数据类型通常是一门编程语言的基础知识,JavaScript 的数据类型可以分为 7 种:空(Null)、未定义(Undefined)、数字(Number)、字符串(String)、布尔值(Boolean)、符号(Symbol)、对象(Object)。
其中前 6 种类型为基础类型,最后 1 种为引用类型。这两者的区别在于,基础类型的数据在被引用或拷贝时,是值传递,也就是说会创建一个完全相等的变量;而引用类型只是创建一个指针指向原有的变量,实际上两个变量是 “共享” 这个数据的,并没有重新创建一个新的数据。
下面我们就来分别介绍这 7 种数据类型的重要概念及常见操作。
Undefined
Undefined 是一个很特殊的数据类型,它只有一个值,也就是 undefined。可以通过下面几种方式来得到 undefined:
- 引用已声明但未初始化的变量;
- 引用未定义的对象属性;
- 执行无返回值函数;
- 执行 void 表达式;
- 全局常量 window.undefined 或 undefined。
对应代码如下:
var a;var o = {}o.b(() => {})()void 0window.undefined
其中比较推荐通过 void 表达式来得到 undefined 值,因为这种方式既简便(window.undefined 或 undefined 常量的字符长度都大于 “void 0” 表达式)又不需要引用额外的变量和属性;同时它作为表达式还可以配合三目运算符使用,代表不执行任何操作。
如下面的代码就表示满足条件 x 大于 0 且小于 5 的时候执行函数 fn,否则不进行任何操作:
x>0 && x<5 ? fn() : void 0;
如何判断一个变量的值是否为 undefined 呢?
下面的代码给出了 3 种方式来判断变量 x 是否为 undefined,你可以先思考一下哪一种可行。
方式 1 直接通过逻辑取非操作来将变量 x 强制转换为布尔值进行判断;方式 2 通过 3 个等号将变量 x 与 undefined 做真值比较;方式 3 通过 typeof 关键字获取变量 x 的类型,然后与’undefined’ 字符串做真值比较:
if(!x) {...}if(x===undefined) {...}if(typeof x === 'undefined') {...}
现在来揭晓答案,方式 1 不可行,因为只要变量 x 的值为 undefined、空字符串、数值 0、null 时都会判断为真。方式 2 也存在一些问题,虽然通过 “===” 和 undefined 值做比较是可行的,但如果 x 未定义则会抛出错误 “ReferenceError: x is not defined” 导致程序执行终止,这对于代码的健壮性显然是不利的。方式 3 则解决了这一问题。
Null
Null 数据类型和 Undefined 类似,只有唯一的一个值 null,都可以表示空值,甚至我们通过 “==” 来比较它们是否相等的时候得到的结果都是 true,但 null 是 JavaScript 保留关键字,而 undefined 只是一个常量。
也就是说我们可以声明名称为 undefined 的变量(虽然只能在老版本的 IE 浏览器中给它重新赋值),但将 null 作为变量使用时则会报错。
Boolean
Boolean 数据类型只有两个值:true 和 false,分别代表真和假,理解和使用起来并不复杂。但是我们常常会将各种表达式和变量转换成 Boolean 数据类型来当作判断条件,这时候就要注意了。
下面是一个简单地将星期数转换成中文的函数,比如输入数字 1,函数就会返回 “星期一”,输入数字 2 会返回 “星期二”,以此类推,如果未输入数字则返回 undefined。
function getWeek(week) {const dict = ['日', '一', '二', '三', '四', '五', '六'];if(week) return `星期${dict[week]}`;}
这里在 if 语句中就进行了类型转换,将 week 变量转换成 Boolean 数据类型,而 0、空字符串、null、undefined 在转换时都会返回 false。所以这段代码在输入 0 的时候不会返回 “星期日”,而返回 undefined。
我们在做强制类型转换的时候一定要考虑这个问题。
Number
两个重要值
Number 是数值类型,有 2 个特殊数值得注意一下,即 NaN 和 Infinity。
- NaN(Not a Number)通常在计算失败的时候会得到该值。要判断一个变量是否为 NaN,则可以通过 Number.isNaN 函数进行判断。
- Infinity 是无穷大,加上负号 “-” 会变成无穷小,在某些场景下比较有用,比如通过数值来表示权重或者优先级,Infinity 可以表示最高优先级或最大权重。
进制转换
当我们需要将其他进制的整数转换成十进制显示的时候可以使用 parseInt 函数,该函数第一个参数为数值或字符串,第二个参数为进制数,默认为 10,当进制数转换失败时会返回 NaN。所以,如果在数组的 map 函数的回调函数中直接调用 parseInt,那么会将数组元素和索引值都作为参数传入。
['0', '1', '2'].map(parseInt)
而将十进制转换成其他进制时,可以通过 toString 函数来实现。
精度问题
对于数值类型的数据,还有一个比较值得注意的问题,那就是精度问题,在进行浮点数运算时很容易碰到。比如我们执行简单的运算 0.1 + 0.2,得到的结果是 0.30000000000000004,如果直接和 0.3 作相等判断时就会得到 false。
出现这种情况的原因在于计算的时候,JavaScript 引擎会先将十进制数转换为二进制,然后进行加法运算,再将所得结果转换为十进制。在进制转换过程中如果小数位是无限的,就会出现误差。同样的,对于下面的表达式,将数字 5 开方后再平方得到的结果也和数字 5 不相等。
Math.pow(Math.pow(5, 1/2), 2)
对于这个问题的解决方法也很简单,那就是消除无限小数位。
- 一种方式是先转换成整数进行计算,然后再转换回小数,这种方式适合在小数位不是很多的时候。比如一些程序的支付功能 API 以 “分” 为单位,从而避免使用小数进行计算。
- 还有另一种方法就是舍弃末尾的小数位。比如对上面的加法就可以先调用 toPrecision 截取 12 位,然后调用 parseFloat 函数转换回浮点数。
parseFloat((0.1 + 0.2).toPrecision(12))
String
String 类型是最常用的数据类型了,关于它的基础 API 函数大家应该比较熟悉了,这里我就不多介绍了。下面通过一道笔试题来重点介绍它的使用场景。
千位分隔符是指为了方便识别较大数字,每隔三位数会加入 1 个逗号,该逗号就是千位分隔符。如果要编写一个函数来为输入值的数字添加千分位分隔符,该怎么实现呢?
一种很容易想到的方法就是从右往左遍历数值每一位,每隔 3 位添加分隔符。为了操作方便,我们可以将数值转换成字符数组,而要实现从右往左遍历,一种实现方式是通过 for 循环的索引值找到对应的字符;而另一种方式是通过数组反转,从而变成从左到右操作。
function sep(n) {let [i, c] = n.toString().split(/(\.\d+)/)return i.split('').reverse().map((c, idx) => (idx+1) % 3 === 0 ? ',' + c: c).reverse().join('').replace(/^,/, '') + c}
这种方式就是将字符串数据转化成引用类型数据,即用数组来实现。
第二种方式则是通过引用类型,即用正则表达式对字符进行替换来实现。
function sep2(n){let str = n.toString()str.indexOf('.') < 0 ? str+= '.' : void 0return str.replace(/(\d)(?=(\d{3})+\.)/g, '$1,').replace(/\.$/, '')}
Symbol
Symbol 是 ES6 中引入的新数据类型,它表示一个唯一的常量,通过 Symbol 函数来创建对应的数据类型,创建时可以添加变量描述,该变量描述在传入时会被强行转换成字符串进行存储。
var a = Symbol('1')var b = Symbol(1)a.description === b.descriptionvar c = Symbol({id: 1})c.descriptionvar _a = Symbol('1')_a == a
基于上面的特性,Symbol 属性类型比较适合用于两类场景中:常量值和对象属性。
避免常量值重复
假设有个 getValue 函数,根据传入的字符串参数 key 执行对应代码逻辑。代码如下所示:
function getValue(key) {switch(key){case 'A':......case 'B':...}}getValue('B');
这段代码对调用者而言非常不友好,因为代码中使用了魔术字符串(魔术字符串是指在代码之中多次出现、与代码形成强耦合的某一个具体的字符串或者数值),导致调用 getValue 函数时需要查看函数源码才能找到参数 key 的可选值。所以可以将参数 key 的值以常量的方式声明出来。
const KEY = {alibaba: 'A',baidu: 'B',...}function getValue(key) {switch(key){case KEY.alibaba:......case KEY.baidu:...}}getValue(KEY.baidu);
但这样也并非完美,假设现在我们要在 KEY 常量中加入一个 key,根据对应的规则,很有可能会出现值重复的情况:
const KEY = {alibaba: 'A',baidu: 'B',...bytedance: 'B'}
这显然会出现问题:
所以在这种场景下更适合使用 Symbol,我们不关心值本身,只关心值的唯一性。
const KEY = {alibaba: Symbol(),baidu: Symbol(),...bytedance: Symbol()}
避免对象属性覆盖
假设有这样一个函数 fn,需要对传入的对象参数添加一个临时属性 user,但可能该对象参数中已经有这个属性了,如果直接赋值就会覆盖之前的值。此时就可以使用 Symbol 来避免这个问题。
创建一个 Symbol 数据类型的变量,然后将该变量作为对象参数的属性进行赋值和读取,这样就能避免覆盖的情况,示例代码如下:
function fn(o) {const s = Symbol()o[s] = 'zzz'...}
补充:类型转换
什么是类型转换?
JavaScript 这种弱类型的语言,相对于其他高级语言有一个特点,那就是在处理不同数据类型运算或逻辑操作时会强制转换成同一数据类型。如果我们不理解这个特点,就很容易在编写代码时产生 bug。
通常强制转换的目标数据类型为 String、Number、Boolean 这三种。下面的表格中显示了 6 种基础数据类型转换关系。
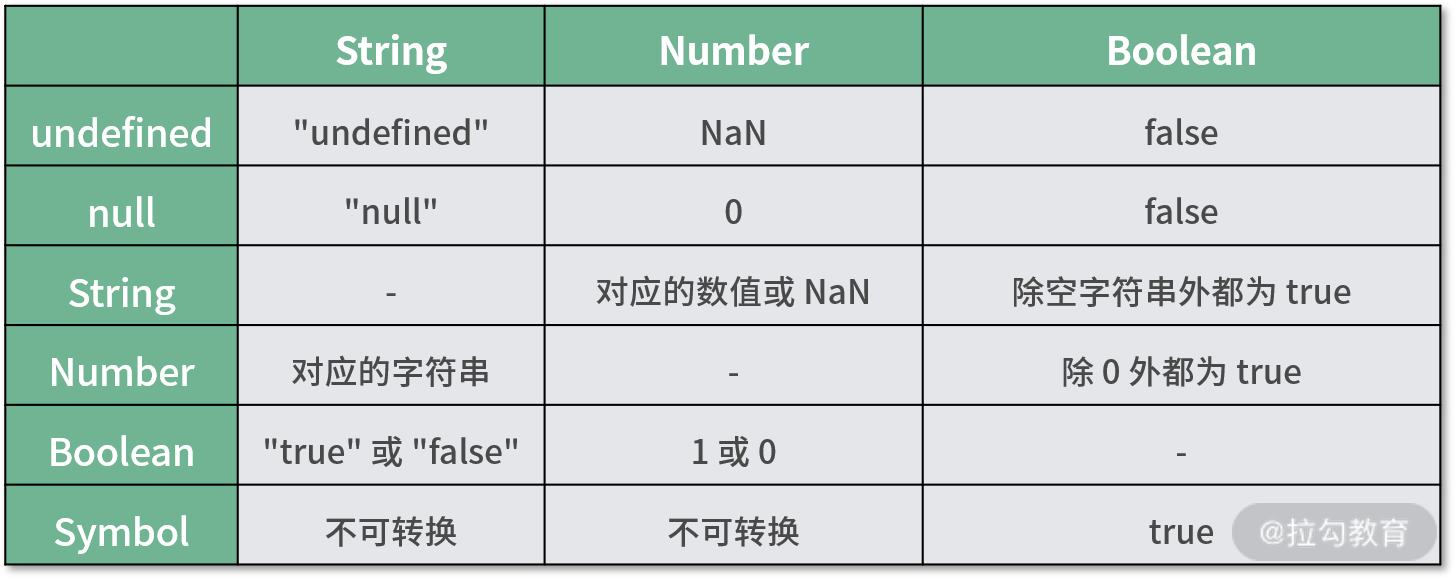
除了不同类型的转换之外,操作同种数据类型也会发生转换。把基本类型的数据换成对应的对象过程称之为 “装箱转换”,反过来,把数据对象转换为基本类型的过程称之为 “拆箱转换”。
对于装箱和拆箱转换操作,我们既可以显示地手动实现,比如将 Number 数据类型转换成 Number 对象;也可以通过一些操作触发浏览器显式地自动转换,比如将对 Number 对象进行加法运算。
var n = 1var o = new Number(n)o.valueOf()n.toPrecision(3)o + 2
什么时候会触发类型转换?
下面这些常见的操作会触发隐式地类型转换,我们在编写代码的时候一定要注意。
- 运算相关的操作符包括 +、-、+=、++、* 、/、%、<<、& 等。
- 数据比较相关的操作符包括 >、<、== 、<=、>=、===。
- 逻辑判断相关的操作符包括 &&、!、||、三目运算符。
Object
相对于基础类型,引用类型 Object 则复杂很多。简单地说,Object 类型数据就是键值对的集合,键是一个字符串(或者 Symbol) ,值可以是任意类型的值; 复杂地说,Object 又包括很多子类型,比如 Date、Array、Set、RegExp。
对于 Object 类型,我们重点理解一种常见的操作,即深拷贝。
- 由于引用类型在赋值时只传递指针,这种拷贝方式称为浅拷贝。
- 而创建一个新的与之相同的引用类型数据的过程称之为深拷贝。
现在我们来实现一个拷贝函数,支持上面 7 种类型的数据拷贝。
对于 6 种基础类型,我们只需简单的赋值即可,而 Object 类型变量需要特殊操作。因为通过等号 “=” 赋值只是浅拷贝,要实现真正的拷贝操作则需要通过遍历键来赋值对应的值,这个过程中如果遇到 Object 类型还需要再次进行遍历。
为了准确判断每种数据类型,我们可以先通过 typeof 来查看每种数据类型的描述:
[undefined, null, true, '', 0, Symbol(), {}].map(it => typeof it)
发现 null 有些特殊,返回结果和 Object 类型一样都为 “object”,所以需要再次进行判断。按照上面分析的结论,我们可以写出下面的函数:
function clone(data) {let result = {}const keys = [...Object.getOwnPropertyNames(data), ...Object.getOwnPropertySymbols(data)]if(!keys.length) return datakeys.forEach(key => {let item = data[key]if (typeof item === 'object' && item) {result[key] = clone(item)} else {result[key] = item}})return result}
在遍历 Object 类型数据时,我们需要把 Symbol 数据类型也考虑进来,所以不能通过 Object.keys 获取键名或 for…in 方式遍历,而是通过 getOwnPropertyNames 和 getOwnPropertySymbols 函数将键名组合成数组,然后进行遍历。对于键数组长度为 0 的非 Object 类型的数据可直接返回,然后再遍历递归,最终实现拷贝。
我们在编写递归函数的时候需要特别注意的是,递归调用的终止条件,避免无限递归。那在这个 clone 函数中有没有可能出现无限递归调用呢?
答案是有的。那就是当对象数据嵌套的时候,比如像下面这种情况,对象 a 的键 b 指向对象 b,对象 b 的键 a 指向对象 a,那么执行 clone 函数就会出现死循环,从而耗尽内存。
var a = {var b = {}a.b = bb.a = a
怎么避免这种情况呢?一种简单的方式就是把已添加的对象记录下来,这样下次碰到相同的对象引用时,直接指向记录中的对象即可。要实现这个记录功能,我们可以借助 ES6 推出的 WeakMap 对象,该对象是一组键 / 值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
我们对 clone 函数改造一下,添加一个 WeakMap 来记录已经拷贝过的对象,如果当前对象已经被拷贝过,那么直接从 WeakMap 中取出,否则重新创建一个对象并加入 WeakMap 中。具体代码如下:
function clone(obj) {let map = new WeakMap()function deep(data) {let result = {}const keys = [...Object.getOwnPropertyNames(data), ...Object.getOwnPropertySymbols(data)]if(!keys.length) return dataconst exist = map.get(data)if (exist) return existmap.set(data, result)keys.forEach(key => {let item = data[key]if (typeof item === 'object' && item) {result[key] = deep(item)} else {result[key] = item}})return result}return deep(obj)}
总结
这一课时通过实例与原理相结合,带你深入理解了 JavaScript 的 6 种基础数据类型和 1 种引用数据类型。对于 6 种基础数据类型,我们要熟知它们之间的转换关系,而引用类型则比较复杂,重点讲了如何深拷贝一个对象。其实引用对象的子类型比较多,由于篇幅所限没有进行一一讲解,需要大家在平常工作中继续留心积累。
最后布置一道思考题:你能否写出一个函数来判断两个变量是否相等?

若有收获,就点个赞吧
0 人点赞
