Insight & target problem
现存的很多模型都存在事实不一致的问题
实际上很多的标注摘要都有很多来自于外部知识的描述(未出现于原文)进而导致了模型的错误
为了缓解这个问题,新建了一个数据集 MIRANEWS,这个数据集仍然做的是单文档摘要的问题,但是输入除了单文档之外,还增加了多个辅助文档,希望可以从辅助文档里获取进一步的信息支持(补充上所谓的外部知识)
论文提出
- 36%的标注摘要不够faithfully,出现了源文档没有的东西
- 使用了辅助文档输入之后,可以帮助27%在标注摘要里提到的东西
-
Solution
解决方法:
对于单个文档,文档里有链接,会链接到相关的新闻
- 链接的新闻也有一条对应的摘要
- 对于一个cluster(即一个新闻以及相关新闻)可以每一个作为source,其他的作为assist构造出很多数据
Highlight
Dataset info
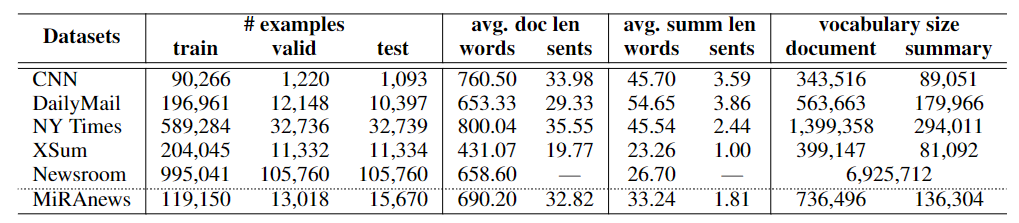
训练数据整体还是比较大的,文本较长,同时也有较大的词汇量
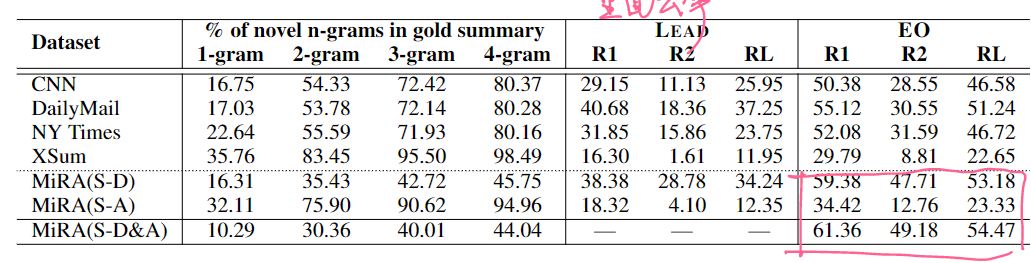
Extractive比较大,和CNNDM一样属于Copy比较强的数据集。同时可以看到利用了Assist之后,ROUGE进一步提提升,说明Assist里是存在有一些更加和Reference贴近的表达的。
当然只用文档比只用Assist高,即原文还是富含了最多的摘要所需的信息的。
does Assist input help?
前面的Oracle已经证明了辅助文档里是存在有一些更恰当的表达的,作者还有一些其他的策略来证明
Summary Fact-weights:表达了一种一致性,和reference summary的一致性
AsstRate:Assist输入的一致性高于文档输入的一致性的比例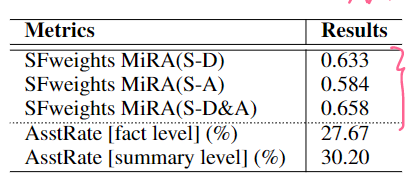
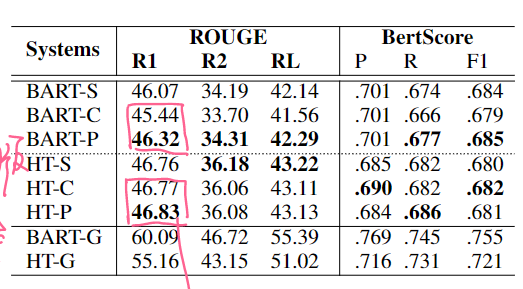
Basic Model Test
- -S:只用原始的输入
- -C:把Assist input拼接到后面(由于长度过长,各自做了截断)
- -P:先用一些内容选择算法对Assist处理,然后拼接(简单的说就是raw input和assist input做相似度,符合阈值的留下)
- -G:Oracle,把input和assist一起算ROUGE的Oracle组合
Human Study
假如只用单文档的输入,模型可以以靠自己在预训练里学会的一些外部知识来生成,但是相对很少。同时也会很容易和原文产生冲突。
使用了Concat之后,模型更多的关注了Assist里的内容,利用了更多,也减少了内部错误
对于Oracle版本的效果非常好,可以很好的利用Assist里的内容,减少了内部错误

若有收获,就点个赞吧
0 人点赞
