SpringCloud Alibaba 实战 - 前京东金融架构师 - 拉勾教育
前面我们介绍了 OpenFeign 微服务间通信与 Spring Cloud Gateway 网关通信,这些是日常业务中的正常处理情况,但是在微服务环境下受制于网络、机器性能、算法、程序各方面影响,运行异常的情况也在显著提升,如果不做好异常保护,微服务架构就像空中楼阁一样随时可能会崩溃,从本节我们开始一个新话题:微服务的系统保护。通过这个话题,我们就可以了解在 Spring Cloud Alibaba 生态下解决雪崩等一系列危机整体架构安全的方法。
这一讲我们先来对 Alibaba Sentinel 做入门讲解,涉及三方面内容:
- 通过真实的生产案例讲解微服务的雪崩效应;
- Alibaba Sentinel 的部署与配置;
- 配置的接口限流规则。
微服务的雪崩效应
一次线上的服务雪崩事故
“雪崩” 一词指的是山地积雪由于底部溶解等原因造成的突然大块塌落的现象,具有很强的破坏力。在微服务项目中指由于突发流量导致某个服务不可用,从而导致上游服务不可用,并产生级联效应,最终导致整个系统不可用,使用雪崩这个词来形容这一现象最合适不过。
之前我在国内一家著名的金融服务机构负责架构设计与维护,经历过不止一次服务雪崩,这也给我造成了一些心理阴影。在日后的架构设计中,我总是情不自禁地从最坏的情况考虑,尽我所能规避最差的情况发生。
下面我跟大家分享一次险些给公司带来重大损失的雪崩事故,希望各位能引以为戒。
在 2015 年 “618” 前几天,当时我负责公司普惠金融业务线架构。
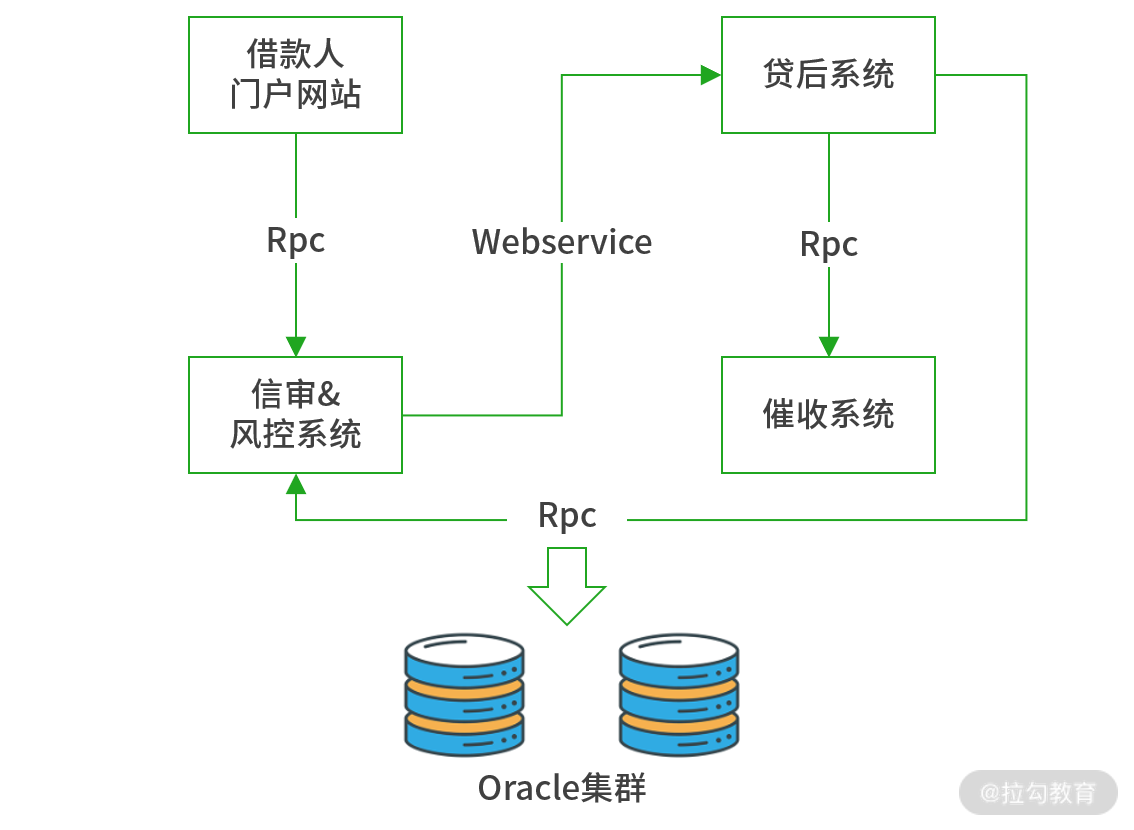
普惠金融业务流程
平时从借款人门户的订单接口的访问峰值约为 100 TPS,因为并发压力不大,我对系统性能与可用性考虑不足,为节约成本也只为每一个子系统部署了单台高性能服务器。没想到在 6 月 16 日上午 10 点 30 分,技术部接到紧急通知,除催收系统外,各节点服务全线崩溃。崩溃前借款人门户订单接口 TPS 峰值高达 2000,出现大量请求积压,之后运维迅速重启服务,但没过 5 分钟,系统再次崩溃。技术部大佬和架构师们都发觉情况不妙,迅速启用 Nginx 限流,设置最多放行 200 TPS,多余请求直接拒绝,并且总部电话远程调度各区域客户经理分时间段录入借款数据,这才度过了本次难关。
事后,架构组对本次问题进行复盘,发现 2015 年 618 是某东大促,客户购物热情激增,此时公司为配合 618 大促,推出了优惠力度最大的借款活动,这导致在这几天的业务量是平时的几十倍。而分散在全国的 20000 多名客户经理的工作习惯是在上午十点多集中录入昨日客户借款单据,如此庞大的短时并发让 “贷后系统” 不堪重负,出现长时未响应。同时上游的 “借款人门户” 与“信审风控”也处于阻塞等待的状态。而在客户经理这边看到表单提交无响应,便会 F5 刷新页面重发请求,这无疑又为 “贷后系统” 雪上加霜,之后便是贷后系统崩溃、信审系统崩溃、借款人门户网站崩溃这一连锁反应。
发现了问题根源,解决也就简单了,经过多方权衡在以下几方面作出应对:
- 提高可用性,将单台设备转为多台负载均衡集群。
- 提高性能,检查慢 SQL、优化算法、引入缓存来缩短单笔业务的处理时间。
- 预防瞬时 TPS 激增,将系统限流作为常态加入系统架构。
- 完善事后处理,遇到长响应,一旦超过规定窗口时间,服务立即返回异常,中断当前处理。
- 加强预警与监控,引入 ELK,进行流量实时监控与风险评估,及时发现系统风险。
- 完善制度,要求客户单据当日录入系统。
刚才所描述的是一次典型的雪崩效应,下面我们来梳理下分布式架构为什么会产生雪崩?
为什么微服务会产生雪崩效应
如下图所示,假如我们开发了一套分布式应用系统,前端应用分别向 A/H/I/P 四个服务发起调用请求:
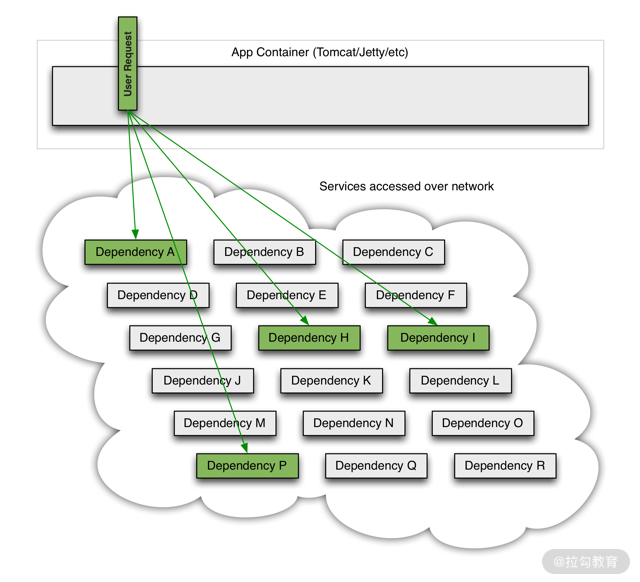
前端应用需要四个服务
但随着时间推移,假如服务 I 因为优化问题,导致需要 20 秒才能返回响应,这就必然会导致 20 秒内该请求线程会一直处于阻塞状态。
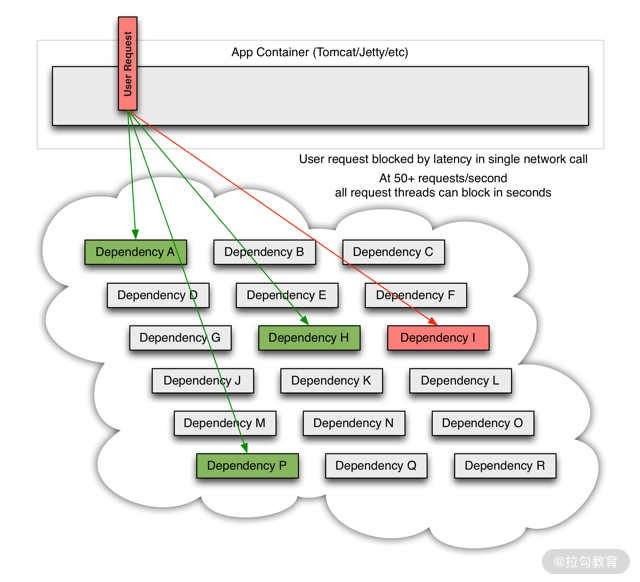
其中一个出现长延时,会导致前端应用线程阻塞
但是,如果这种状况放在高并发场景下,就绝对不允许出现,假如在 20 秒内有 10 万个请求通过应用访问到后端微服务。容器会因为大量请求阻塞积压导致连接池爆满,而这种情况后果极其严重!轻则 “服务无响应”,重则前端应用直接崩溃。
以上这种因为某一个节点长时间处理导致应用请求积压崩溃的现象被称为微服务的 “雪崩效应”。
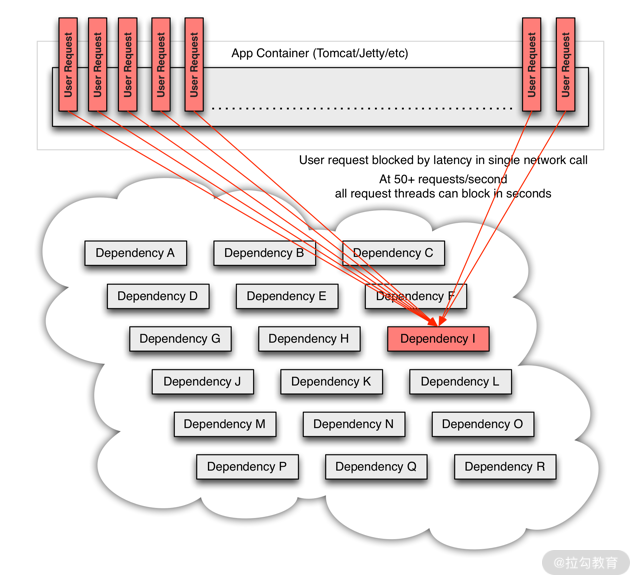
当大量线程积压后,前端应用崩溃,雪崩效应产生
如何有效避免雪崩效应?
刚才我们分析了雪崩效应是因为出现瞬间大流量 + 微服务响应慢造成的。针对这两点在架构设计时要采用不同方案。
- 采用限流方式进行预防:可以采用限流方案,控制请求的流入,让流量有序的进入应用,保证流量在一个可控的范围内。
- 采用服务降级与熔断进行补救:针对响应慢问题,可以采用服务降级与熔断进行补救。服务降级是指当应用处理时间超过规定上限后,无论服务是否处理完成,便立即触发服务降级,响应返回预先设置的异常信息。
这么说有些晦涩,以下图为例。在用户支付完成后,通过消息通知服务向用户邮箱发送 “订单已确认” 的邮件。假设消息通知服务出现异常,需要 10 秒钟才能完成发送请求, 这是不能接受的。为了预防雪崩,我们可以在微服务体系中增加服务降级的功能,预设 2 秒钟有效期,如遇延迟便最多允许 2 秒,2 秒内服务未处理完成则直接降级并返回响应,此时支付服务会收到 “邮件发送超时” 的错误信息。这也就意味着消息通知服务最多只有两秒钟的处理时间。处理结果,要么发送成功,要么超时降级。 因此阻塞时间缩短,产生雪崩的概率会大大降低。
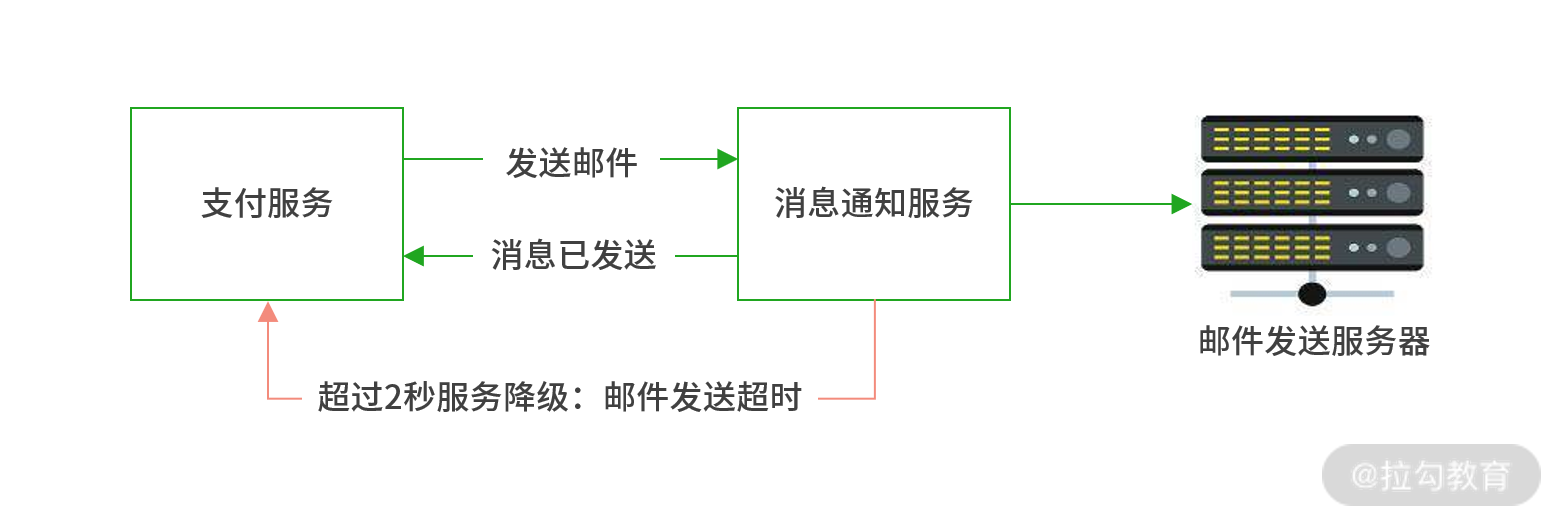
通过服务降级减少阻塞时间
Alibaba Sentinel
有了解决问题的方案,下面咱们就可以聊聊落地实现的事情。在 Spring Cloud Alibaba 生态中有一个重要的流控组件 Sentinel。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。

Alibaba Sentinel
Sentinel 具有以下特征。
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其他开源框架 / 库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 整合只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
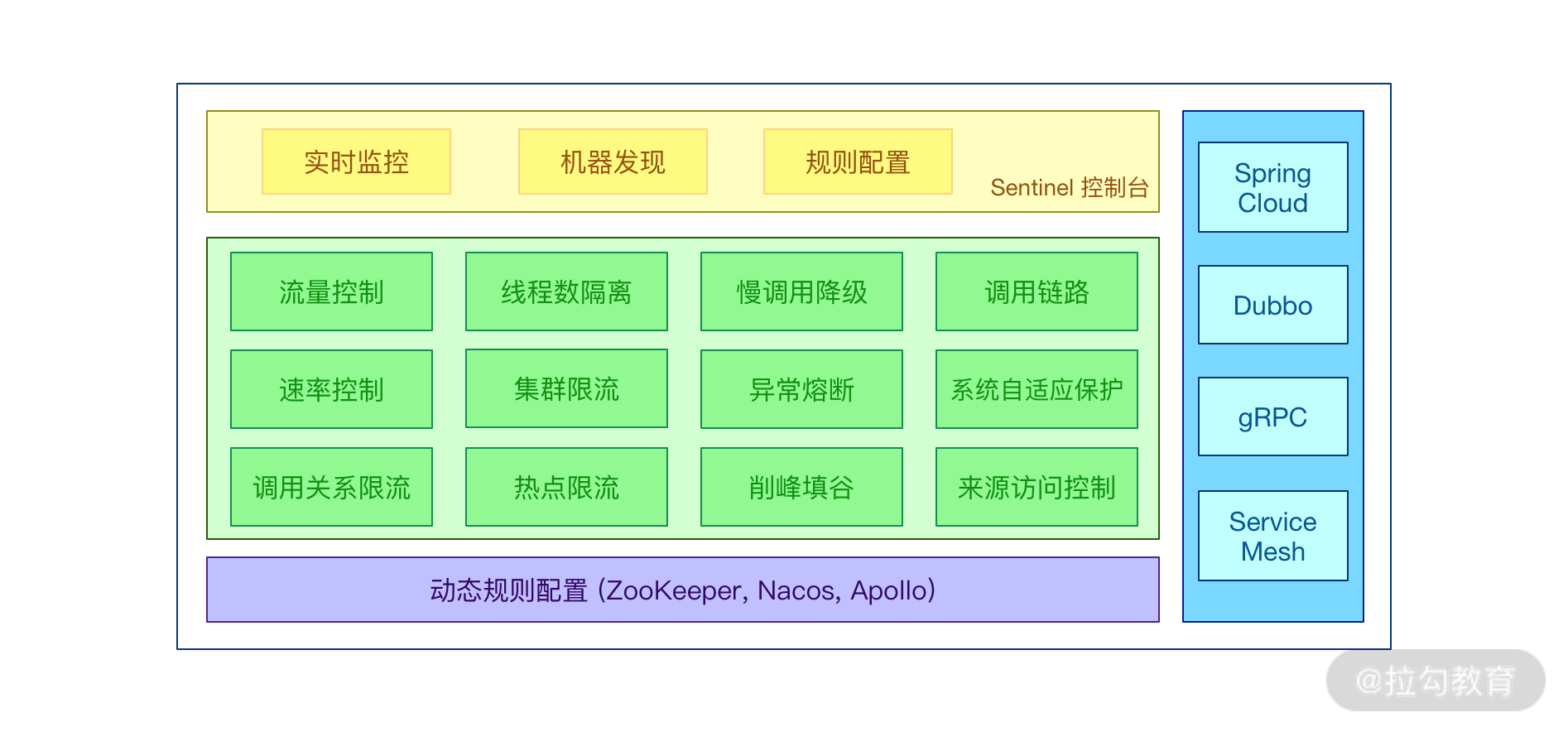
Alibaba Sentinel 特性图
Sentinel 配置入门
Sentinel 分为两个部分:Sentinel Dashboard和Sentinel 客户端。
- Sentinel Dashboard:Sentinel Dashboard 是 Sentinel 配套的可视化控制台与监控仪表盘套件,它支持节点发现,以及健康情况管理、监控(单机和集群)、规则管理和推送的功能。Sentinel Dashboard 是基于 Spring Boot 开发的 WEB 应用,打包后可以直接运行,目前最新版本为 1.8.0。
Sentinel Dashboard
- Sentinel 客户端:Sentinel 客户端需要集成在 Spring Boot 微服务应用中,用于接收来自 Dashboard 配置的各种规则,并通过 Spring MVC Interceptor 拦截器技术实现应用限流、熔断保护。
部署 Sentinel Dashboard(仪表盘)
1. 访问:https://github.com/alibaba/Sentinel/releases,下载最新版 Sentinel Dashboard。

Sentinel Dashboard GitHub 下载页
2. 利用下面的命令启动 Dashboard。
java -jar -Dserver.port=9100 sentinel-dashboard-1.8.0.jar
这个命令的含义是启动 Sentinel Dashboard 应用,Sentinel Dashboard 会监听 9100 端口实现与微服务的通信。同时我们可以访问下面的网址查看 Sentinel Dashboard 的 UI 界面。
http://192.168.31.10:9100
在用户名、密码处输入 sentinel/sentinel,便可进入 Dashboard。

Sentinel Dashboard 登录页
Sentinel Dashboard 首页
微服务内置 Sentinel 客户端
第一步,利用 Spring Initializr 向导创建 sentinel-sample 工程,pom.xml 增加以下三项依赖。
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
第二步,配置 Nacos 与 Sentinel 客户端。
spring:application:name: sentinel-samplecloud:sentinel:transport:dashboard: 192.168.31.10:9100eager: truenacos:server-addr: 192.168.31.10:8848username: nacospassword: nacosserver:port: 80management:endpoints:web:exposure:include: '*'
第三步,验证配置。
访问下面网址,在 Sentinel Dashboard 左侧看到 sentinel-sample 服务出现,则代表 Sentinel 客户端与 Dashboard 已经完成通信。
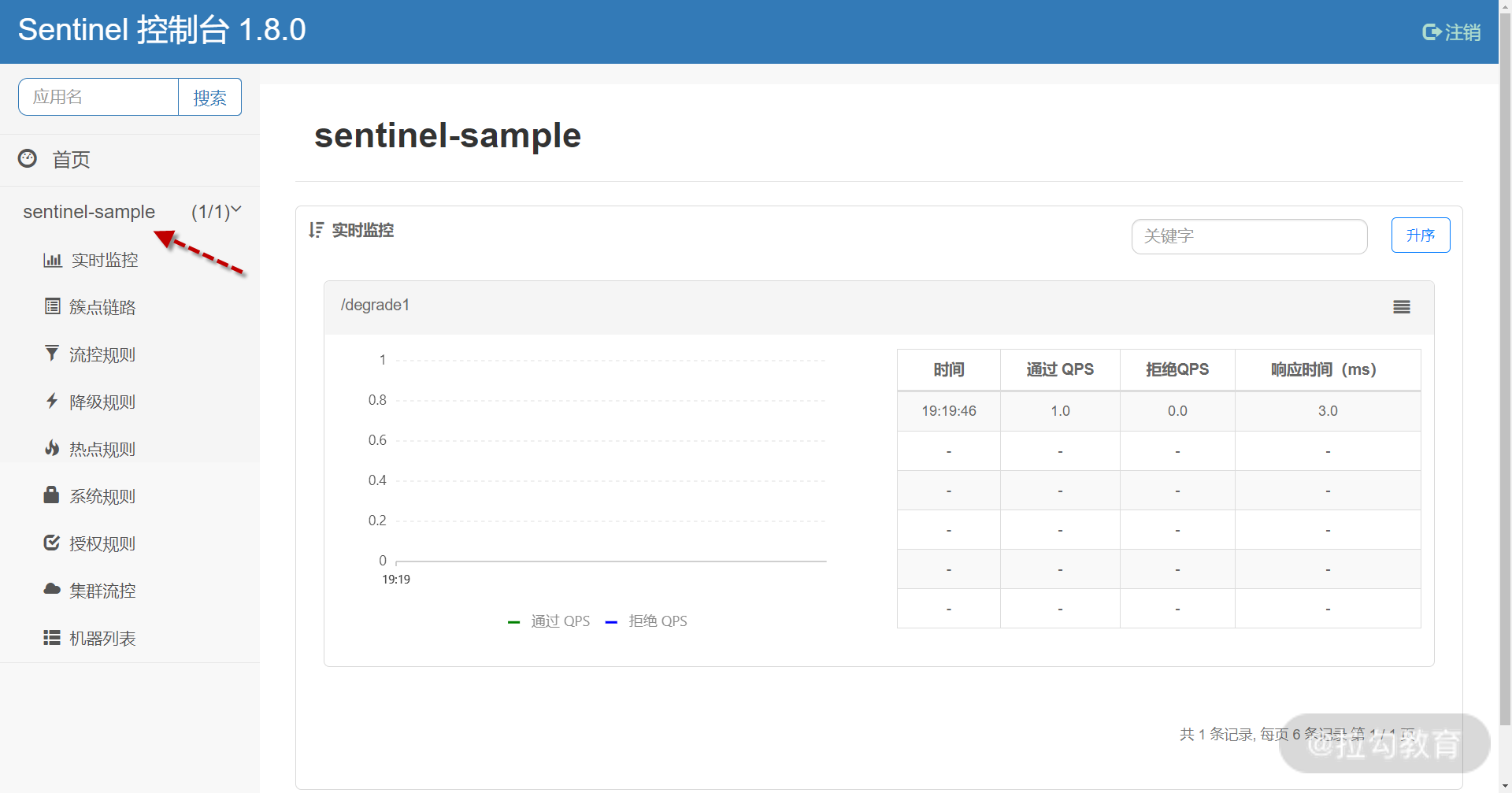
确认 sentinel-sampl e 与 Dashboard 通信成功
下面咱们通过 Dashboard 配置应用的限流规则,来体验下 Sentinel 的用法。
配置限流规则
第一步,在 sentinel-sample 服务中,增加 SentinelSampleController 类,用于演示 Sentinel 限流规则。
package com.lagou.sentinelsample.controller;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class SentinelSampleController {@GetMapping("/test_flow_rule")public String testFlowRule(){return "SUCCESS";}}
启动 sentinel-sample,访问http://localhost/test_flow_rule,无论刷新多少次,都会看到 “SUCCESS”。
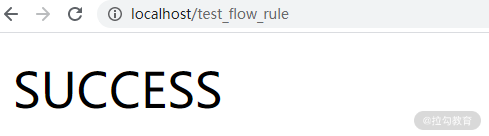
正常访问结果
第二步,访问 Sentinel Dashboard 配置限流规则。
在左侧找到簇点链路,右侧定位到 /test_flow_rule,点击后面的 “流控” 按钮。
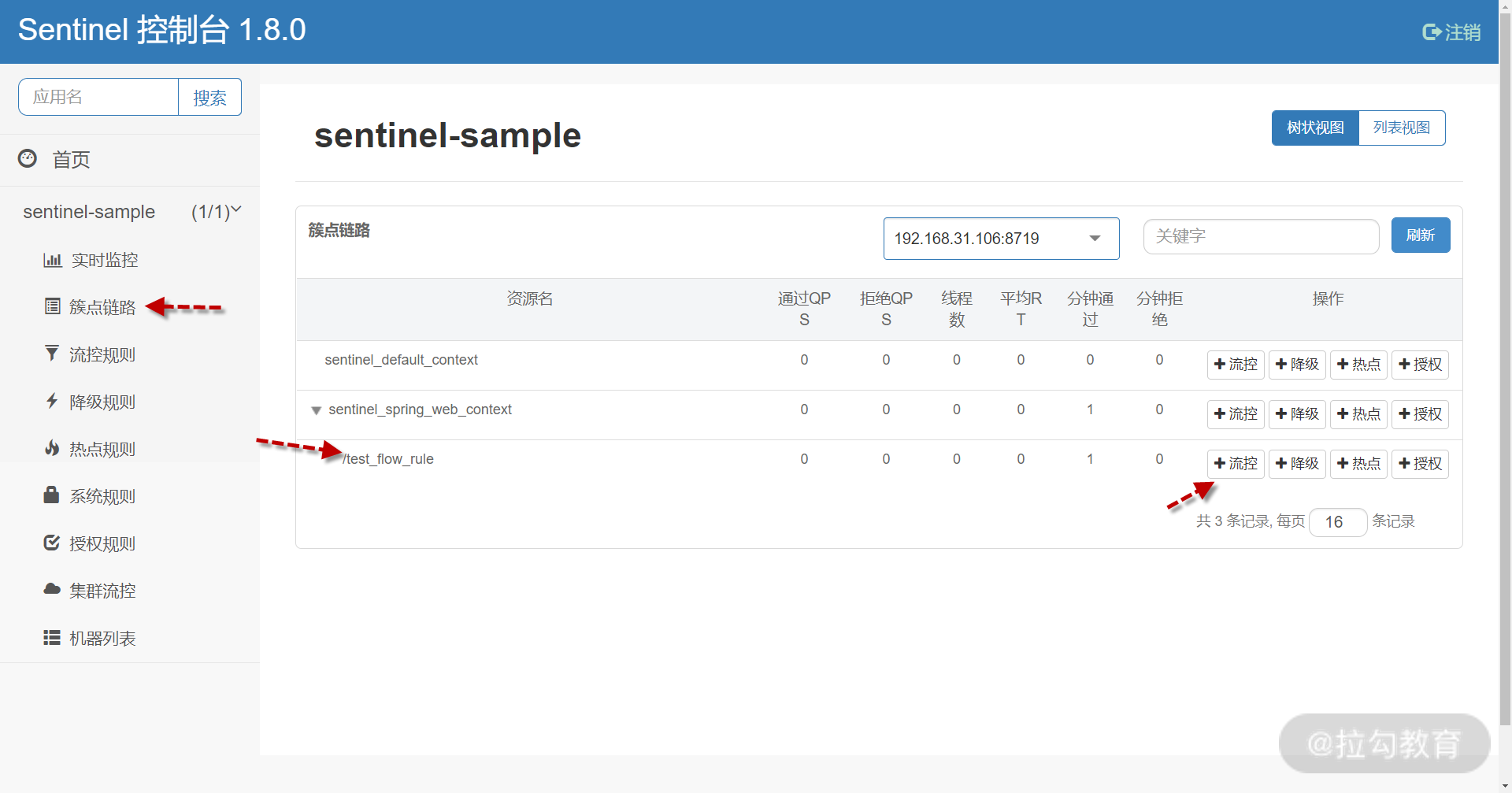
设置接口流控规则
在弹出界面,按下图配置,其含义为 /test_flow_rule 接口每秒钟只允许 1QPS 访问,超出的请求直接服务降级返回异常。最后点击 “新增” 完成规则设置。
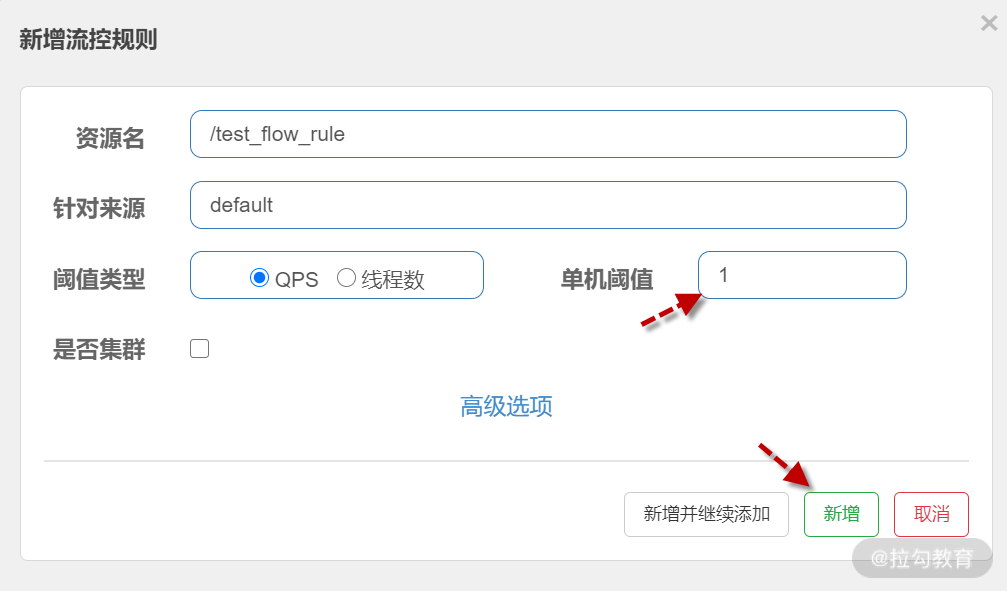
设置流控规则
此时针对 /test_flow_rule 接口的流控规则已生效,可以在 “流控规则” 面板看到。
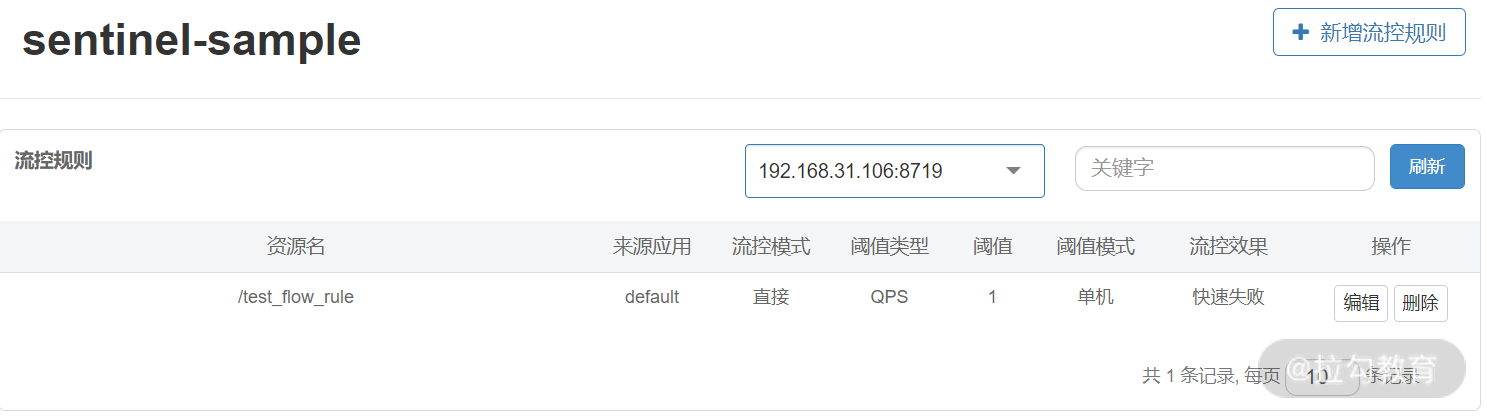
现有流控规则列表
第三步,验证流控效果。
重新访问http://localhost/test_flow_rule,浏览器反复刷新。
第一次刷新时会出现 “SUCCESS” 文本代表处理成功。
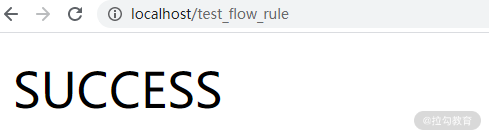
第一次执行成功
同一秒内再次刷新便会出现 “Blocked by Sentinel (flow limiting)”,代表服务已被限流降级。

第二次限流降级
到这里,我们已经利用 Sentinel 对微服务接口实施了初步的限流降级控制,Sentinel 还有很多高级的用法,我们在后面继续深入讲解。
小结与预告
这一讲我们主要对 Sentinel 进行入门学习,让你有个感性认识。本节讲解三方面内容,首先通过在工作中真实的案例分析了雪崩效应的产生与预防办法,其次介绍 Alibaba Sentinel Dashboard 与客户端的配置过程,最后演示了如何对微服务接口进行限流降级。
这里我预留一道讨论题:在架构设计时,你是如何预估某个接口线上运行时的 QPS 范围呢?你可以把自己的经验写在评论中,我们一起探讨。
下一讲,我们继续深入 Sentinel,了解 Sentinel 的高级特性与执行原理。

若有收获,就点个赞吧
0 人点赞
