前端面试宝典之 React 篇 - 某一线大厂资深前端工程师 - 拉勾教育
如果你在社区留言询问 React 的状态管理库用什么,那评论区的回复会直接争破头,“Redux 天下第一”“Mobx 万岁”,当然还有使用 Hooks 的 useReducer 派。但如果说起 React 路由,那毫无争议就是 React Router 了,别无二家。对于这样一个在生态中具有统治地位的常用库,我们就必须严肃对待了,因为在面试中大概率会被问到,而问的方向往往会从实现原理与工作方式两个维度去展开。这一讲我们就来具体分析下这个问题应该如何作答。
审题
其实在真实的面试中通常不会出现像标题这样的提问方式,会更细化一点,比如 “它的原理是什么”“它的代码组织方式是怎样的”“它的设计模式是什么样的”“某个功能是如何实现的”,等等。我们不会去穷尽所有细化的问题,而是通过梳理脉络的方式去掌握它。这些问题实际上分为两类——what is it 和 how does it works,也就是标题中所提到的实现原理与工作方式。
首先聊一下实现原理。实现原理应该由外到内去探索,每个库的根本原理是立足于自身生态以外的。React Router 的基础原理是什么呢?这需要我们跳出 React 生态去寻求答案,也只有掌握了根本原理后才能回到 React Router 内部,去梳理它的实践方案。
其次是工作方式。工作方式的探索应该是从整体到局部的。从宏观视角挖掘 React Router 的架构设计模式,比如 React Router 内部的模块有哪些,分别采取了什么模式进行设计并运行,又是如何完成协同工作的;从局部挖掘模块的实现方式,比如 A 模块是如何实现的,其内在的原理又是怎么样的。
那么在理清了以上的主线之后,我们才不会惧怕更细化的问题,这就是抓大放小,抓主要放次要。
承题
基于以上的分析可以整理答题思路了,将答案简化到两个方向上去。
- 实现原理,包含基础原理与 React Router 内部的实践方案。
- 工作方式,包含整体设计模式与关键模块的实现方案。那如何定义关键模块呢?最简单的方案莫过于打开官方文档扫一眼提到过的模块,那就是最常用且最容易被提问的知识点。当然你也许会想,这样去准备会不会太简单了,面试官不会拿更冷门儿的内容来提问吗?要知道,生僻冷门的知识点在面试中就算考倒了应聘者也没有什么意义。面试是为了甄别应聘者的技能熟练度,所以只要抓住常用内容就好了。
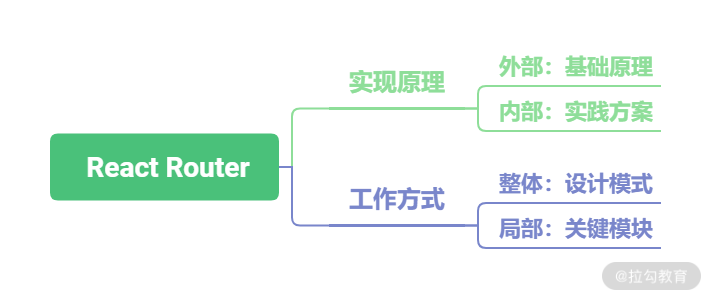
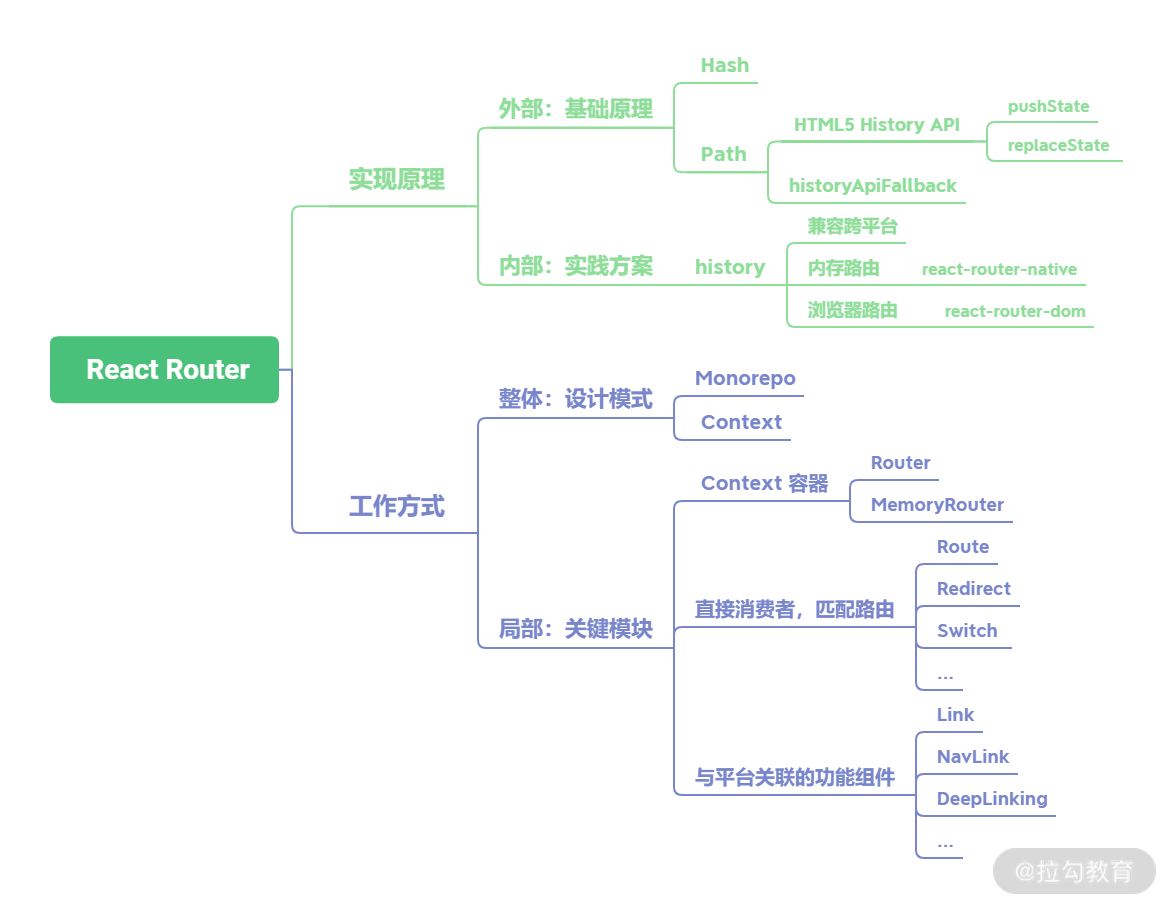
破题
实现原理
基础原理
现在的网页大部分是以单页应用(SPA)的方案完成交付。当我们访问 http://example.com/a 或者 http://example.com/b 时,路由完全由前端开发者在网页层自行控制。通俗点来讲,就是通过浏览器中的 JavaScript 控制页面路由。但在过去的多页应用(MPA)时代,路由完全是由服务端进行控制的。
为什么会有这样一个变化呢?技术并不是凭空出现的,往往先有需求,再有方案,只有理解其中的原因才能体会技术的深刻变化。
前端在路由上经历了四次变化,最初的路由管理权由后端完全控制,前端页面通过在模板中插入后端语言变量的方式完成开发。这个时代最明显的技术特征是 Java 的 JSP。这样的开发方式效率很低,在工作协同上,前后端相互严重依赖。
但当 AJAX 技术兴起后,前端网页不再与后端页面直接耦合了,工程也得以分离。这个时代最明显的特征是多个 HTML 页面,并由 Nginx 等静态文件服务完成托管,这是第二次变化。在这次变化中解除了前后端开发者的直接依赖,前端开发者可以自行维护独立的前端工程。但在这个工程中,有多个 HTML 需要维护,它们各自分离,需要引用不同的 JS 与 CSS,对于工程复用又是一个难题。
于是迎来了第三次变化,在这次变化中,最明显的是 JavaScript 成为前端开发的主角,无论是 HTML、CSS 还是路由都通过 JavaScript 来控制。在这个阶段中,最具特征的技术栈是AngularJS。我们要知道,前端并不能真正地去控制路由,比如请求 http://example.com/a 与 http://example.com/b,一定会返回两个页面,这就需要一种方案去模拟路由,所以 Hash 路由作为一个折中的解决方案登上了舞台。类似下面这样,通过在 Hash 中添加路由路径的方式控制前端路由。
Hash 路由在实践上非常成功,使得开发者的注意力得以从前端的繁杂信息中进一步收敛。在现代前端工程中,你会发现大部分的代码都是由 JavaScript 独立完成的,这在最初是完全不可想象的。
接下来随着浏览器对 HTML5 中 History pushState 的支持,前端路由迎来了第四次变化。这次我们终于可以不再写 #a 这样的路由了,而是回归到最初的写法——http://example.com/a。
那为什么 History pushState 可以办到呢?它分两部分进行。
第一部分在浏览器完成,HTML5 引入了 history.pushState() 和 history.replaceState() 两个函数,它们分别可以添加和修改历史记录条目。在浏览器侧的表现行为则是:
- pushState 修改当前浏览器地址栏中的网址路径;
- replaceState 则是替换网址路径。
使用 pushState 和 replaceState 时,浏览器并不会刷新当前页面,而仅仅修改网址,此时如果用户刷新页面才会重新拉取。 所以需要注意,既然 http://example.com 本身指向编译产出物 index.html,那么 http://example.com/a 也需要指向 index.html,那就需要在服务端去配置完成。
所以第二部分是在服务端的进行配置修改,被称为 historyApiFallback。如果你了解过 webpack 的配置,那么一定看见过 historyApiFallback,它的作用就是将所有 404 请求响应到 index.html。那么同理需要在 Nginx 或者 Node 层去配置 historyApiFallback,同样是将 404 请求响应到 index.html 就可以了。至此,前端路由才算完全完成,那 React Router 内部是怎样呢?
实践方案
翻开 React Router 的代码,你会发现 React Router 提供了三个库,分别是 react-router、react-router-dom 及 react-router-native。但如果细看,你会发现 react-router 是没有 UI 层的,react-router-dom = react-router + Dom UI,而 react-router-native = react-router + native UI。DOM 版本与 Native 版本最大限度地复用了同一个底层路由逻辑,如下图所示。
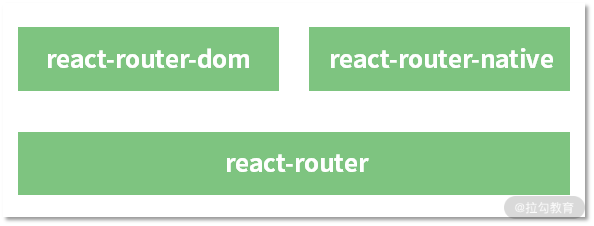
在 DOM 版本中提供的基础路由是 BrowserRouter,它的源码是这样的:
import { Router } from "react-router";import { createBrowserHistory as createHistory } from "history";class BrowserRouter extends React.Component {history = createHistory(this.props);render() {return <Router history={this.history} children={this.props.children} />;}}
那这段源码做了什么呢?我们可以看到在 render 部分直接应用了 react-router 中的 Router 组件,在 history 属性中赋值了 createBrowserHistory 生成的变量。在 react-router-native 版本中代码完全一样,只是把 createBrowserHistory 替换成了 createMemoryHistory。所以真正的路由处理角色其实是 history 库。
总结一下,在 React Router 中路由通过抽象 history 库统一管理完成,history 库支持 BrowserHistory 与 MemoryHistory 两种类型。打开源码看一下 BrowserHistory 实际上调用的就是浏览器的 History API,也就是基础原理的部分,那为什么还有 MemoryHistory 呢?因为 React Native 并不是运行在浏览器环境中,所以需要在内存中构建一个自己的版本,原理上就是一个数组,有兴趣的同学可以看一下这块代码的 886 行。
工作方式
设计模式
Monorepo
要理解 React Router 的设计模式,我们不妨先看一下代码目录结构。如下图所示,整个代码被分割成了四个文件夹,这四个文件夹又各自是一个库,那这四个库如何联动的呢?这里用到了Monorepo的设计。
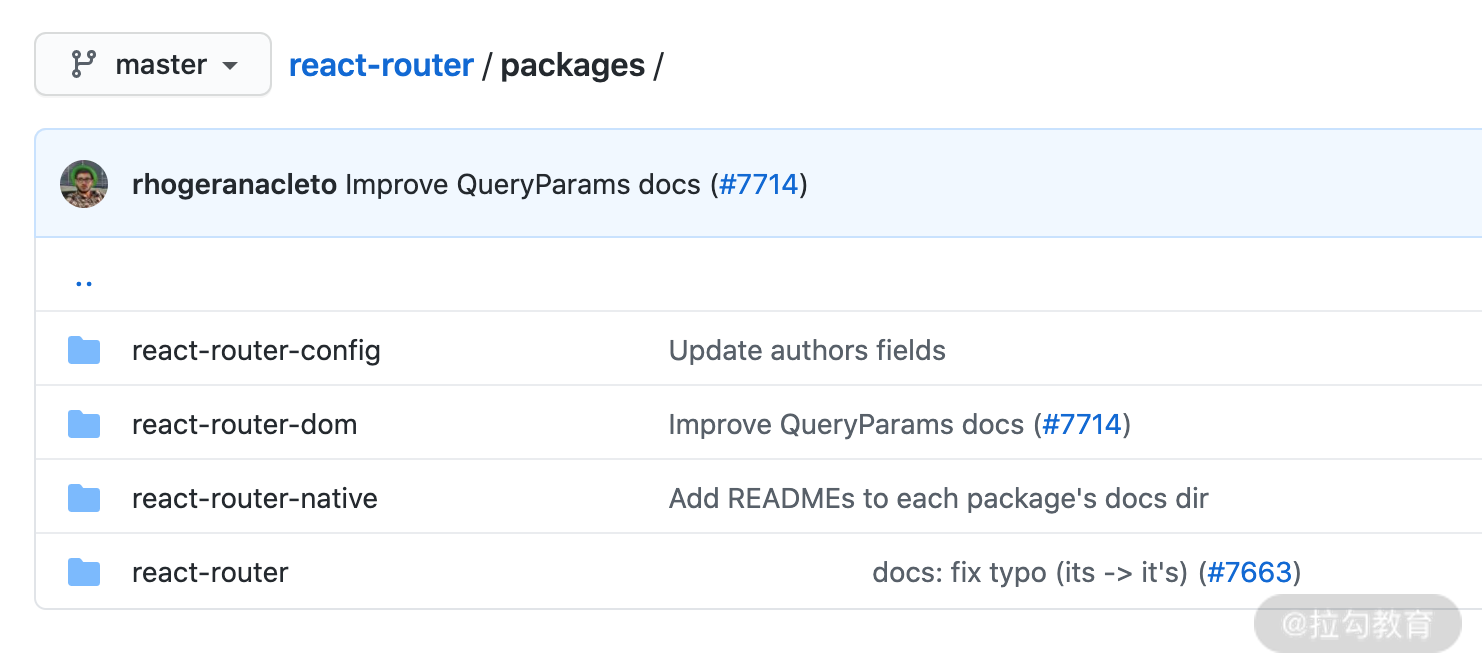
与 Monorepo 相对的概念是Multirepo。Multirepo 就是我们常用的开发模式,一个仓库对应一个工程,子团队自行维护。如果这几个工程存在强协同,需要在一个迭代周期中完成新功能上线,那沟通协调成本就非常大了,你需要等别的工程发布更新后才能开发。所以在这里 React Router 使用了 Monorepo 的工程架构,使工程代码对团队中的每一个人都具备透明度。在同一次迭代中,库之间互相引用代码也更为容易。关于 Multirepo 和 Monorepo 的区别如下图所示:

通常会使用 Lerna 作为开发管理 Monorepo 的开发工具,它的主要用户包括 Babel、React、umi、React Router 等。个人感觉最有意思的点是 Lerna 这个名字非常贴切。Lerna 是希腊神话中的九头蛇,赫拉克勒斯的十二功绩之一就是猎杀九头蛇。看着九头蛇这个形象,像不像一个仓库里面存放了多个可用的库呢?

图片源自 React 官网
Context
第二个比较重要的设计模式是使用 Context API 完成数据共享。在第 05 讲 “如何设计 React 组件?”中详细介绍了相关的内容,这里就不再赘述了。你可以自行阅读下 packages/react-router/modules/RouterContext.js、packages/react-router/modules/Router.js 文件。除此以外再阅读下 packages/react-router/modules/withRouter.js 的源码。
关键模块
在了解整体架构设计后,我们就可以开始梳理关键模块了。那该怎么梳理呢?梳理其实就是一种通过结构化展示认知的方式。你可以从整体到局部,从宏观到微观,从外到内。但如果没有很好的思路,那就分类,分类是永远不过时的梳理技巧。从功能角度,我们可以把 React Router 的组件分为三类:
- Context 容器,分别是 Router 与 MemoryRouter,主要提供上下文消费容器;
- 直接消费者,提供路由匹配功能,分别是 Route、Redirect、Switch;
- 与平台关联的功能组件,分别是 react-router-dom 中的 Link、NavLink 以及 react-router-native 中的 DeepLinking。
在有分类以后,是不是感觉对整体模块有一种尽在掌握的感觉?那接下来就可以答题了。
答题
React Router 路由的基础实现原理分为两种,如果是切换 Hash 的方式,那么依靠浏览器 Hash 变化即可;如果是切换网址中的 Path,就要用到 HTML5 History API 中的 pushState、replaceState 等。在使用这个方式时,还需要在服务端完成 historyApiFallback 配置。
在 React Router 内部主要依靠 history 库完成,这是由 React Router 自己封装的库,为了实现跨平台运行的特性,内部提供两套基础 history,一套是直接使用浏览器的 History API,用于支持 react-router-dom;另一套是基于内存实现的版本,这是自己做的一个数组,用于支持 react-router-native。
React Router 的工作方式可以分为设计模式与关键模块两个部分。从设计模式的角度出发,在架构上通过 Monorepo 进行库的管理。Monorepo 具有团队间透明、迭代便利的优点。其次在整体的数据通信上使用了 Context API 完成上下文传递。
在关键模块上,主要分为三类组件:第一类是 Context 容器,比如 Router 与 MemoryRouter;第二类是消费者组件,用以匹配路由,主要有 Route、Redirect、Switch 等;第三类是与平台关联的功能组件,比如 Link、NavLink、DeepLinking 等。
总结
本讲我们聊了 React Router 的相关内容。但我希望你掌握的不只是 React Router 的内容,而是一套对于开源库的学习方法,通过这个方法再举一反三到其他的开源库中完成学习并掌握。
在这里为你留一个关于 React Router 的小问题:如果我当前在 A 页面编辑文字内容,不小心点击了返回,可能会退回 B 页面,那如何阻断这个过程呢?希望你能将解决方案留言在评论区。
下一讲是本专栏的最后一篇,我将和你一起梳理 React 生态。

《大前端高薪训练营》
对标阿里 P7 技术需求 + 每月大厂内推,6 个月助你斩获名企高薪 Offer。点击链接,快来领取!

若有收获,就点个赞吧
0 人点赞
