前端基础建设与架构 - 前百度资深前端开发工程师 - 拉勾教育
今天我和你分享的话题和 Babel 相关。Babel 在前端中占有举足轻重的历史地位,几乎所有的大型前端应用项目都离不开 Babel 的支持。同时,Babel 不仅仅是一个工具,更是一个工具链(toolchain),是前端基建中绝对重要的一环。
对于很多前端工程师来说,你可能配置过 Babel,也可能看过一些关于 Babel 插件或原理的文章。但我认为,“配置工程师” 只是我们的起点,通过阅读几篇 Babel 插件编写的文章并不能让我们真正掌握 Babel 的设计思想和原理。
对于 Babel 的学习,不能停留在配置层面,我们需要从更高的角度认识 Babel 在工程上的方方面面和设计思想。这一讲就让我们深入 Babel 生态,了解前端基建工程中最重要的一环。
Babel 是什么
借用 Babel 官方的一句话简短介绍:
Babel is a JavaScript compiler.
Babel 其实就是一个 JavaScript 的 “编译器”。但是一个简单的编译器如何会成为影响前端项目的“大杀器” 呢?究其原因,主要是前端语言特性和宿主(浏览器 / Node.js 等)环境高速发展,但宿主环境对新语言特性的支持无法做到即时,而开发者又需要兼容各种宿主环境,因此语言特性的降级成为刚需。
另一方面,前端框架 “自定义 DSL”的风格越来越凸显,使得前端各种 “姿势” 的代码被编译为 JavaScript 的需求成为标配。因此 Babel 的职责半径越来越大,它需要完成以下内容:
- 语法转换,一般是高级语言特性的降级;
- Polyfill(垫片 / 补丁)特性的实现和接入;
- 源码转换,比如 JSX 等。
为了完成这些编译工作,Babel 不能大包大揽地实现一切,更不能用面条式毫无设计模式可言的方式来 Coding。因此,Babel 的设计,在工程化的角度上,需要秉承以下理念:
- 可插拔(Pluggable),比如 Babel 需要有一套灵活的插件机制,召集第三方开发者力量,同时还需要方便接入各种工具;
- 可调式(Debuggable),比如 Babel 在编译过程中,要提供一套 Source Map,来帮助使用者在编译结果和编译前源码之间建立映射关系,方便调试;
- 基于协定(Compact),Compact 可以简单翻译为基于协定,主要是指实现灵活的配置方式,比如你熟悉的 Babelloose 模式,Babel 提供 loose 选项,帮助开发者在 “尽量还原规范” 和“更小的编译产出体积”之间,找到平衡。
我们总结一下,编译是 Babel 的核心目标,因此它自身的实现基于编译原理,深入 AST(抽象语法树)来生成目标代码;同时,Babel 需要工程化协作,需要和各种工具(如 Webpack)相互配合,因此 Babel 一定是庞大复杂的。
接下来,我们继续深入 Babel,了解这个 “庞然大物” 的运作方式和实现原理。
Babel Monorepo 架构包解析
为了以最完美的方式支撑上述职责,Babel 的 “家族” 可谓枝繁叶茂。Babel 是一个使用 Lerna 构建的 Monorepo 风格的仓库,在其./packages目录下有 140 多个包,这些包我经过整合分类,并按照重要性筛选出来,可以用下面这张图片简单概括:
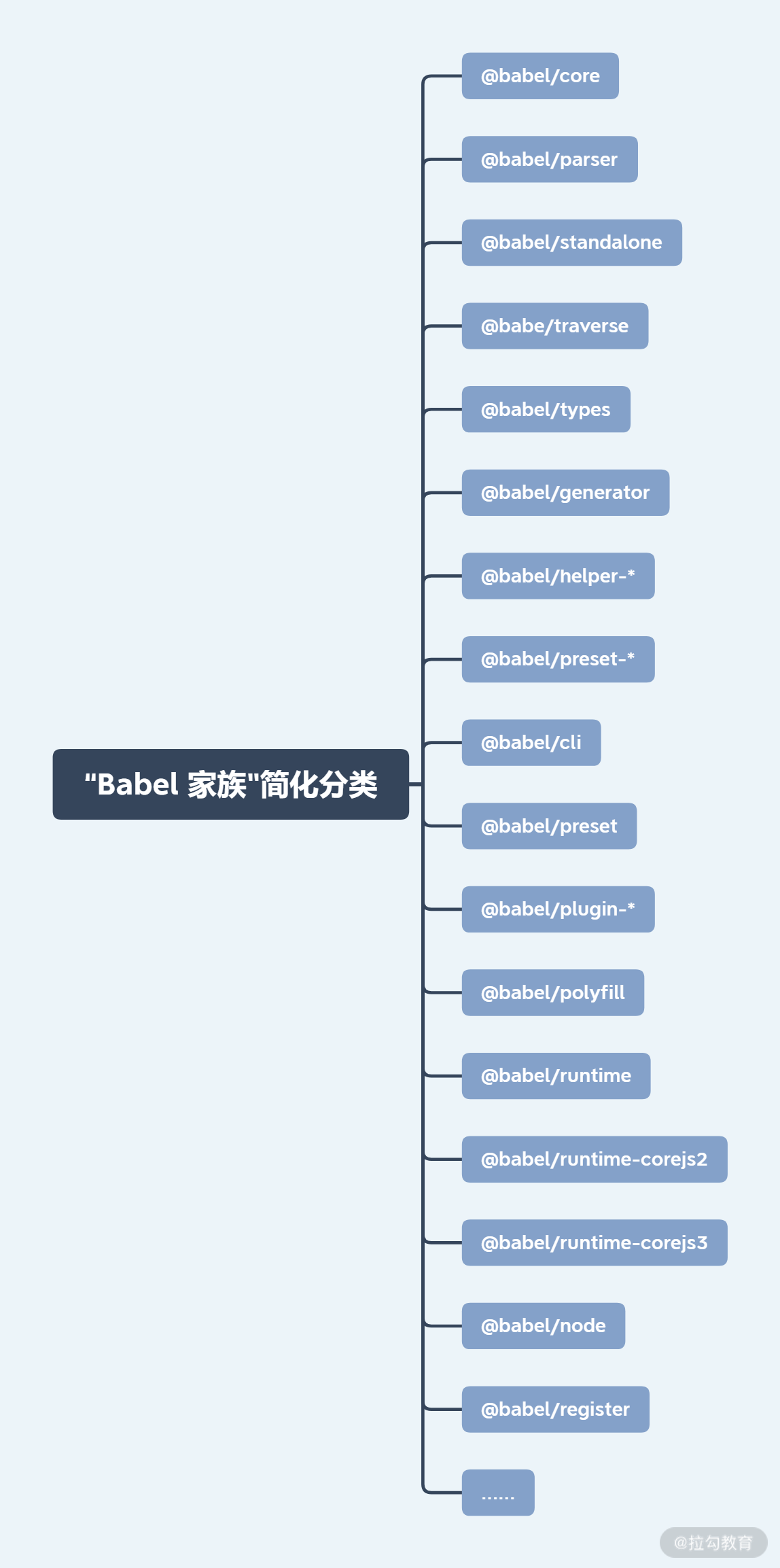
其中 Babel 部分包你可能见过或者使用过,但并不确定它们起到了什么作用;有些包,你可能都没有听说过。总的来说,可以分为两种情况:
- Babel 一些包的意义是在工程上起作用,因此对于业务来说是不透明的,比如一些插件可能被 Babel preset 预设机制打包对外输出;
- Babel 一些包是为了纯工程项目使用,或者运行目标在 Node.js 环境中,相对来讲你对这些会更熟悉。
下面,我会对一些 “Babel 家族重点成员” 进行梳理,并简单说说它们的基本原理。
@babel/core 是 Babel 实现转换的核心,它可以根据配置,进行源码的编译转换:
var babel = require("@babel/core");babel.transform(code, options, function(err, result) {result;});
@babel/cli 是 Babel 提供的命令行,它可以在终端中通过命令行方式运行,编译文件或目录。我们简单说一下它的实现原理:@babel/cli 使用了 commander 库搭建基本的命令行开发。以编译文件为例,其关键部分源码如下:
import * as util from "./util";const results = await Promise.all(_filenames.map(async function (filename: string): Promise<Object> {let sourceFilename = filename;if (cliOptions.outFile) {sourceFilename = path.relative(path.dirname(cliOptions.outFile),sourceFilename,);}sourceFilename = slash(sourceFilename);try {return await util.compile(filename, {...babelOptions,sourceFileName: sourceFilename,sourceMaps:babelOptions.sourceMaps === "inline"? true: babelOptions.sourceMaps,});} catch (err) {if (!cliOptions.watch) {throw err;}console.error(err);return null;}}),);
在上述代码中,@babel/cli 使用了util.compile方法执行关键的编译操作,而该方法定义在 babel-cli/src/babel/util.js 中:
import * as babel from "@babel/core";export function compile(filename: string,opts: Object | Function,): Promise<Object> {opts = {...opts,caller: CALLER,};return new Promise((resolve, reject) => {babel.transformFile(filename, opts, (err, result) => {if (err) reject(err);else resolve(result);});});}
由此可见,@babel/cli 负责获取配置内容,并最终依赖了 @babel/core 完成编译。
事实上,我们可以在 @babel/cli 的 package.json 中找到线索:
"peerDependencies": {"@babel/core": "^7.0.0-0"},
这一部分的源码在 peerDependencies 当中,你可以课后再次学习。
现在,你应该进一步体会到了 @babel/core 的作用,作为 @babel/cli 的关键依赖,@babel/core 提供了基础的编译能力。至于为什么在 @babel/cli 中,使用peerDependencies,你可以在 03 讲 “CI 环境上的 npm 优化及更多工程化问题解析”中找到答案。
我们花时间梳理 @babel/cli 和 @babel/core 包,希望帮助你对于 Babel 各个包之间的协同分工有个整体感知,这也是 Monorepo 风格仓库常见的设计形式。接下来,我们再继续看更多 “家族成员”。
@babel/standalone这个包非常有趣,它可以在非 Node.js 环境(比如浏览器环境)自动编译含有 text/babel 或 text/jsx 的 type 值的 script 标签,并进行编译,如下面代码:
<script src="https://unpkg.com/@babel/standalone/babel.min.js"></script><script type="text/babel">const getMessage = () => "Hello World";document.getElementById('output').innerHTML = getMessage();</script>
其工作原理藏在 babel-standalone 的核心源码中,最后的编译行为由:
import {transformFromAst as babelTransformFromAst,transform as babelTransform,buildExternalHelpers as babelBuildExternalHelpers,} from "@babel/core";
来提供。因此,我们又看到了另一个基于 @babel/core 的应用:@babel/standalone。
@babel/standalone 可以在浏览器中直接执行,因此这个包对于浏览器环境动态插入高级语言特性的脚本、在线自动解析编译非常有意义。我们知道的 Babel 官网也用到了这个包,JSFiddle、JS Bin 等也都是 @babel/standalone 的受益者。
我认为,在前端发展方向之一——Web IDE 和智能化方向上,相信类似的设计和技术将会有更多的施展空间,@babel/standalone 对于我们的现代化前端发展思路,应该有启发。
至此,我们看到了 @babel/core 被多个 Babel 包应用,而 @babel/core 的能力由更底层的 @babel/parser、@babel/code-frame、@babel/generator、@babel/traverse、@babel/types等包提供。这些 “家族成员” 提供了更基础的 AST 处理能力。
我们先看 @babel/parser,它是 Babel 用来对 JavaScript 语言解析的解析器。
@babel/parser 的实现主要依赖并参考了 acorn 和 acorn-jsx,典型用法:
require("@babel/parser").parse("code", {sourceType: "module",plugins: ["jsx","flow"]});
parse源码实现:
export function parse(input: string, options?: Options): File {if (options?.sourceType === "unambiguous") {options = {...options,};try {options.sourceType = "module";const parser = getParser(options, input);const ast = parser.parse();if (parser.sawUnambiguousESM) {return ast;}if (parser.ambiguousScriptDifferentAst) {try {options.sourceType = "script";return getParser(options, input).parse();} catch {}} else {ast.program.sourceType = "script";}return ast;} catch (moduleError) {try {options.sourceType = "script";return getParser(options, input).parse();} catch {}throw moduleError;}} else {return getParser(options, input).parse();}}
由此可见,require("@babel/parser").parse()方法可以返回给我们一个针对源码编译得到的 AST,这里的 AST 符合Babel AST 格式。
有了 AST,我们还需要对 AST 完成修改,才能产出编译后的代码。这就需要对 AST 进行遍历,此时 @babel/traverse 就派上用场了,使用方式如下:
traverse(ast, {enter(path) {if (path.isIdentifier({ name: "n" })) {path.node.name = "x";}}});
遍历的同时,如何对 AST 上指定内容进行修改呢?这就又要引出另外一个 “家族成员”,@babel/types 包提供了对具体的 AST 节点的修改能力。
得到了编译后的 AST 之后,最后一步:使用 @babel/generator 对新的 AST 进行聚合并生成 JavaScript 代码:
const output = generate(ast,{},code);
这样一个典型的 Babel 底层编译流程就出来了,如下图:
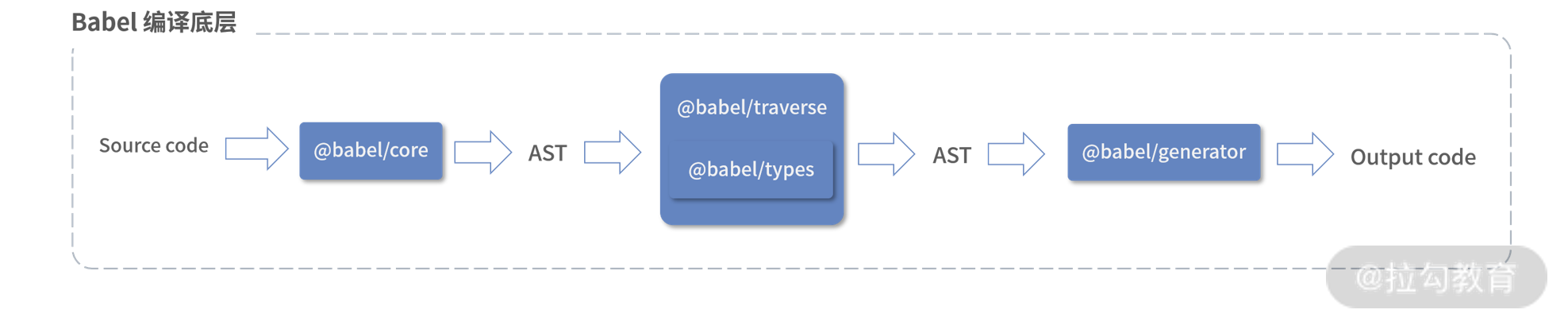
Babel 底层编译流程图
上图也是 Babel 插件运作实现的基础。基于 AST 的操作,Babel 将上述所有能力开放给插件,让第三方能够更方便地操作 AST,并聚合成最后编译产出的代码。
基于以上原理,Babel 具备了编译处理能力,但在工程中运用时,我们一般不会感知这些内容,你可能也很少直接操作 @babel/core、@babel/types 等,而应该对 @babel/preset-env 更加熟悉,毕竟 @babel/preset-env 是直接暴露给开发者在业务中运用的包能力。
在工程中,我们需要 Babel 做到的是编译降级,而这个编译降级一般通过 @babel/preset-env 来配置。@babel/preset-env 允许我们配置需要支持的目标环境(一般是浏览器范围或 Node.js 版本范围),利用 babel-polyfill 完成补丁的接入。结合上一讲内容,@babel/polyfill 其实就是 core-js 和 regenerator-runtime 两个包的结合,@babel/polyfill 源码层面,通过 build-dist.sh 脚本,利用 browserify 进行打包,参考源码:
#!/bin/shset -exmkdir -p distyarn browserify lib/index.js \--insert-global-vars 'global' \--plugin bundle-collapser/plugin \--plugin derequire/plugin \>dist/polyfill.jsyarn uglifyjs dist/polyfill.js \--compress keep_fnames,keep_fargs \--mangle keep_fnames \>dist/polyfill.min.js
注意:@babel/polyfill 目前已经计划废弃,新的 Babel 生态(@babel/preset-env V7.4.0 版本)鼓励开发者直接在代码中引入 core-js 和 regenerator-runtime。但是不管直接导入 core-js 和 regenerator-runtime,还是直接导入 @babel/polyfill 都是引入了全量的 polyfills,@babel/preset-env 如何根据目标适配环境,按需引入业务中所需要的 polyfills 呢?
事实上,@babel/preset-env 通过 targets 参数,按照 browserslist 规范,结 合core-js-compat,筛选出适配环境所需的 polyfills(或 plugins),关键源码:
export default declare((api, opts) => {const {bugfixes,configPath,debug,exclude: optionsExclude,forceAllTransforms,ignoreBrowserslistConfig,include: optionsInclude,loose,modules,shippedProposals,spec,targets: optionsTargets,useBuiltIns,corejs: { version: corejs, proposals },browserslistEnv,} = normalizeOptions(opts);let hasUglifyTarget = false;const targets = getTargets((optionsTargets: InputTargets),{ ignoreBrowserslistConfig, configPath, browserslistEnv },);const include = transformIncludesAndExcludes(optionsInclude);const exclude = transformIncludesAndExcludes(optionsExclude);const transformTargets = forceAllTransforms || hasUglifyTarget ? {} : targets;const compatData = getPluginList(shippedProposals, bugfixes);const modulesPluginNames = getModulesPluginNames({modules,transformations: moduleTransformations,shouldTransformESM: modules !== "auto" || !api.caller?.(supportsStaticESM),shouldTransformDynamicImport:modules !== "auto" || !api.caller?.(supportsDynamicImport),shouldTransformExportNamespaceFrom: !shouldSkipExportNamespaceFrom,shouldParseTopLevelAwait: !api.caller || api.caller(supportsTopLevelAwait),});const pluginNames = filterItems(compatData,include.plugins,exclude.plugins,transformTargets,modulesPluginNames,getOptionSpecificExcludesFor({ loose }),pluginSyntaxMap,);removeUnnecessaryItems(pluginNames, overlappingPlugins);const polyfillPlugins = getPolyfillPlugins({useBuiltIns,corejs,polyfillTargets: targets,include: include.builtIns,exclude: exclude.builtIns,proposals,shippedProposals,regenerator: pluginNames.has("transform-regenerator"),debug,});const pluginUseBuiltIns = useBuiltIns !== false;const plugins = Array.from(pluginNames).map(pluginName => {if (pluginName === "proposal-class-properties" ||pluginName === "proposal-private-methods" ||pluginName === "proposal-private-property-in-object") {return [getPlugin(pluginName),{loose: loose? "#__internal__@babel/preset-env__prefer-true-but-false-is-ok-if-it-prevents-an-error": "#__internal__@babel/preset-env__prefer-false-but-true-is-ok-if-it-prevents-an-error",},];}return [getPlugin(pluginName),{ spec, loose, useBuiltIns: pluginUseBuiltIns },];}).concat(polyfillPlugins);return { plugins };});
这部分内容你可以与上一讲 “core-js 及垫片理念:设计一个‘最完美’的 Polyfill 方案” 相结合,相信你会对前端 “按需 polyfill” 有一个更加清晰的认知。
至于 Babel 家族的其他成员,相信你也一定见过 @babel/plugin-transform-runtime,它可以重复使用 Babel 注入的 helpers 函数,达到节省代码大小的目的。
比如,对于这样一段简单的代码:
Babel 在编译后,得到:
function _instanceof(left, right) {if (right != null && typeof Symbol !== "undefined" && right[Symbol.hasInstance]) {return !!right[Symbol.hasInstance](left);}else {return left instanceof right;}}function _classCallCheck(instance, Constructor) {if (!_instanceof(instance, Constructor)) { throw new TypeError("Cannot call a class as a function"); }}var Person = function Person() {_classCallCheck(this, Person);};
其中_instanceof和_classCallCheck都是 Babel 内置的 helpers 函数。如果每个 class 编译结果都在代码中植入这些 helpers 具体内容,对产出代码体积就会有明显恶化影响。在启用 @babel/plugin-transform-runtime 插件后,上述代码的编译结果可以变为:
var _interopRequireDefault = require("@babel/runtime/helpers/interopRequireDefault");var _classCallCheck2 = _interopRequireDefault(require("@babel/runtime/helpers/classCallCheck"));var Person = function Person() {(0, _classCallCheck2.default)(this, Person);};
从上述代码我们可以看到,_classCallCheck 作为模块依赖被引入文件中,基于打包工具的 cache 能力,从而减少了产出代码体积。需要注意的是,观察以上代码,_classCallCheck2 这个 helper 由 @babel/runtime 给出,这就又由一条线,牵出来了 Babel 家族的另一个包:@babel/runtime。
@babel/runtime含有 Babel 编译所需的一些运行时 helpers 函数,供业务代码引入模块化的 Babel helpers 函数,同时它提供了 regenerator-runtime,对 generator 和 async 函数进行编译降级。
总结一下:
- @babel/plugin-transform-runtime 需要和 @babel/runtime 配合使用;
- @babel/plugin-transform-runtime 用于编译时,作为 devDependencies 使用;
- @babel/plugin-transform-runtime 将业务代码编译,引用 @babel/runtime 提供的 helpers,达到缩减编译产出体积的目的;
- @babel/runtime 用于运行时,作为 dependencies 使用。
另外,@babel/plugin-transform-runtime 和 @babel/runtime 结合还有一个作用:它除了可以对产出代码瘦身以外,还能避免污染全局作用域。比如一个生成器函数:
正常经过 Babel 编译后,产出:
var _marked = [foo].map(regeneratorRuntime.mark);function foo() {return regeneratorRuntime.wrap(function foo$(_context) {while (1) {switch ((_context.prev = _context.next)) {case 0:case "end":return _context.stop();}}},_marked[0],this);}
其中 regeneratorRuntime 需要是一个全局变量,上述编译后代码污染了全局空间。结合 @babel/plugin-transform-runtime 和 @babel/runtime,可以将上述代码转换为:
var _regenerator = require("@babel/runtime/regenerator");var _regenerator2 = _interopRequireDefault(_regenerator);function _interopRequireDefault(obj) {return obj && obj.__esModule ? obj : { default: obj };}var _marked = [foo].map(_regenerator2.default.mark);function foo() {return _regenerator2.default.wrap(function foo$(_context) {while (1) {switch ((_context.prev = _context.next)) {case 0:case "end":return _context.stop();}}},_marked[0],this);}
此时,regenerator 由 require("@babel/runtime/regenerator")导出,且导出结果被赋值为一个文件作用域内的 _regenerator 变量,从而避免了污染。
理清了这层关系,相信你在使用 Babel 家族成员时,能够更准确地从原理层面理解各项配置功能。
最后,我们再梳理其他几个重要的 Babel 家族成员及其能力和实现原理。
- @babel/plugin是 Babel 插件集合。
- @babel/plugin-syntax-* 是 Babel 的语法插件。它的作用是扩展 @babel/parser 的一些能力,提供给工程使用。比如 @babel/plugin-syntax-top-level-await 插件,提供了使用 top level await 新特性的能力。
- @babel/plugin-proposal-* 用于编译转换在提议阶段的语言特性。
- @babel/plugin-transform-* 是 Babel 的转换插件。比如简单的 @babel/plugin-transform-react-display-name 插件,可以自动适配 React 组件 DisplayName,比如:
var foo = React.createClass({});var bar = createReactClass({});
上述调用,经过 @babel/plugin-transform-react-display-name,可以被编译为:
var foo = React.createClass({displayName: "foo"});var bar = createReactClass({displayName: "bar"});
- @babel/template 封装了基于 AST 的模板能力,可以将字符串代码转换为 AST。比如在生成一些辅助代码(helper)时会用到这个库。
- @babel/node 类似 Node.js Cli,@babel/node 提供在命令行执行高级语法的环境,也就是说,相比于 Node.js Cli,它加入了对更多特性的支持。
- @babel/register 实际上是为 require 增加了一个 hook,使用之后,所有被 Node.js 引用的文件都会先被 Babel 转码。
这里请注意@babel/node 和 @babel/register,都是在运行时进行编译转换,因此运行时性能上会有影响。在生产环境中,我们一般不直接使用。
上述内容看似枯燥,涉及了一般对于业务开发者黑盒的编译产出、源码层面的实现原理、各个包直接的分工协调和组织,可能对于你来说,做到真正理解并非一夕之功。接下来,我们从更加宏观地角度来加深认识。
Babel 工程生态架构设计和分层理念
了解了上述内容,也许你会想问,在平时开发中出镜率极高的 babel-loader 怎么没有看到?事实上,Babel 的生态是内聚的,也是开放的。我们通过 Babel 对代码的编译过程,可以从微观上缩小为前端基建的一个环节,这个环节融入整个工程中,也需要和其他环节相互配合。而 babel-loader 就是 Babel 结合 Webpack,融入整个基建环节的例子。
在 Webpack 编译生命周期中,babel-loader 作为一个 Webpack loader,承担着文件编译职责。我们暂且将 babel-loader 放到 Babel 家族中,先来看看下面这张 “全家福”。
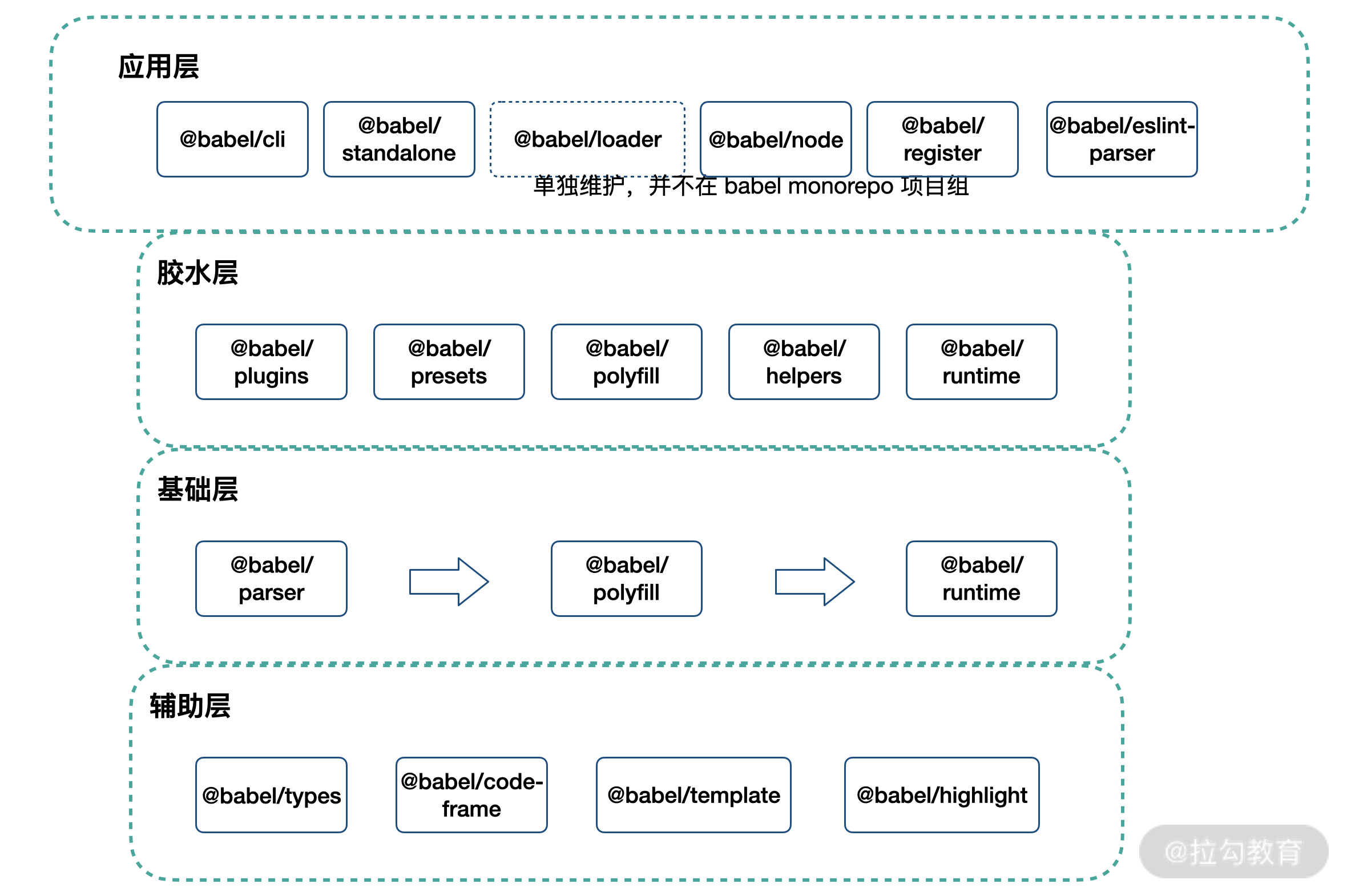
Babel 家族分层模型图
如上图所示,Babel 生态基本按照:辅助层 → 基础层 → 胶水层 → 应用层,四级结构完成。其中部分环节角色的界定有些模糊,比如 @babel/highlight 也可以作为应用层工具出现。
基础层提供了基础的编译能力,完成分词、解析 AST、生成产出代码的工作。基础层中,我们将一些抽象能力下沉为辅助层,这些抽象能力被基础层使用。同时,在基础层之上,我们构建了如 @babel/preset-env 等预设 / 插件能力,这些类似 “胶水” 的包,完成了代码编译降级所需补丁的构建、运行时逻辑的模块化抽象等工作。在最上层,Babel 生态提供了终端命令行、Webpack loader、浏览器端编译等应用级别的能力。
分层的意义在于应用,下面我们从一个应用场景来具体分析,看看 Babel 工程化设计能够给我们带来什么样的启示。
从 @babel/eslint-parser 看 Babel 工程化启示
相信你一定认识 ESLint,它可以用来帮助我们审查 ECMAScript/JavaScript 代码,其原理也是基于 AST 语法分析,进行规则校验。那这和我们的 Babel 有什么关联呢?
试想一下,如果我们的业务代码使用了较多的试验性 ECMAScript 语言特性,那么 ESLint 如何识别这些新的语言特性,做到新特性的代码检查呢?
事实上,ESLint 的解析工具只支持最终进入 ECMAScript 语言标准的特性,如果想对试验性特性或者 Flow/TypeScript 进行代码检查,ESLint 提供了更换 parser 的能力。而 @babel/eslint-parser 就是配合 ESLint 检验合法 Babel 代码的解析器。
实现原理也很简单,ESLint 支持 custom-parser,它允许我们使用自定义的第三方编译器,比如下面是一个使用了 espree 作为一个 custom-parser 的场景:
{"parser": "./path/to/awesome-custom-parser.js"}var espree = require("espree");exports.parseForESLint = function(code, options) {return {ast: espree.parse(code, options),services: {foo: function() {console.log("foo");}},scopeManager: null,visitorKeys: null};};
@babel/eslint-parser源码的实现,保留了相同的模板,它通过自定的 parser,最终返回了 ESLint 所需要的 AST 内容,根据具体的 ESLint rules 进行代码审查:
export function parseForESLint(code, options = {}) {const normalizedOptions = normalizeESLintConfig(options);const ast = baseParse(code, normalizedOptions);const scopeManager = analyzeScope(ast, normalizedOptions);return { ast, scopeManager, visitorKeys };}
上述代码中,ast 是 estree 兼容的格式,可以被 ESLint 理解。visitor Keys 定义了自定义的编译 AST 能力,ScopeManager 定义了新(试验)特性自定义的作用域。
由此可见,Babel 生态和前端工程中的各个环节都是打通开放的。它可以以 babel-loader 的形式和 Webpack 协作,也可以以 @babel/eslint-parser 的方式和 ESLint 合作。现代化的前端工程是一环扣一环的,作为工程链上的任意一环,插件化能力、协作能力将是设计的重点和关键。
总结
作为前端开发者,你可能会被如何配置 Babel、Webpack 这些工具所困扰,出现 “配置到自己的项目中,就各种报错” 的问题。
此时,你可能花费了一天的时间,通过 Google 找到了最终的配置解法,但是解决之道却没搞清楚,得过且过,今后依然被类似的困境袭扰;你可能看过一些关于 Babel 插件和原理的文章,自以为掌握了 AST、窥探了编译,但真正手写一个分词器 Tokenizer 就一头雾水。
我们需要对 Babel 进行系统学习,学习目的是了解其工程化设计,方便我们在前端基建的过程中做到 “最佳配置实践”,做到“不再被编译报错” 所困扰。
希望本讲能对大家的学习和工作带来一些启发,更多相关内容我们会在 “从实战出发,从 0 到 1 构建一个符合标准的公共库”“如何理解 AST 实现和编译原理?” 等小节中继续探索!

若有收获,就点个赞吧
0 人点赞
