前端面试宝典之 React 篇 - 某一线大厂资深前端工程师 - 拉勾教育
在面试中,如果面试官让你列举一种 React 状态管理框架,你应该如何回答呢?这讲我会带你探讨这个问题。
破题
正如上一讲所提到的:横跨多个层级之间的组件仍然需要共享状态、响应变化。传统的状态提升方案难以高效地解决这个问题,比如 Context。
Context 存储的变量难以追溯数据源以及确认变动点。当组件依赖 Context 时,会提升组件耦合度,这不利于组件的复用与测试。
而状态管理框架就很好地解决了这些问题,才得以流行。所以在 React 的开发中,或多或少都会用到状态管理框架。对状态管理框架的掌握程度也就成了面试的必考点。
当然,虽然题目要求列举一种,但如果你能说出更多的状态管理框架,那肯定是加分的。这样可以证明你的开发经验足够丰富,且对社区流行很是了解。
承题
当前社区流行的状态管理框架有哪些呢?莫过于 Flux、Redux、Mobx 了。在回答这些框架本身的内容之外,你最好可以结合个人的思考,补充一些个人观点。
这样初步的框架就出来了。
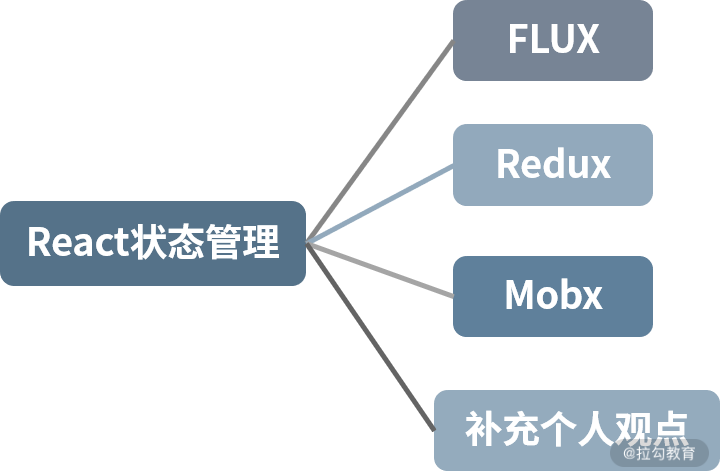
入手
Flux
Flux 给我的印象就是平地一声雷,有种 “天不生 Flux,状态管理如长夜” 的感觉。回顾历史,你会发现 Flux 如同 React 一样对业界影响巨大。如果你对 Flutter 与 SwiftUI 有了解的话,就能理解 React 对后起之秀的那种深远影响。Flux 同样如此,它提出了一种 MVC 以外的成功实践——单向数据流,这同样深远地影响了“后来人”。
2014 的 Facebook F8 大会上提出了一个观点,MVC 更适用于小型应用,但在面向大型前端项目时,MVC 会使项目足够复杂,即每当添加新的功能,系统复杂度就会疯狂增长。如下图所示,Model 与 View 的关联是错综复杂的,很难理解和调试,尤其是 Model 与 View 之间还存在双向数据流动。
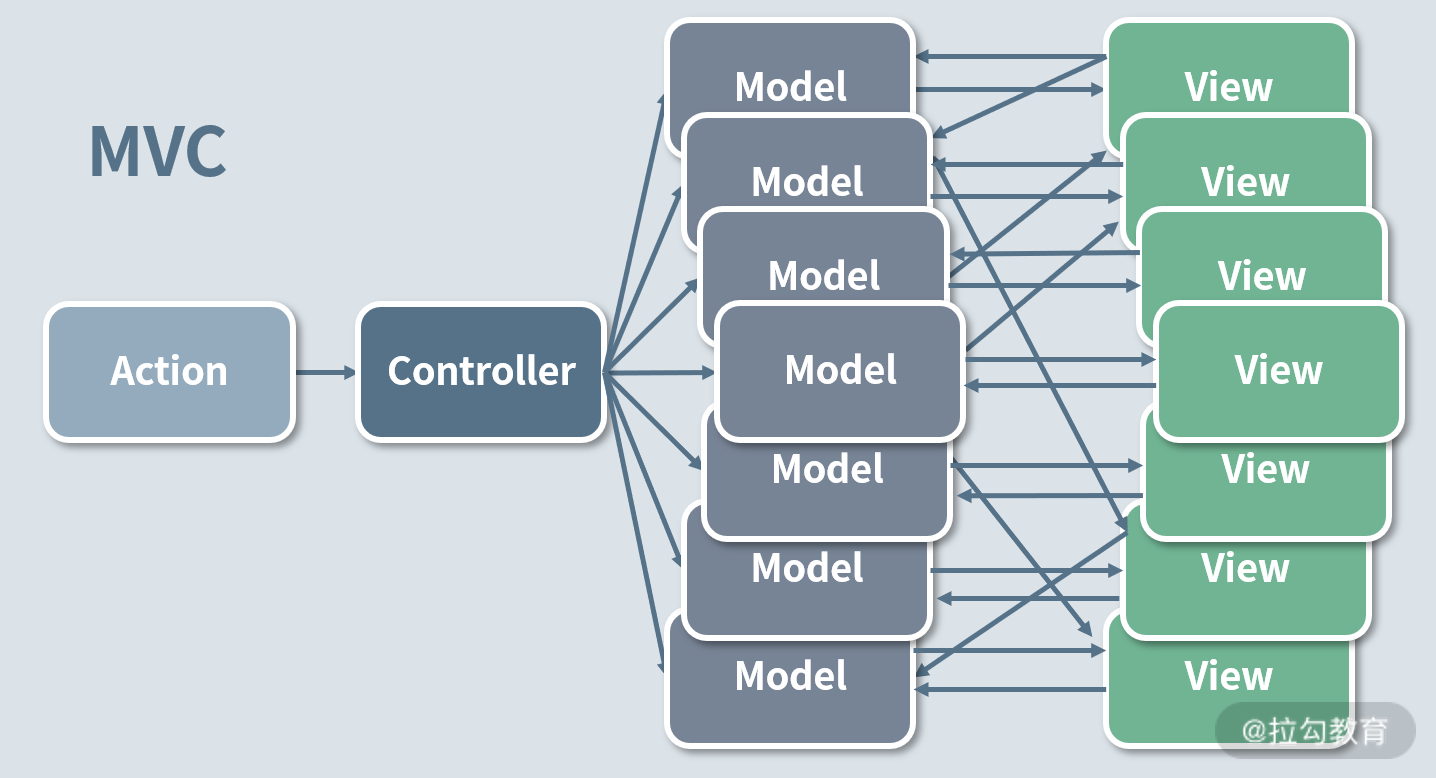
这对于接手老代码的人来说是个令人头疼的难题,因为他们害怕承担风险,所以不敢轻易修改代码。这也正是 MVC 模式被 Facebook 抛弃的原因。
所以他们提出了一种基于单向数据流的架构。如下图所示:
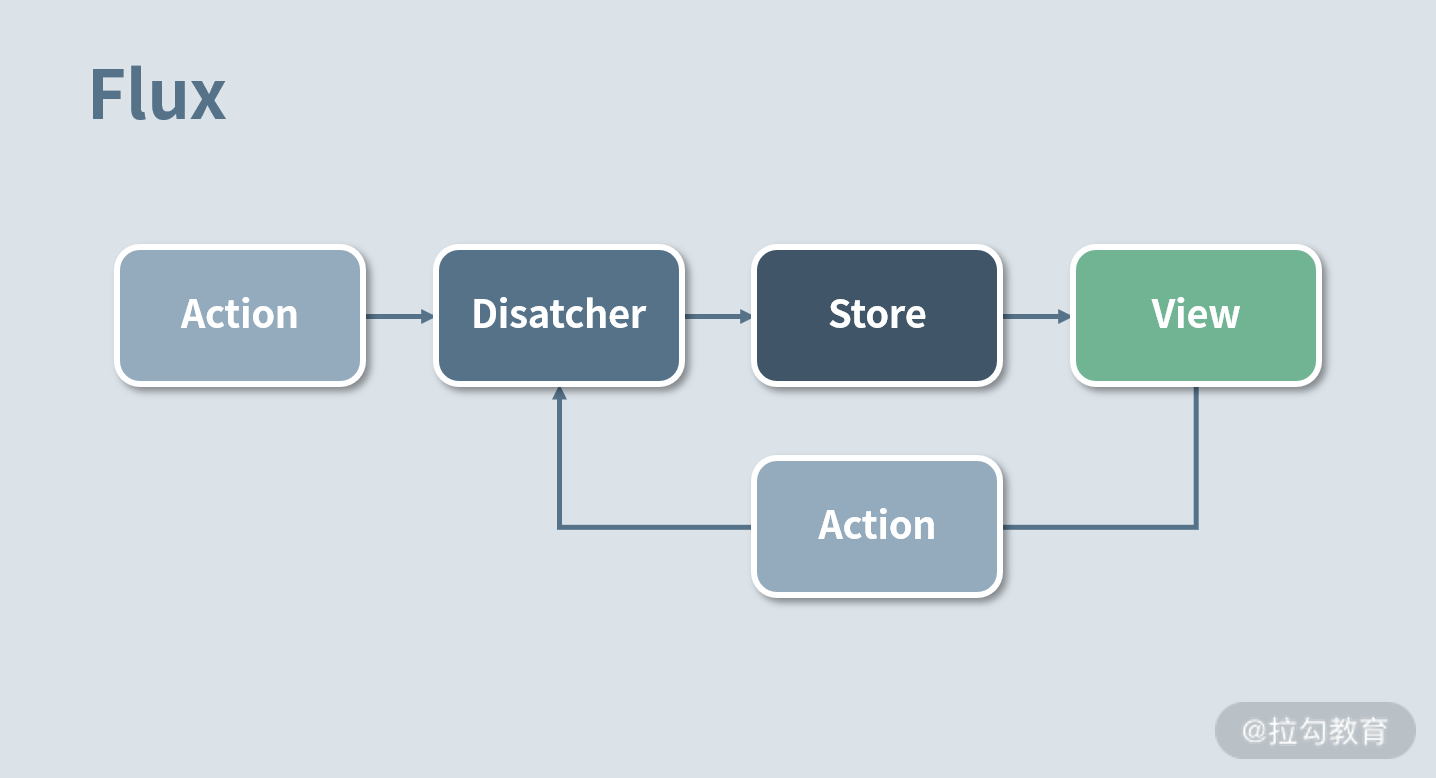
我先解释下上图中涉及的概念。
- View是视图层,即代码中的 React 组件。
- Store是数据层,维护了数据和数据处理的逻辑。
- Dispatcher是管理数据流动的中央枢纽。每一个 Store 提供一个回调。当 Dispatcher 接收一个 Action 时,所有的 Store 接收注册表中的 Action,然后通过回调产生数据。
- Action可以理解为一种事件通知,通常用 type 标记。
具体的流程是这样的,Store 存储了视图层所有的数据,当 Store 变化后会引起 View 层的更新。如果在视图层触发 Action,比如点击一个按钮,当前的页面数据值会发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层。由于 Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,会触发 View 层更新。
从应用场景来看,Flux 除了在 Facebook 内部大规模应用以外,业界很少使用。因为它的概念及样板代码相比后起之秀,还是有点多。从如今的视角看,Flux 可称为抛砖引玉的典范,开启了一轮状态管理的军备竞赛。
Redux
这场军备竞赛的佼佼者非 Redux 莫属。当提到 Redux,不得不提 Elm 这样一种传奇的语言。Elm虽然是一种语言,但实际上主要用于网页开发,它设计了一种 Model、View、Message、Update 的更新思路。

Elm 有着这样独特的设计:
- 全局单一数据源,不像 Flux 一样有多个 Store;
- 纯函数,可以保证输入输出的恒定;
- 静态类型,可以确保运行安全。
在 Redux 的文档中,毫不避讳地提到,自己借鉴了这个设计。
在 Flux 与 Elm 的基础上,Redux 确立了自己的 “三原则”。
- 单一数据源,即整个应用的 state 被储存在一棵 object tree 中,并且这个 object tree 只存在于唯一一个 Store 中。
- 纯函数 Reducer,即为了描述 Action 如何改变状态树 ,编写的一个纯函数的 Reducer。
- state 是只读的,唯一可以改变 state 的方法就是触发 Action,Action 是一个用于描述已发生事件的普通对象。
这三大原则使 Redux 的调试工具实现了时间回溯功能,通过录制回放 Action,完整重现了整个应用路径,这在当时引发了不小的轰动。下图中的 Redux DevTools 是开发中常用的 Redux 调试工具,界面中展示的内容就是时间回溯功能,可以查看每个操作对全局 Store 产生的变化。
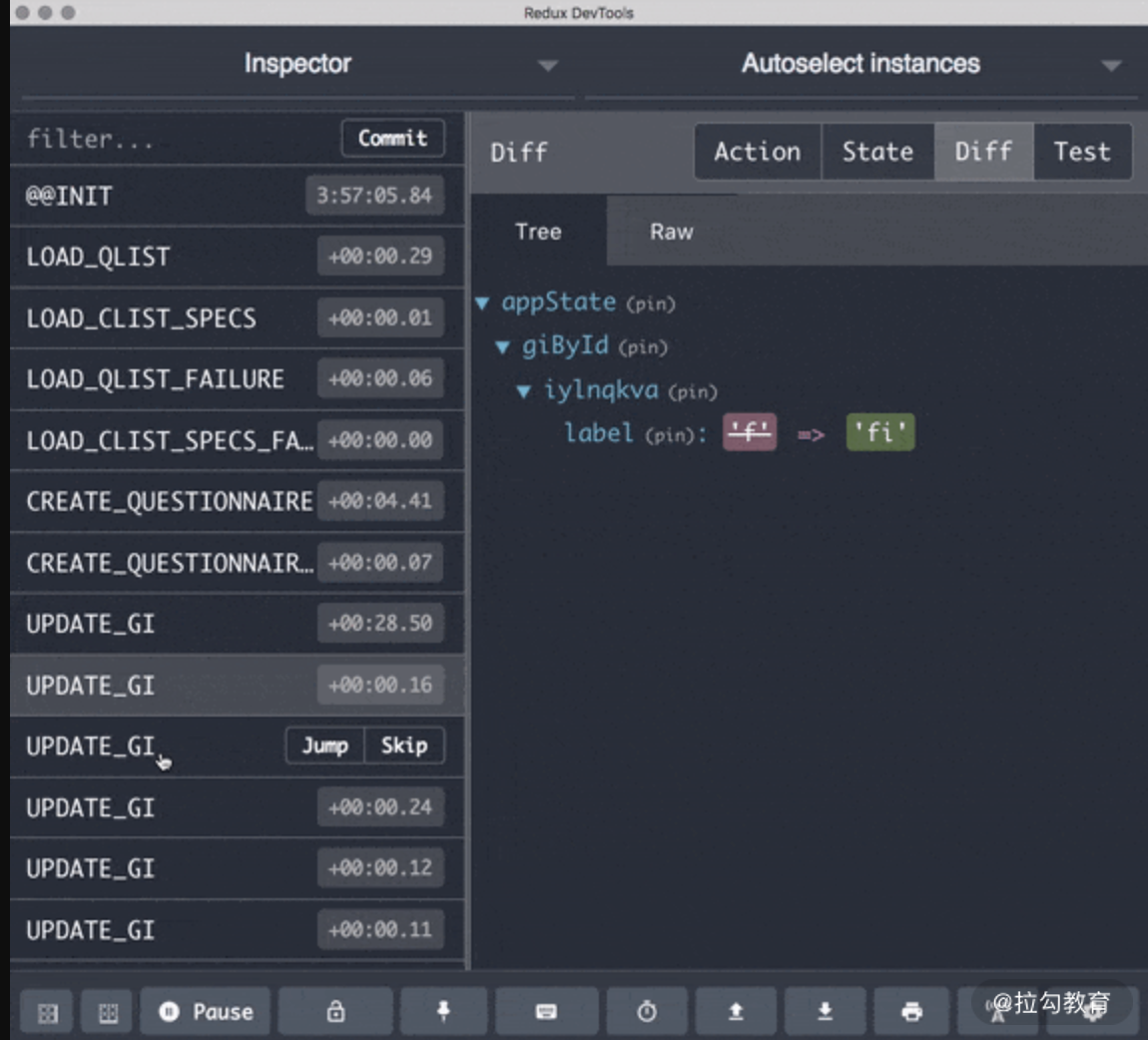
Redux 调试工具的时间回溯
在 Redux 社区中有一个经久不衰的话题,就是如何解决副作用(Side Effect)。在 16 年到 18 年之间,即使是在知乎,这也是前端最火的话题。每隔一段时间社区就会冒出一个新的方案,宣称对副作用有了最佳实践。
Redux 团队是这样论述 “副作用” 的:任何具备业务价值的 Web 应用必然要执行复杂的逻辑,比如 AJAX 请求等异步工作,这类逻辑使函数在每次的执行过程中,产生不同的变化,这样与外界的交互,被称为“副作用”。一个常见的副作用的例子是这样的,你发一个网络请求,需要界面先显示 Loading,再根据请求是否成功,来决定显示数据还是显示报错信息,你会发现在整个过程中,异步操作在 Redux 中无从添加,因为 Redux 本身深受函数式编程的影响,导致:
- 所有的事件都收拢 Action 去触发;
- 所有的 UI 状态都交给 Store 去管理;
- 所有的业务逻辑都交由 Reducer 去处理。
在这里 Action、Reducer 是纯函数,Store 也只是一个 state 状态树,都不能完成处理副作用的操作。
真正可以解决副作用的方案主要分为两类:
- 在 Dispatch 的时候有一个middleware 中间件层,拦截分发的Action并添加额外的复杂行为,还可以添加副作用;
- 允许 Reducer 层直接处理副作用。
你可以看出,这两类方案并没有把副作用从代码中消除,而是通过不同的方式转嫁到不同的层级中。对于每一类我们都看一下主流的解决方案。
第一类中,流行的方案是 Redux-thunk,其作用是处理异步 Action,它的源码在面试中经常被要求独立编写。
function createThunkMiddleware(extraArgument) {return ({ dispatch, getState }) => (next) => (Action) => {if (typeof Action === 'function') {return Action(dispatch, getState, extraArgument);}return next(Action);};}const thunk = createThunkMiddleware();thunk.withExtraArgument = createThunkMiddleware;export default thunk;
如上代码所示,Redux-thunk 通过添加中间件来判断 Action 是否为函数:
- 如果是函数,则 Dispatch,将当前的整个 state 以及额外参数传入其中;
- 否则就继续流转 Action。
这是一个最早最经典的处理 Redux 副作用的方案,你还可以自己去自定义 Store 的 middleware。那如果 Action 是一个数组,或者是一个 promise ,该怎么处理呢?这都可以实现。因为社区中 Action 可以是数组,可以是 promise,还可以是迭代器,或者 rxjs,比如 Redux-Saga、Redux-Promise、Redux-Observable 等。
第二类方案相对冷门很多,但从设计上而言,思考得却更加深刻。比如 Redux Loop 就深入地借鉴了 Elm。在 Elm 中副作用的处理在 update 层,这样的设计叫分形架构。如下代码所示:
import { loop, Cmd } from 'redux-loop';function initAction(){return {type: 'INIT'};}function fetchUser(userId){return fetch(`/api/users/${userId}`);}function userFetchSuccessfulAction(user){return {type: 'USER_FETCH_SUCCESSFUL',user};}function userFetchFailedAction(err){return {type: 'USER_FETCH_FAILED',err};}const initialState = {initStarted: false,user: null,error: null};function Reducer(state = initialState, Action) {switch(Action.type) {case 'INIT':return loop({...state, initStarted: true},Cmd.run(fetchUser, {successActionCreator: userFetchSuccessfulAction,failActionCreator: userFetchFailedAction,args: ['123']}));case 'USER_FETCH_SUCCESSFUL':return {...state, user: Action.user};case 'USER_FETCH_FAILED':return {...state, error: Action.error};default:return state;}}
那什么是分形架构呢?这就需要提到分形架构:
如果子组件能够以同样的结构,作为一个应用使用,这样的结构就是分形架构。
分形架构的好处显而易见,复用容易、组合方便。Redux Loop 就做出了这样的尝试,但在实际的项目中应用非常少,因为你很难遇到一个真正需要应用分形的场景。在真实的开发中,并没有那么多的复用,也没有那么多完美场景实践理论。
虽然 Redux Loop 在分形架构上做出了探索,但 Redux 作者并不是那么满意,他甚至写了一篇长文感慨,没有一种简单的方案可以组合 Redux 应用,并提了一个长久以来悬而未决的 issue。
最后就是关于 Redux 的一揽子解决方案。
关于这两个方案,你可以参考我给的代码进行学习,这里就不详细讲解了。
Mobx
从 Redux 深渊逃离出来,现在可以松口气了,进入 Mobx。如果你喜欢 Vue,那么一定会爱上 Mobx;但是如果喜欢 Redux,那你一定会恨它。不如先抛下这些,看看官方示例:
import {observable, autorun} from 'mobx';var todoStore = observable({todos: [],get completedCount() {return this.todos.filter(todo => todo.completed).length;}});autorun(function() {console.log("Completed %d of %d items",todoStore.completedCount,todoStore.todos.length);});todoStore.todos[0] = {title: "Take a walk",completed: false};todoStore.todos[0].completed = true;
Mobx 是通过监听数据的属性变化,直接在数据上更改来触发 UI 的渲染。是不是一听就非常 “Vue”。那 Mobx 的监听方式是什么呢?
- 在 Mobx 5 之前,实现监听的方式是采用 Object.defineProperty;
- 而在 Mobx 5 以后采用了 Proxy 方案。
答题
通过以上的学习,我们可以答题了。
首先介绍 Flux,Flux 是一种使用单向数据流的形式来组合 React 组件的应用架构。
Flux 包含了 4 个部分,分别是 Dispatcher、 Store、View、Action。Store 存储了视图层所有的数据,当 Store 变化后会引起 View 层的更新。如果在视图层触发一个 Action,就会使当前的页面数据值发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层,Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,触发 View 层更新。
Flux 的优点是单向数据流,解决了 MVC 中数据流向不清的问题,使开发者可以快速了解应用行为。从项目结构上简化了视图层设计,明确了分工,数据与业务逻辑也统一存放管理,使在大型架构的项目中更容易管理、维护代码。
其次是 Redux,Redux 本身是一个 JavaScript 状态容器,提供可预测化状态的管理。社区通常认为 Redux 是 Flux 的一个简化设计版本,但它吸收了 Elm 的架构思想,更像一个混合产物。它提供的状态管理,简化了一些高级特性的实现成本,比如撤销、重做、实时编辑、时间旅行、服务端同构等。
Redux 的核心设计包含了三大原则:单一数据源、纯函数 Reducer、State 是只读的。
Redux 中整个数据流的方案与 Flux 大同小异。
Redux 中的另一大核心点是处理 “副作用”,AJAX 请求等异步工作,或不是纯函数产生的第三方的交互都被认为是 “副作用”。这就造成在纯函数设计的 Redux 中,处理副作用变成了一件至关重要的事情。社区通常有两种解决方案:
第一类是在 Dispatch 的时候会有一个 middleware 中间件层,拦截分发的 Action 并添加额外的复杂行为,还可以添加副作用。第一类方案的流行框架有 Redux-thunk、Redux-Promise、Redux-Observable、Redux-Saga 等。
第二类是允许 Reducer 层中直接处理副作用,采取该方案的有 React Loop,React Loop 在实现中采用了 Elm 中分形的思想,使代码具备更强的组合能力。
除此以外,社区还提供了更为工程化的方案,比如 rematch 或 dva,提供了更详细的模块架构能力,提供了拓展插件以支持更多功能。
Redux 的优点很多:结果可预测;代码结构严格易维护;模块分离清晰且小函数结构容易编写单元测试;Action 触发的方式,可以在调试器中使用时间回溯,定位问题更简单快捷;单一数据源使服务端同构变得更为容易;社区方案多,生态也更为繁荣。
最后是 Mobx,Mobx 通过监听数据的属性变化,可以直接在数据上更改触发 UI 的渲染。在使用上更接近 Vue,比起 Flux 与 Redux 的手动挡的体验,更像开自动挡的汽车。Mobx 的响应式实现原理与 Vue 相同,以 Mobx 5 为分界点,5 以前采用 Object.defineProperty 的方案,5 及以后使用 Proxy 的方案。它的优点是样板代码少、简单粗暴、用户学习快、响应式自动更新数据让开发者的心智负担更低。
当然利用好知识导图,更有利于知识的学习。
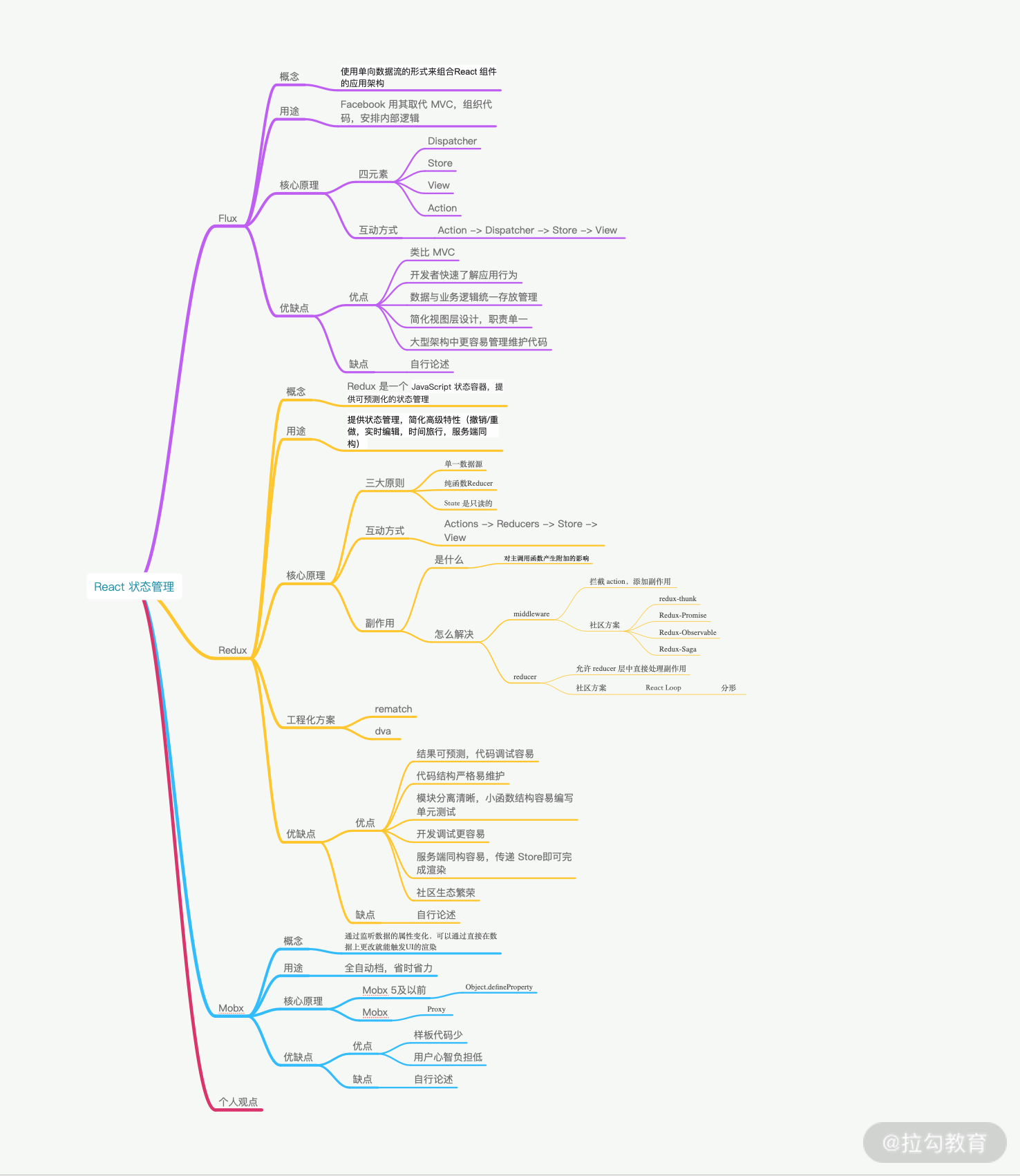
关于个人观点部分,你可以参考我以下观点。这里务必谨记,表达个人观点时,切忌对技术栈踩一捧一,容易引发面试官反感。
我认为 Flux 的设计更偏向 Facebook 内部的应用场景,Facebook 的方案略显臃肿,拓展能力欠佳,所以在社区中热度不够。而 Redux 因为纯函数的原因,碰上了社区热点,简洁不简单的 API 设计使社区疯狂贡献发展,短短数年方案层出不穷。但从工程角度而言,不是每一个项目都适用单一数据源。因为很多项目的数据是按页面级别切分的,页面之间相对隔绝,并不需要共享数据源,是否需要 Redux 应该视具体情况而定。Mobx 在开发项目时简单快速,但应用 Mobx 的场景 ,其实完全可以用 Vue 取代。如果纯用 Vue,体积还会更小巧。
进阶
在现场面试中很容易让你徒手实现一个 Redux。在实现 Redux 的时候,需要注意两个地方。
- createStore。即通过 createStore,注入 Reducer 与 middleware,生成 Store 对象。
- Store 对象的 getState、subscribe 与 dispatch 函数。getState 获取当前状态树,subscribe 函数订阅状态树变更,dispatch 发送 Action。
在实现上尽量采用纯函数的实现方案。如果没有思路建议阅读 Redux 4.x 的代码。
总结
一涉及状态管理,内容就相当多了,在面试中也是非常浓厚的一笔。对于本讲梳理的知识导图请务必掌握,最好可以自己画一画;本讲中提到的代码也都要看一看,可以加深对概念的理解。因为大厂中的前端项目结构的复杂性高,一定会使用状态管理框架来规范模块划分与人工操作。所以在面试前,一定要确保能够完全消化本讲中的内容。
下一讲开始为你讲解渲染流程的内容,会相对轻松一些。

《大前端高薪训练营》
对标阿里 P7 技术需求 + 每月大厂内推,6 个月助你斩获名企高薪 Offer。点击链接,快来领取!

若有收获,就点个赞吧
0 人点赞
