模型评估
Rouge变化曲线
(可能是由于模型参数没有及时更新导致Rouge曲线看起来比较奇怪)
Rouge值达到0.44左右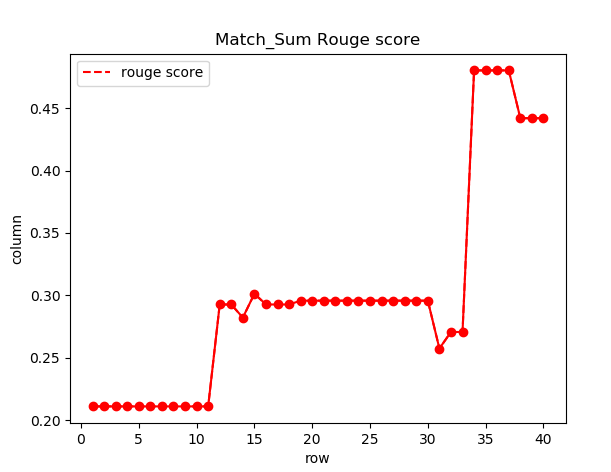
Margin RankingLoss 变化曲线
Loss稳定的下降并收敛在一个较低值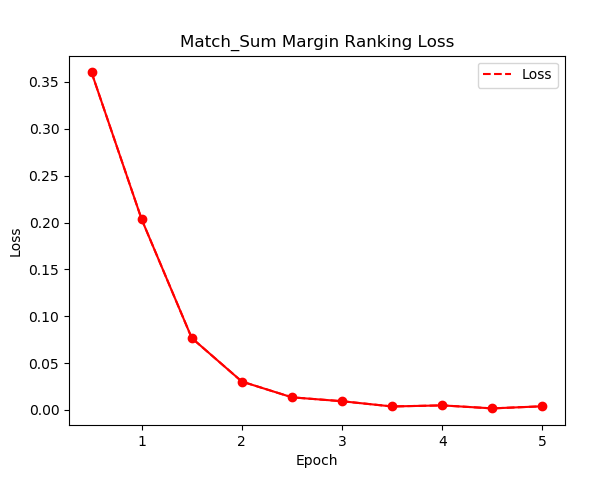
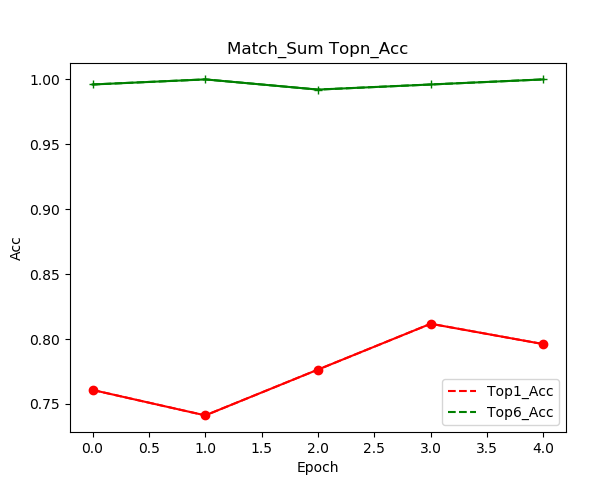
TopN-Acc 变化曲线
Topn的含义是摘要级别的打分第一在排序中的是否处于TopN的准确率
Top1就是摘要打分是在序列中的第一名,Top6是在前六
可以看到打分器准确率的提升(可能由于Bert本身有预训练,所以Top6一开始就很高)
模型改进
由于时间限制以及复现过程中踩了不少坑,未能对改进方法进行实践
这里提供若干的小的猜想
模型主要就是两个部分
- 构造候选摘要
-
构造候选摘要
这里可以优化的可能性
使用更有力的摘要选择(句子抽取)算法,包括lead,BertExt等等,强化候选句子集的质量
- 对抽取的句子做Sort的时候,用其他的句子评估方案作为排序标准(这个排序标准影响打分器性能)
- 不使用这里选句子构造候选的过程,考虑其他的高效摘要算法,结合Beam-Search构造出候选集
- 构造摘要的时候是对候选句子集做排列组合C(5,3)+C(5,2),实际上摘要的句子数目依旧是被限制了一定的值,这个或许和原论文里说的模型表现和数据集数据长度相关的原因?
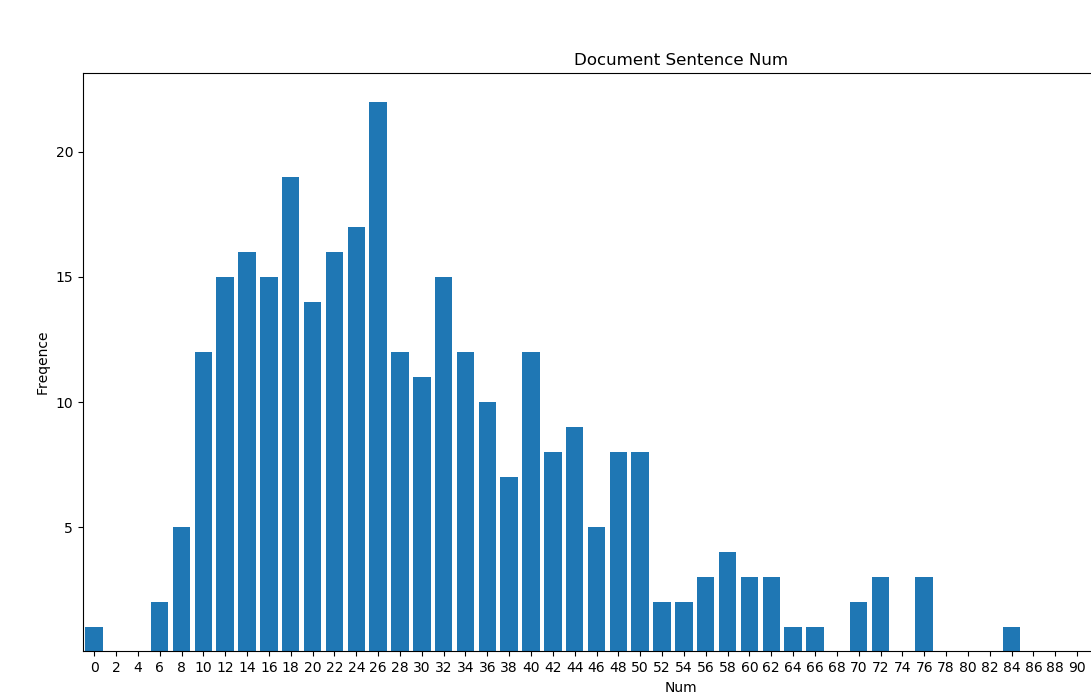
下图里可见标注的摘要句子长度多数分布在了4,5。抽取的数量影响最终的性能?
同时可以看到原文的长度符合一定的分布特征,但是分布较广,对摘要的长度可能有不同的要求?长原文长摘要?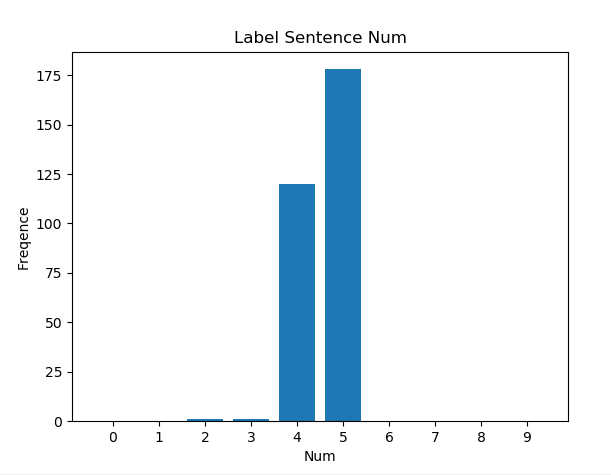
评分选择
- 打分器使用余弦相似度作为分数,优化对象是Bert作为encoder的表现,于是或许替换encoder有优化效果,如:ALBERT,Roberta,Bert+BiLSTM等
- 对于余弦相似度本身直接作为分数,使用其他的相似度计算工具欧式距离,余弦相似度(Cosine)皮尔逊相关系数(Pearson)修正余弦相似度(Adjusted Cosine)汉明距离(Hamming Distance)曼哈顿距离(Manhattan Distance)。或者是使用其他的神经网络方法做这个相似度的打分(句子相似度匹配任务,曾经接触过的ESIM模型,在Siamese-Bert的基础上加上二者的交互Attention之类的思路?)

若有收获,就点个赞吧
0 人点赞
