这一篇很长,公式比较多,没看明白,之后会再看一遍,这里记录一下主要的内容。主要的内容是图文转化(图指的是Graph而不是image)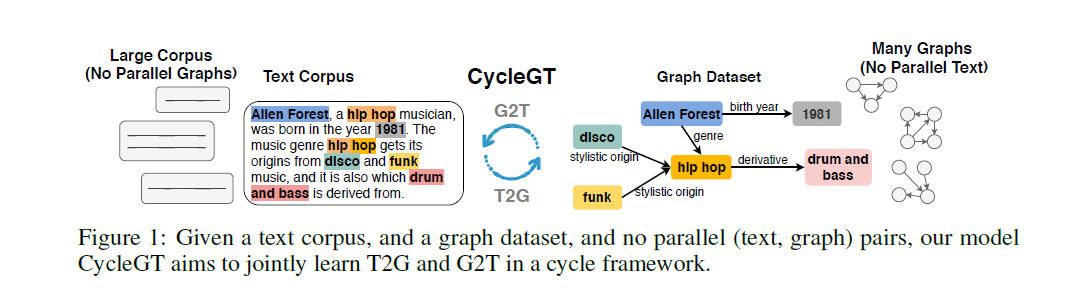
主要是图文转化(图指的是Graph而不是image)
和之前看的一篇摘要论文有点相似,之前看的摘要论文是把原文转化到Graph,然后对Graph做裁剪,最后Graph转化回到摘要。这里做的相当于是第一步和最后一步(中间的一步是抽取摘要,裁剪摘要的行为)
由于这种图文的平行语料少,所以在这里用了回译(NMT经常用的方法),就是把Graph转化到text,然后转回去,比较前后的Graph差异。对于Text也同理,这样就能够用这种语料去近似真实的监督语料的分布。后续还有一些不好理解的策略和引理没看明白。。。
个人的想法总结:
第一篇论文挺新奇的,目前对于预训练模型含有的信息的挖掘已经相对发展了一段时间,这种知识驱动的利用外部知识来辅助的思路相较之前数据驱动的方法不完全一样了。原来的数据驱动方法以及Pretrain model既要融合语法语言信息,又要融合常识信息,感觉还是有一些局限的。相对的NER和Relation Extraction的准确率还有大规模的三元组知识库都有了一定的发展。
第二篇论文感觉和第一篇也有一点点关系,因为把Text转化为Graph其实就是把Text里的有效三元组抽取出来,实体为节点,关系为边。然后另一面又强化从Graph中还原Text,可以看作是对Graph,也就是三元组的利用,也是一种抽取外部知识和利用外部知识的感觉。

若有收获,就点个赞吧
0 人点赞
