前端性能优化方法与实战 - 前 58 集团技术副总监 - 拉勾教育
前几讲,我已经介绍了首屏时间、白屏、卡顿等性能指标采集和上报,按照性能优化体系的流程,接下来就该对性能 SDK 上报数据的处理了。那具体该怎么做呢?这就需要用到我们这一讲介绍的前端性能平台了。
还记得我之前提到的奥林匹亚项目吗?当时我们用的是一个开源的监控平台,只能够满足首屏时间和白屏时间等性能关键指标的展示需求,具体到一些个性化细分的性能数据,比如秒开率,数据瀑布流等,并无法满足。再加上业务开始对性能重视起来,不再想再亡羊补牢,还希望能未雨绸缪,提前发现故障,快速定位问题。于是,前端性能平台的自研需求就应运而生了。
如果你或者你所在的团队也想进一步提高前端性能,那么这一讲就要认真看了哦,前端性能平台可是性能优化体系当中不可缺少的一环。
什么是前端性能平台呢?
单从名字来看,它仿佛是一个后台系统,类似报表统计后台之类的。其实不然,前端性能平台是一个 Web 系统,主要包括后台的性能数据处理和前台的可视化展示两部分。
其中,数据处理后台主要是对 SDK 上报后的性能指标进行处理和运算,具体包括数据入库、数据清洗、数据计算,做完这些后,前台会对结果进行可视化展现,我们借助它就可以实时监督前端的性能情况。下图是性能平台大盘页的效果,主要对当前用户关注的性能模块进行展示,内容包括首屏时间、秒开率和采样 PV。
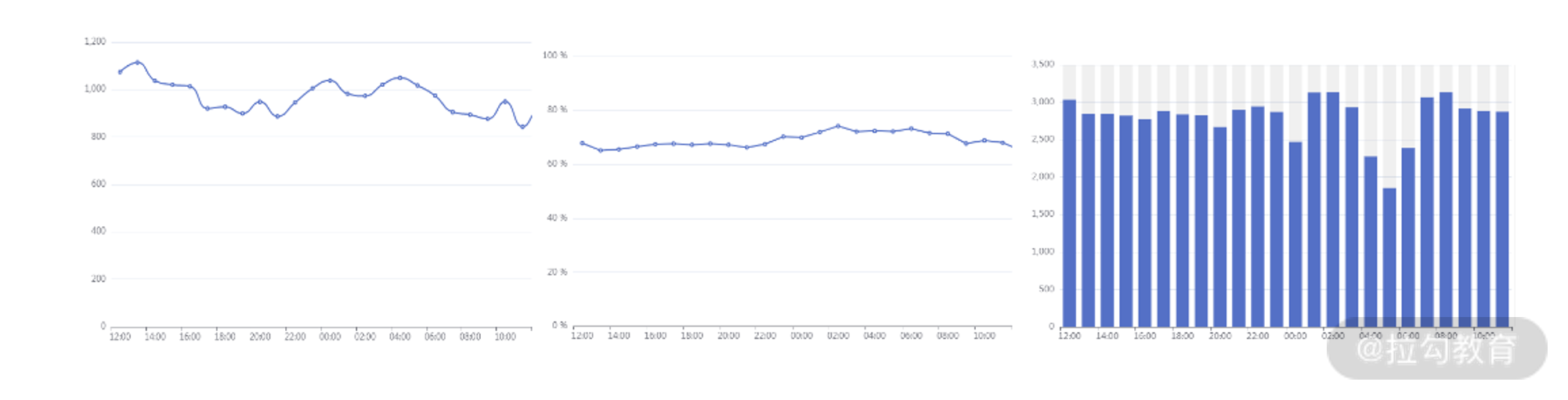
性能平台大盘页
那么,我们该如何搭建这样一个性能平台呢?
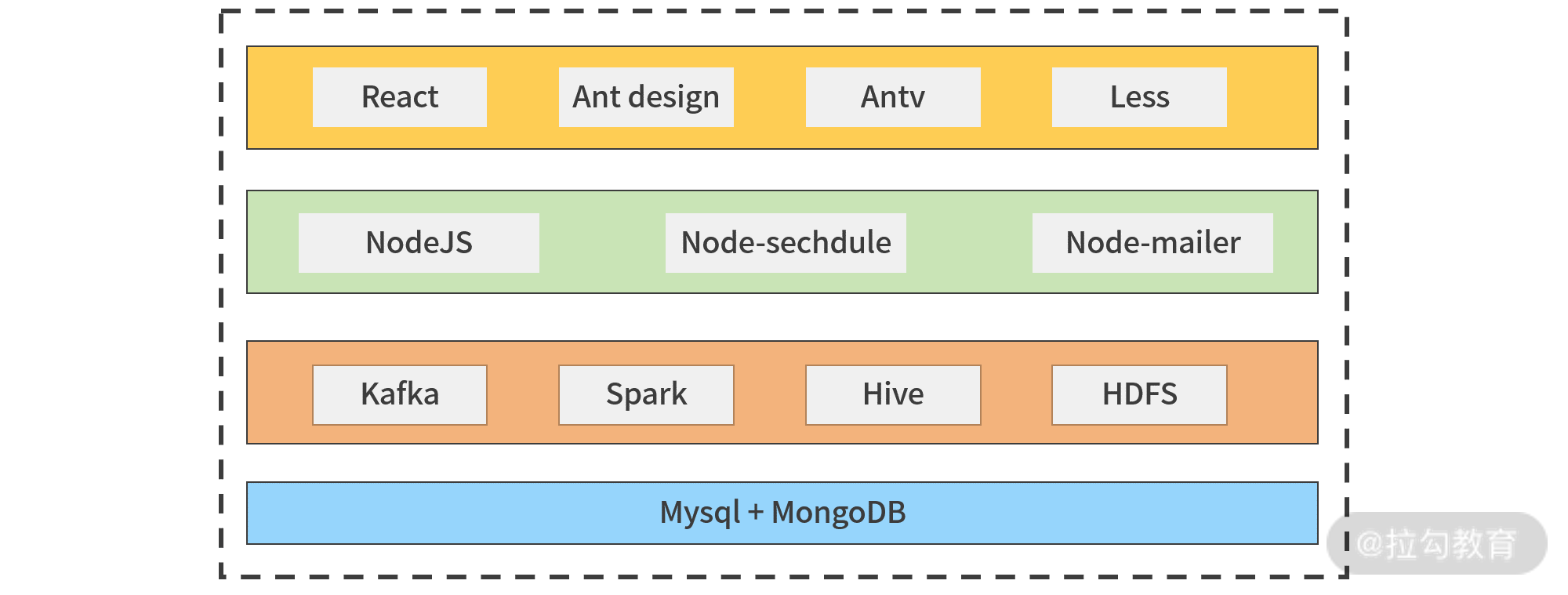
性能平台技术架构图
这是具体的技术架构图,从底层到前台大致情况如下:
- 数据接入层,主要是接收 SDK 上报的性能数据,做数据处理后入库,包含的技术有 Node.js、Node-sechdule、Node-mailer;
- 数据计算层,会对性能数据做计算处理,需要的技术有 Kafka、Spark、Hive、HDFS;
- 存储层,包括 MySQL + MongoDB ,性能平台需要的数据会来这里;
- 平台层,也就是展示给用户的部分,需要的技术有 React、Ant design、Antv、Less。
接下来我就将结合技术架构图来为你详细介绍下,如何一步步搭建性能平台。
性能数据处理后台
想要搭建性能平台,我们先来看它的性能处理后台情况。一般性能 SDK 上报数据的处理过程是这样的:
- 客户端借助 SDK 上报性能数据指标,数据接入层(图中绿色部分)接收相应数据,并做协议转换等简单处理后,作为生产者向 Kafka 写入数据;
- 数据计算层(图中橙色部分)作为消费者,从 Kafka 读数据存入 Hive(Hadoop 平台的存储表),Hadoop 平台借助 Spark 做数据分析计算;
- 借助 Hive 提供的接口,数据计算层使用 SQL 语句从 Hive 拉取计算后的数据到数据库平台(MongoDB),平台层取出数据,准备数据可视化展现的数据。
上述数据流程,对应的性能数据后台的搭建过程如下:
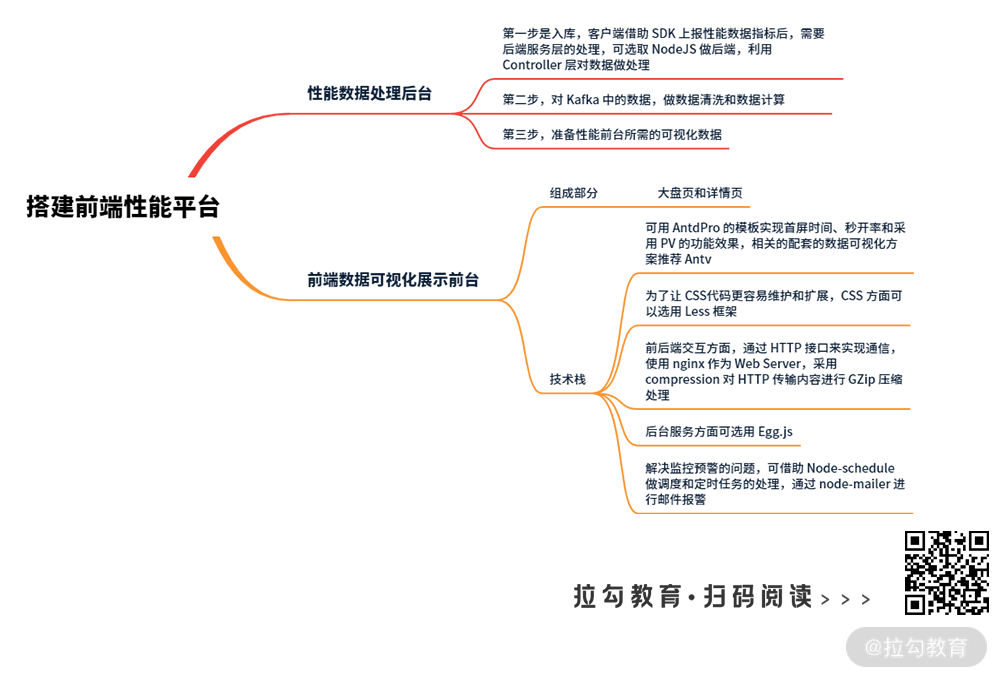
第一步是入库,客户端借助 SDK 上报性能数据指标后,需要后端服务层的处理,这里我们选取的是 NodeJS 做后端,利用 Controller 层对数据做处理。
为了避免数据库出现 “脏数据”(如空数据、异常数据),影响后续数据处理,我们将 SDK 上报的数据通过 URL 解析成 key-value 格式的数据,对数据进行空数据删除,异常数据舍弃等操作。然后我们让数据写进消息队列 Kafka。
为什么不是直接存入 Hive 呢?
因为客户端上报的性能数据量和用户规模有关。如果直接入库到 Hive,遇到高并发的时候,会因为服务器扛不住而导致数据丢失。与此同时,因为数据下游(数据的使用方,如数据清洗计算平台,性能预警模块)会有多个数据接收端,直接入库的话也会造成数据重复。
所以最好我们选择 Kafka,先让数据写进消息队列。Kafka 能通过缓存,慢慢接收这些数据,降低流量洪峰压力。同时,消息队列还有接收数据后将其删除的特点,可以避免数据重复的问题。
第二步,对 Kafka 中的数据,做数据清洗和数据计算。
数据清洗,是指针对性能上报单条数据进行核对校验的过程。所清洗的数据包括:
- 对重复数据的处理,即同一个用户网络出错时,多次重试导致上传了好几条首屏时间相关的数据;
- 对缺失数据的处理,虽然上报了首屏时间,但白屏时间或者卡顿时间计算时没能给出;
- 对错误数据的处理,即数据超出正常范围,出现负值或者超出极大值的情况。
这几种类型数据问题如果不处理,最终会影响计算结果的准确性。那么该怎么处理呢?
- 遇到重复数据,直接去重删除即可。
- 遇到缺失数据,我们在 Spark 平台上,先根据上报的 Performance 数据进行计算补全,如果无法补全的,就直接舍弃掉,不然会出现后续无法入库的情况。
- 遇到超出正常范围的数据,如负值或者超过 10 秒以上的数据,把它当作无效数据,直接舍弃掉。
做完数据清洗之后,我们还需要使用 Spark 做数据计算,为可视化展现准备数据。具体需要做以下数据计算:
- 首屏时间分布的计算,1s ~ 2s 占比多少,2s ~ 4s 占比多少;
- 秒开率的计算,首屏时间小于等于 1 秒的数据占比;
- 页面瀑布流时间的计算。
其中,页面瀑布流时间是对首屏时间的细分,包括 DNS 查询、TCP 链接、请求耗时、内容传输、资源解析、DOM 解析和资源加载的时间。这些细分时间点,是我们根据 SDK 上报的 Performance 接口数据指标计算出来的,前端工程师根据页面瀑布流时间,可以快速定位性能瓶颈点出现在哪个环节。
第三步,准备性能前台所需的可视化数据。
为了完成前台展现,性能平台需要登录功能,还需要做一些用户关注的模块信息,比如前端开发者添加关注的业务模块。我们可以用关系数据库去存储这些数据,具体可以选择 MySQL 完成账号权限系统和关注业务模块对应的数据表。
而性能数据,因为都是单条性能信息,相互之间并没有什么关系,可以用 MongoDB 做存储。具体来说,我们可以用 NodeJS 提供的定时脚本(Node-sechdule)从 Spark 取到数据导入到 MongoDB 中。
前端数据可视化展示前台
前端数据可视化展现前台,整体上只有两个页面,大盘页和详情页。
大盘页包括一个个业务的性能简图。每一个性能简图包括首屏时间、秒开率、采样 PV 数据。点击性能简图上的 “进入详情” 链接,就可以进入详情页。初次进入大盘页的时候,需要你登录并关注相关的业务,然后就可以在大盘首页看到相关的性能情况。
详情页的设计的初衷是为了对性能简图做进一步的补充,除了展示对应性能简图的秒开率、性能均值细节、白屏均值细节之外,还会展示终端信息,比如多少比例在 IOS 端,多少比例在 Android 端,以方便用户根据不同场景去做优化。
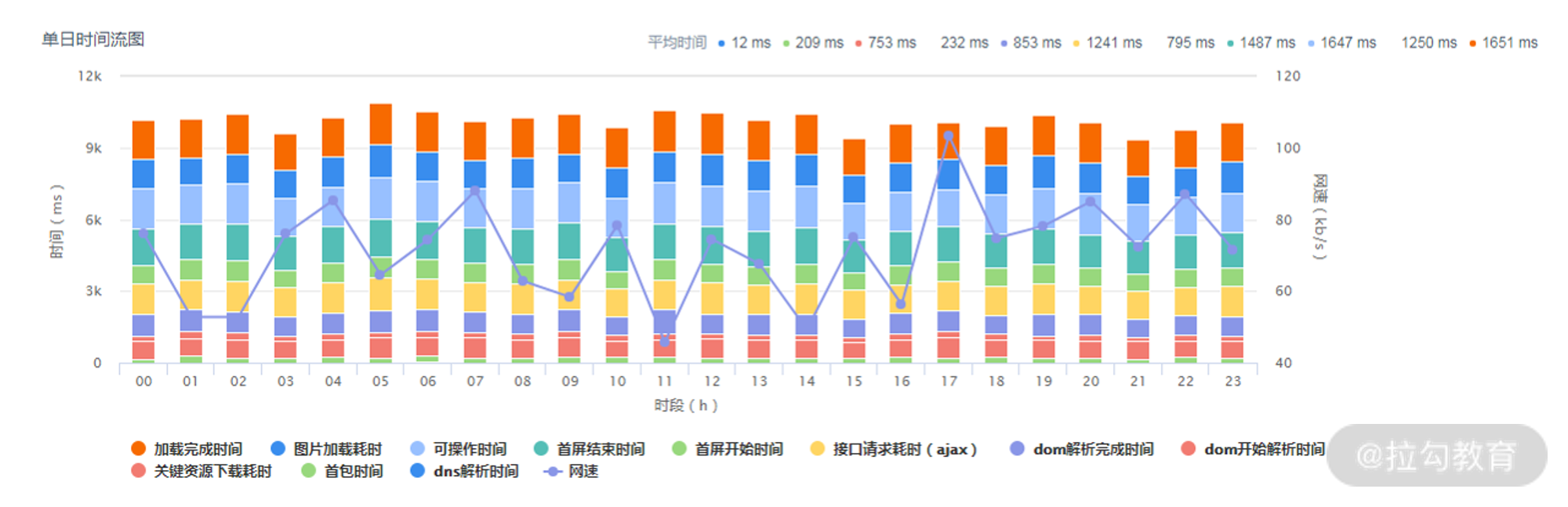
详情页性能均值
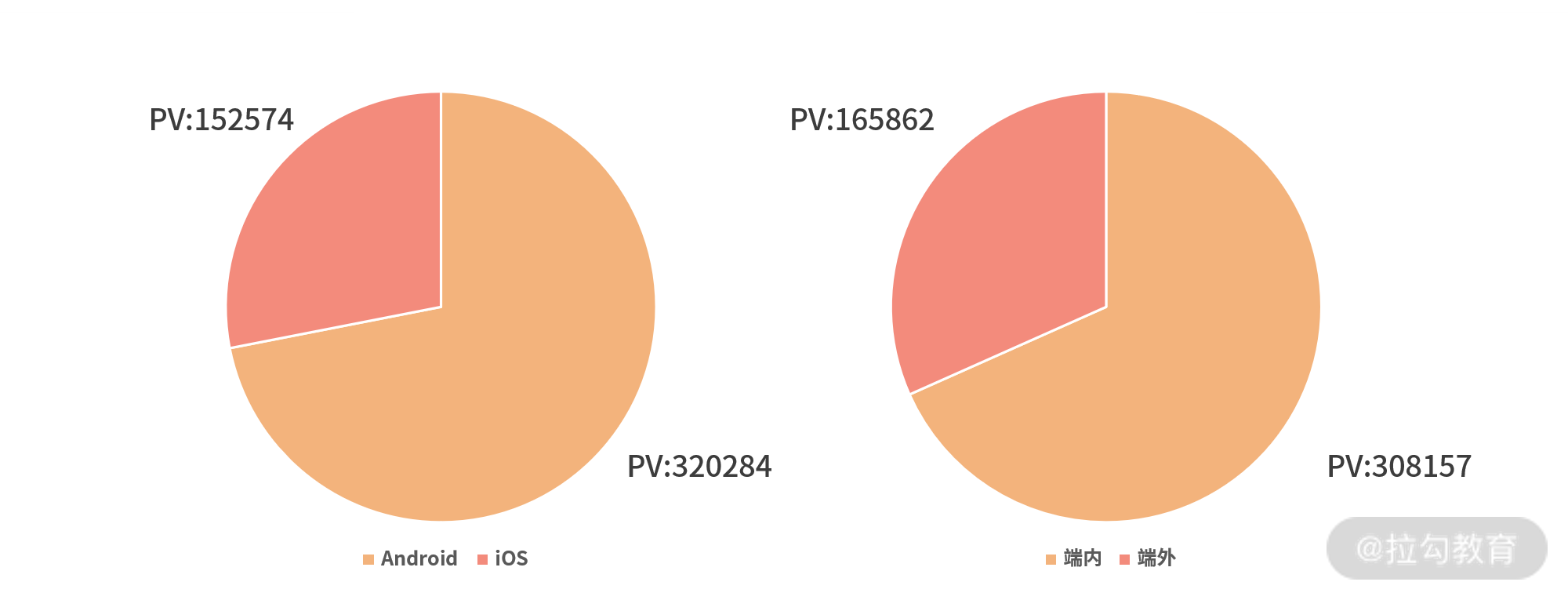
详情页终端类型
同时,为了解秒开率不达标原因或者首屏时间变慢的细节在哪里,我们会给出页面加载瀑布流,前面数据处理阶段已经提到可以使用的数据(包括 DNS 查询、TCP 链接、请求耗时、内容传输、资源解析、DOM 解析和资源加载的时间),套用 AntV (阿里巴巴集团的数据可视化方案)的瀑布流模板即可完成数据展现。
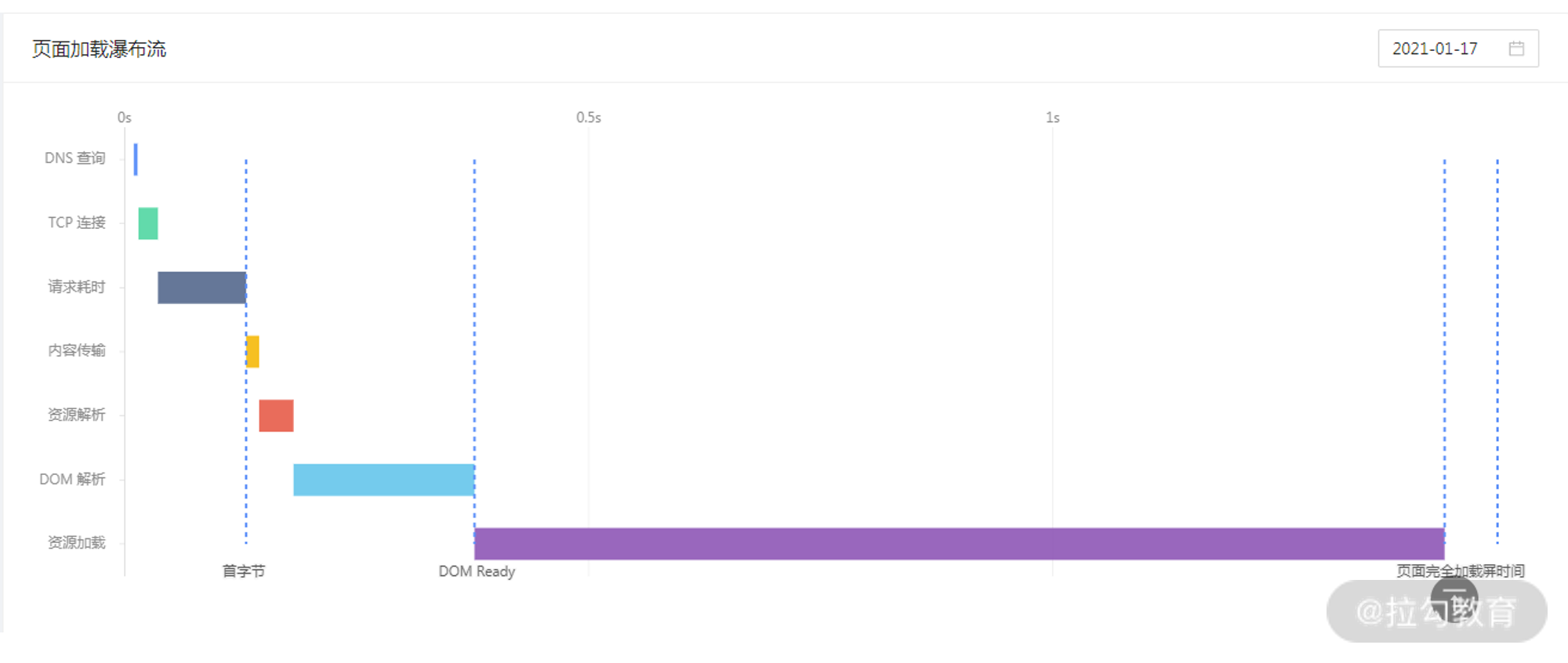
页面加载瀑布流
那么,大盘页和详情页如何实现的呢?
首先是前端展示技术栈的选择,对应技术架构图中的淡黄色部分,因为这两个页面都属于 PC 端后台页面,主要给公司前端开发者使用,功能上更多是数据可视化展示,非常适合用 React 技术栈做开发。
为了更好实现首屏时间、秒开率和采用 PV 的功能效果,我们使用 AntdPro 的模板,相关的配套的数据可视化方案,我推荐 Antv,因为它能够满足我们在首屏时间、秒开率等性能指标的展示需求,用起来比较简单(开箱即用),功能灵活且扩展性强(比如秒开率部分,要自定义一些图形,能够较好满足)。
大盘页和详情页的数据展示效果比较丰富多样,相应的 CSS 代码逻辑就比较复杂,为了让 CSS 代码更容易维护和扩展,CSS 方面可以选用 Less 框架。
接下来是前后端交互方面,为了让前后台更独立,大盘页、详情页与后端的通信通过 HTTP 接口来实现,使用 nginx 作为 Web Server。为了让传输更高效,我们采用 compression 对 HTTP 传输内容进行 GZip 压缩处理。
最后是后台服务部分,为了让性能平台开发过程更简单,效率更高,同时平台本身的性能体验更流畅,后台服务方面可以选用 Egg.js(基于 NodeJS 的开发框架)做开发,进行数据处理和存储服务。
为了解决监控预警的问题,我们借助 Node-schedule 做调度和定时任务的处理,通过 node-mailer 进行邮件报警。有关预警部分的实现细节,我会在下一讲展开介绍。
小结
好了以上就是性能监控平台的核心实现,如果公司没有类似的埋点平台,那么这一讲非常适合你,如果已经有了,性能上报直接走埋点平台处理就好,基本上性能上报处理就不需要自己做了,可以专注于第二部分前端可视化交互。
另外性能指标里有很多内容,比如 Dom ready 指标,完全加载时间指标,这些通过 Performance 接口也能取到,但根据我过往的经验,最有用的性能指标还是秒开率、首屏时间、白屏时间、卡断指标。
好了,性能平台实践的内容就到这里了。在这里给你留一个小问题:
业界在统计首屏时间时,都会统计一下是否首次访问,这个是怎么实现的呢?
欢迎在评论区留言和我沟通,下一讲我会详细介绍下如何进行效果评估、监控预警及问题诊断。

若有收获,就点个赞吧
0 人点赞
