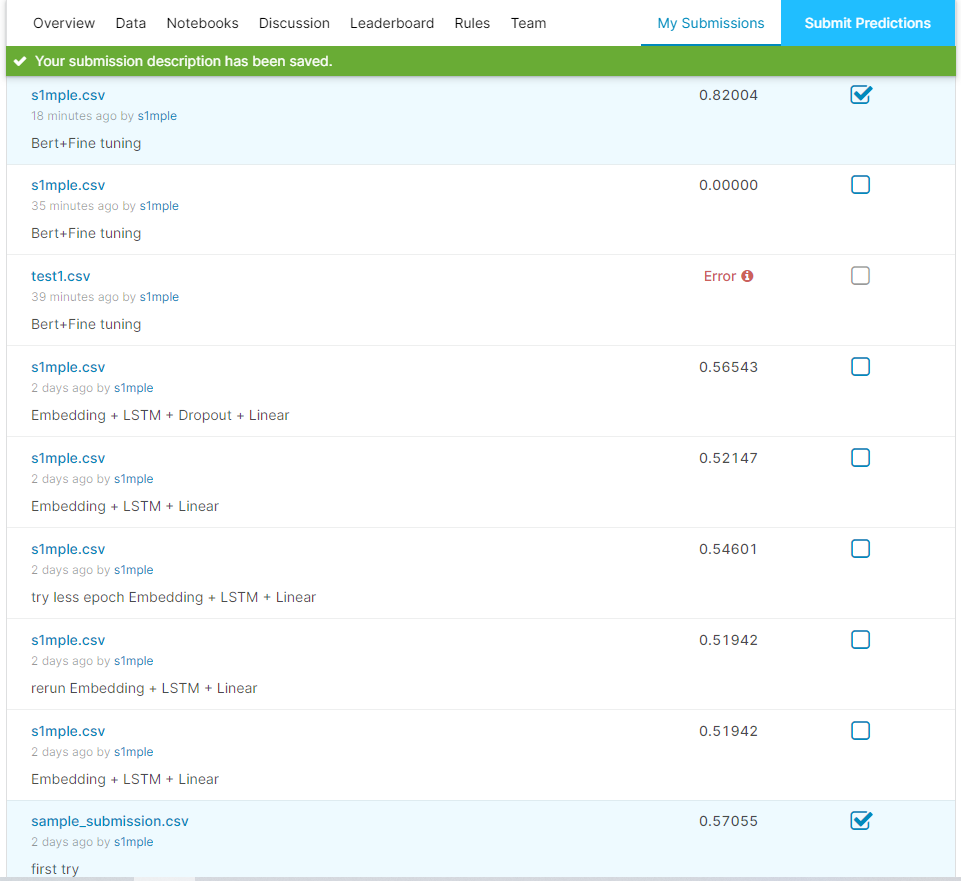
拿到了0.82分
排名 861 . Top29%

若有收获,就点个赞吧
0 人点赞
