Node.js 应用开发实战 - 高级前端开发工程师 - 拉勾教育
前几讲我们都使用了一种非常简单暴力的方式(node app.js)启动 Node.js 服务器,而在线上我们要考虑使用多核 CPU,充分利用服务器资源,这里就用到多进程解决方案,所以本讲介绍 PM2 的原理以及如何应用一个 cluster 模式启动 Node.js 服务。
单线程问题
在《01 | 事件循环:高性能到底是如何做到的?》中我们分析了 Node.js 主线程是单线程的,如果我们使用 node app.js 方式运行,就启动了一个进程,只能在一个 CPU 中进行运算,无法应用服务器的多核 CPU,因此我们需要寻求一些解决方案。你能想到的解决方案肯定是多进程分发策略,即主进程接收所有请求,然后通过一定的负载均衡策略分发到不同的 Node.js 子进程中。如图 1 的方案所示:
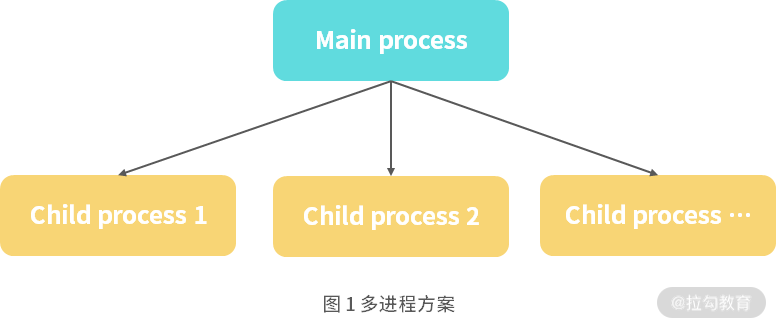
这一方案有 2 个不同的实现:
- 主进程监听一个端口,子进程不监听端口,通过主进程分发请求到子进程;
- 主进程和子进程分别监听不同端口,通过主进程分发请求到子进程。
在 Node.js 中的 cluster 模式使用的是第一个实现。
cluster 模式
cluster 模式其实就是我们上面图 1 所介绍的模式,一个主进程和多个子进程,从而形成一个集群的概念。我们先来看看 cluster 模式的应用例子。
应用
我们先实现一个简单的 app.js,代码如下:
const http = require('http');** 创建 http 服务,简单返回*/const server = http.createServer((req, res) => {res.write(`hello world, start with cluster ${process.pid}`);res.end();});** 启动服务*/server.listen(3000, () => {console.log('server start http://127.0.0.1:3000');});console.log(`Worker ${process.pid} started`);
这是最简单的一个 Node.js 服务,接下来我们应用 cluster 模式来包装这个服务,代码如下:
const cluster = require('cluster');const instances = 2;if (cluster.isMaster) {for(let i = 0;i<instances;i++) {cluster.fork();}} else {require('./app.js');}
首先判断是否为主进程:
- 如果是则使用 cluster.fork 创建子进程;
- 如果不是则为子进程 require 具体的 app.js。
然后运行下面命令启动服务。
启动成功后,再打开另外一个命令行窗口,多次运行以下命令:
curl "http://127.0.0.1:3000/"
你可以看到如下输出:
hello world, start with cluster 4543hello world, start with cluster 4542hello world, start with cluster 4543hello world, start with cluster 4542
后面的进程 ID 是比较有规律的随机数,有时候输出 4543,有时候输出 4542,4543 和 4542 就是我们 fork 出来的两个子进程,接下来我们看下为什么是这样的。
原理
首先我们需要搞清楚两个问题:
- Node.js 的 cluster 是如何做到多个进程监听一个端口的;
- Node.js 是如何进行负载均衡请求分发的。
多进程端口问题
在 cluster 模式中存在 master 和 worker 的概念,master 就是主进程,worker 则是子进程,因此这里我们需要看下 master 进程和 worker 进程的创建方式。如下代码所示:
const cluster = require('cluster');const instances = 2;if (cluster.isMaster) {for(let i = 0;i<instances;i++) {cluster.fork();}} else {require('./app.js');}
这段代码中,第一次 require 的 cluster 对象就默认是一个 master,这里的判断逻辑在源码中,如下代码所示:
'use strict';const childOrPrimary = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'primary';module.exports = require(`internal/cluster/${childOrPrimary}`);
通过进程环境变量设置来判断:
- 如果没有设置则为 master 进程;
- 如果有设置则为子进程。
因此第一次调用 cluster 模块是 master 进程,而后都是子进程。
主进程和子进程 require 文件不同:
- 前者是 internal/cluster/primary;
- 后者是 internal/cluster/child。
我们先来看下 master 进程的创建过程,这部分代码在这里。
可以看到 cluster.fork,一开始就会调用 setupPrimary 方法,创建主进程,由于该方法是通过 cluster.fork 调用,因此会调用多次,但是该模块有个全局变量 initialized 用来区分是否为首次,如果是首次则创建,否则则跳过,如下代码:
if (initialized === true)return process.nextTick(setupSettingsNT, settings);initialized = true;
接下来继续看 cluster.fork 方法,源码如下:
cluster.fork = function(env) {cluster.setupPrimary();const id = ++ids;const workerProcess = createWorkerProcess(id, env);const worker = new Worker({id: id,process: workerProcess});worker.on('message', function(message, handle) {cluster.emit('message', this, message, handle);});
在上面代码中第 2 行就是创建主进程,第 4 行就是创建 worker 子进程,在这个 createWorkerProcess 方法中,最终是使用 child_process 来创建子进程的。在初始化代码中,我们调用了两次 cluster.fork 方法,因此会创建 2 个子进程,在创建后又会调用我们项目根目录下的 cluster.js 启动一个新实例,这时候由于 cluster.isMaster 是 false,因此会 require 到 internal/cluster/child 这个方法。
由于是 worker 进程,因此代码会 require (‘./app.js’) 模块,在该模块中会监听具体的端口,代码如下:
** 启动服务*/server.listen(3000, () => {console.log('server start http://127.0.0.1:3000');});console.log(`Worker ${process.pid} started`);
这里的 server.listen 方法很重要,这部分源代码在这里,其中的 server.listen 会调用该模块中的 listenInCluster 方法,该方法中有一个关键信息,如下代码所示:
if (cluster.isPrimary || exclusive) {server._listen2(address, port, addressType, backlog, fd, flags);return;}const serverQuery = {address: address,port: port,addressType: addressType,fd: fd,flags,};cluster._getServer(server, serverQuery, listenOnPrimaryHandle);
上面代码中的第 6 行,判断为主进程,就是真实的监听端口启动服务,而如果非主进程则调用 cluster._getServer 方法,也就是 internal/cluster/child 中的 cluster._getServer 方法。
接下来我们看下这部分代码:
obj.once('listening', () => {cluster.worker.state = 'listening';const address = obj.address();message.act = 'listening';message.port = (address && address.port) || options.port;send(message);});
这一代码通过 send 方法,如果监听到 listening 发送一个消息给到主进程,主进程也有一个同样的 listening 事件,监听到该事件后将子进程通过 EventEmitter 绑定在主进程上,这样就完成了主子进程之间的关联绑定,并且只监听了一个端口。而主子进程之间的通信方式,就是我们常听到的 IPC 通信方式。
负载均衡原理
既然 Node.js cluster 模块使用的是主子进程方式,那么它是如何进行负载均衡处理的呢,这里就会涉及 Node.js cluster 模块中的两个模块。
- round_robin_handle.js(非 Windows 平台应用模式),这是一个轮询处理模式,也就是轮询调度分发给空闲的子进程,处理完成后回到 worker 空闲池子中,这里要注意的就是如果绑定过就会复用该子进程,如果没有则会重新判断,这里可以通过上面的 app.js 代码来测试,用浏览器去访问,你会发现每次调用的子进程 ID 都会不变。
- shared_handle.js( Windows 平台应用模式),通过将文件描述符、端口等信息传递给子进程,子进程通过信息创建相应的 SocketHandle / ServerHandle,然后进行相应的端口绑定和监听、处理请求。
以上就是 cluster 的原理,总结一下就是 cluster 模块应用 child_process 来创建子进程,子进程通过复写掉 cluster._getServer 方法,从而在 server.listen 来保证只有主进程监听端口,主子进程通过 IPC 进行通信,其次主进程根据平台或者协议不同,应用两种不同模块(round_robin_handle.js 和 shared_handle.js)进行请求分发给子进程处理。接下来我们看一下 cluster 的成熟的应用工具 PM2 的应用和原理。
PM2 原理
PM2 是守护进程管理器,可以帮助你管理和保持应用程序在线。PM2 入门非常简单,它是一个简单直观的 CLI 工具,可以通过 NPM 安装,接下来我们看下一些简单的用法。
应用
你可以使用如下命令进行 NPM 或者 Yarn 的安装:
$ npm install pm2@latest -g# or$ yarn global add pm2
安装成功后,可以使用如下命令查看是否安装成功以及当前的版本:
接下来我们使用 PM2 启动一个简单的 Node.js 项目,进入本讲代码的项目根目录,然后运行下面命令:
运行后,再执行如下命令:
可以看到如图 2 所示的结果,代表运行成功了。

图 2 pm2 list 运行结果
PM2 启动时可以带一些配置化参数,具体参数列表你可以参考官方文档。在开发中我总结出了一套最佳的实践,如以下配置所示:
module.exports = {apps : [{name: "nodejs-column",script: "./app.js",instances: 2,exec_mode: 'cluster',env_development: {NODE_ENV: "development",watch: true,},env_testing: {NODE_ENV: "testing",watch: false,},env_production: {NODE_ENV: "production",watch: false,},log_date_format: 'YYYY-MM-DD HH:mm Z',error_file: '~/data/err.log',out_file: '~/data/info.log',max_restarts: 10,}]}
在上面的配置中要特别注意 error_file 和 out_file,这里的日志目录在项目初始化时要创建好,如果不提前创建好会导致线上运行失败,特别是无权限创建目录时。其次如果存在环境差异的配置时,可以放置在不同的环境下,最终可以使用下面三种方式来启动项目,分别对应不同环境。
$ pm2 start pm2.config.js --env development$ pm2 start pm2.config.js --env testing$ pm2 start pm2.config.js --env production
原理
接下来我们来看下是如何实现的,由于整个项目是比较复杂庞大的,这里我们主要关注进程创建管理的原理。
首先我们来看下进程创建的方式,整体的流程如图 3 所示。
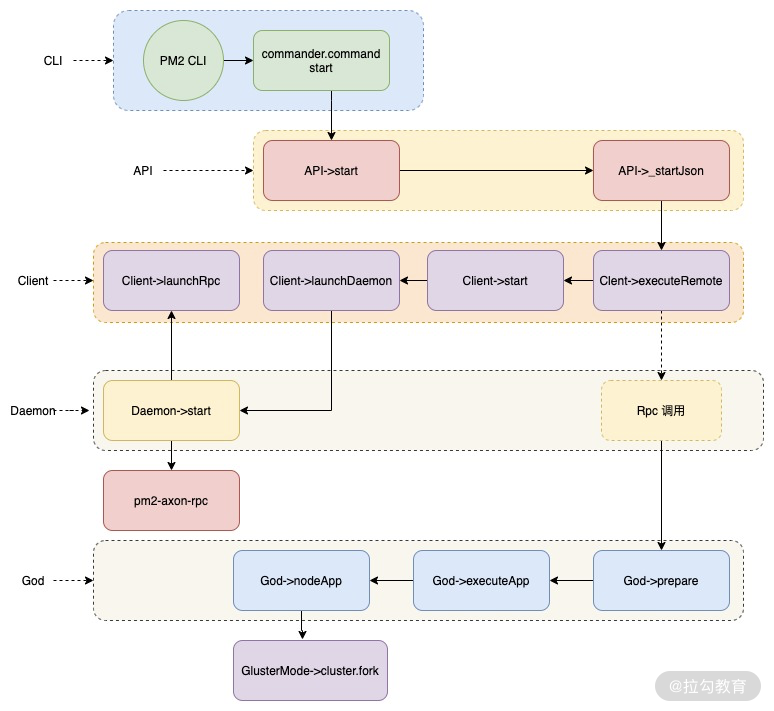
图 3 PM2 源码多进程创建方式
这一方式涉及五个模块文件。
- CLI(lib/binaries/CLI.js)处理命令行输入,如我们运行的命令:
pm2 start pm2.config.js --env development
- API(lib/API.js)对外暴露的各种命令行调用方法,比如上面的 start 命令对应的 API->start 方法。
- Client (lib/Client.js)可以理解为命令行接收端,负责创建守护进程 Daemon,并与 Daemon(lib/Daemon.js)保持 RPC 连接。
- God (lib/God.js)主要负责进程的创建和管理,主要是通过 Daemon 调用,Client 所有调用都是通过 RPC 调用 Daemon,然后 Daemon 调用 God 中的方法。
- 最终在 God 中调用 ClusterMode(lib/God/ClusterMode.js)模块,在 ClusterMode 中调用 Node.js 的 cluster.fork 创建子进程。
图 3 中首先通过命令行解析调用 API,API 中的方法基本上是与 CLI 中的命令行一一对应的,API 中的 start 方法会根据传入参数判断是否是调用的方法,一般情况下使用的都是一个 JSON 配置文件,因此调用 API 中的私有方法 _startJson。
接下来就开始在 Client 模块中流转了,在 _startJson 中会调用 executeRemote 方法,该方法会先判断 PM2 的守护进程 Daemon 是否启动,如果没有启动会先调用 Daemon 模块中的方法启动守护进程 RPC 服务,启动成功后再通知 Client 并建立 RPC 通信连接。
成功建立连接后,Client 会发送启动 Node.js 子进程的命令 prepare,该命令传递 Daemon,Daemon 中有一份对应的命令的执行方法,该命令最终会调用 God 中的 prepare 方法。
在 God 中最终会调用 God 文件夹下的 ClusterMode 模块,应用 Node.js 的 cluster.fork 创建子进程,这样就完成了整个启动过程。
综上所述,PM2 通过命令行,使用 RPC 建立 Client 与 Daemon 进程之间的通信,通过 RPC 通信方式,调用 God,从而应用 Node.js 的 cluster.fork 创建子进程的。以上是启动的流程,对于其他命令指令,比如 stop、restart 等,也是一样的通信流转过程,你参照上面的流程分析就可以了,如果遇到任何问题,都可以在留言区与我交流。
以上的分析你需要参考PM2 的 GitHub 源码。
总结
本讲主要介绍了 Node.js 中的 cluster 模块,并深入介绍了其核心原理,其次介绍了目前比较常用的多进程管理工具 PM2 的应用和原理。学完本讲后,需要掌握 Node.js cluster 原理,并且掌握 PM2 的实现原理。
接下来我们将开始讲解一些关于 Node.js 性能相关的知识,为后续的高性能服务做一定的准备,其次也在为后续性能优化打下一定的技术基础。
下一讲会讲解,目前我们在使用的 Node.js cluster 模式存在的性能问题。

《大前端高薪训练营》
对标阿里 P7 技术需求 + 每月大厂内推,6 个月助你斩获名企高薪 Offer。点击链接,快来领取!

若有收获,就点个赞吧
0 人点赞
