前端性能优化方法与实战 - 前 58 集团技术副总监 - 拉勾教育
在前端性能优化工作当中,前端开发人员接入性能监控平台过程中文档不全,调试工具缺乏,上报过程中日志量过大,这类问题经常出现。
像我当初完成奥林匹亚项目之后,公司的业务开始从 PC 端迁移到移动端,然后各种复杂页面就逐渐出现了,比如 PC 站下的 IM 页面、App 下的 H5 动画页面、服务端渲染页面、可视化搭建平台页面等。为了让这些页面接入性能监控平台,通常需要修改性能统计脚本后才可以。同时,由于各业务频繁升级性能脚本,导致最初的文档内容有点跟不上了,测试也变得非常麻烦,需要在控制台打印很多日志。
在工作当中,遇到此类问题,你是怎么解决的呢?这一讲我们就专门来介绍下,如何通过设计性能 SDK(Software Development Kit,软件开发工具包),制定合理的上报策略来解决性能指标采集过程中的难题。
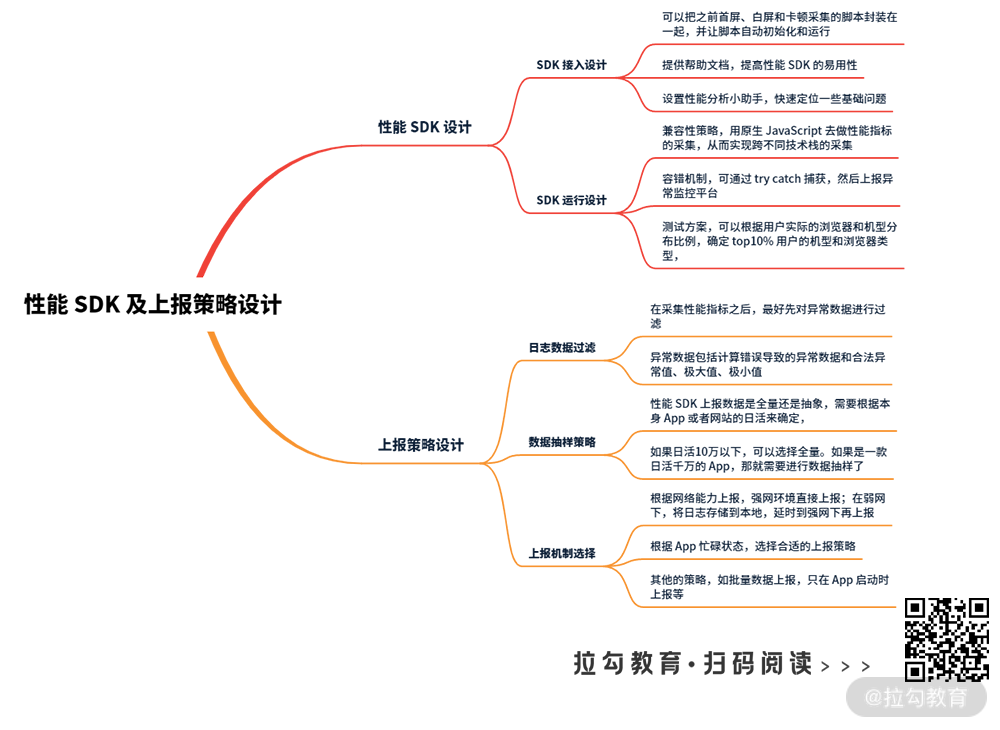
性能 SDK 设计
SDK 是指开发者为特定的软件、平台、操作系统提供的开发工具集,比如,微信为小程序提供的微信 JS-SDK。
不过,在本讲,我主要介绍性能 SDK,即为公司各个产品业务提供性能统计的 JS SDK。它包括 API 接口、工程引入、文档平台、开发调试工具,主要是将性能采集代码和上报策略封装在一起,通过采集首屏、白屏等指标数据,然后上报到性能平台后端进行处理。
由于性能 SDK 最终是给各个业务使用的,所以它的设计要满足在接入性能监控平台时,简单易用和运行平稳高效,这两个要求。
那么,如何实现这两个目的呢?
SDK 接入设计
要保证 SDK 接入简单,容易使用,首先要把之前首屏、白屏和卡顿采集的脚本封装在一起,并让脚本自动初始化和运行。
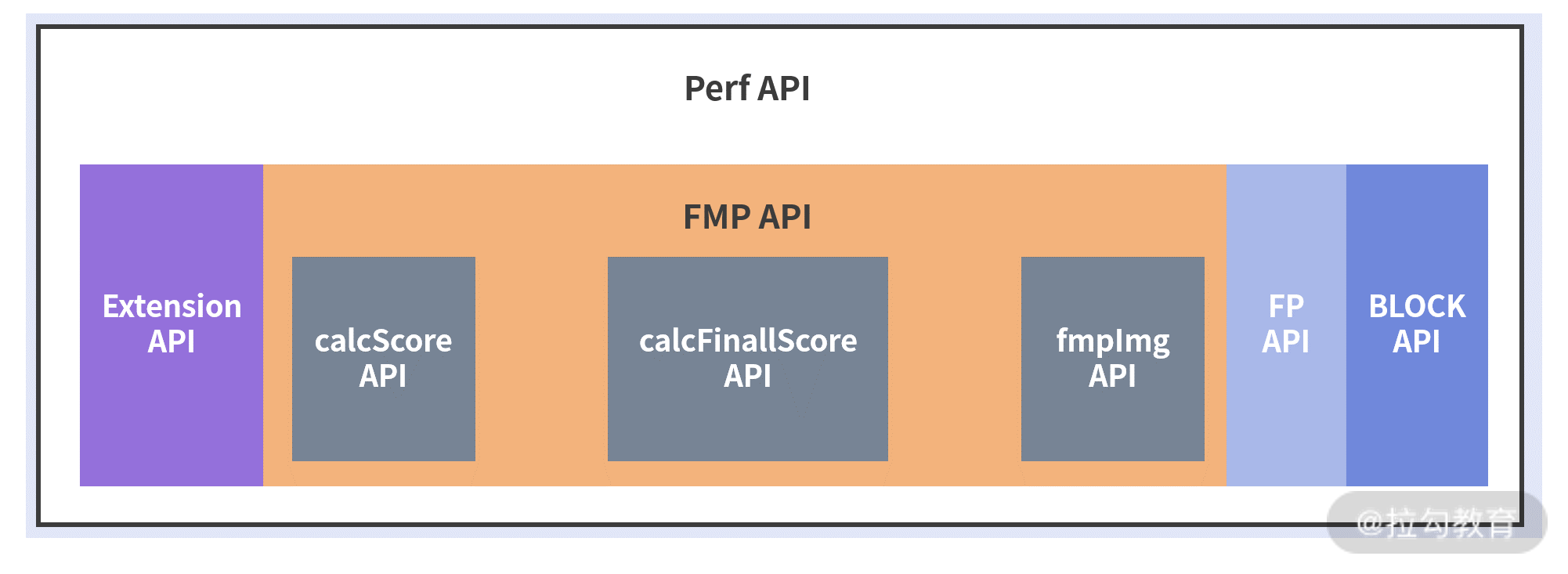
性能 SDK 相关 API
具体来说,首屏采集的分数计算部分 API(calculateScore)、变化率计算的 API(calFinallScore)和首屏图片时间计算 API(fmpImg)可以一起封装成 FMP API。其中首屏图片计算 API 因为比较独立,可以专门抽离成一个 util,供其他地方调用。白屏和卡顿采集也类似,可以封装成 FP API 和 BLOCK API。
还有一个 ExtensionAPI 接口,用来封装一些后续需要使用的数据,比如加载瀑布流相关的数据(将首屏时间细分为 DNS、TCP 连接等时间),这些数据可以通过浏览器提供的 performance 接口获得。
为了进行首屏、白屏、卡顿的指标采集,我们可以封装 Perf API,调用 FMP、FP、BLOCK、ExtensionAPI 四个 API 来完成。因为是调用 window.performance 接口,所以先做环境兼容性的判断,即看看浏览器是否支持 window.performance。
最终我们接入时只要安装一个 npm 包,然后初始化即可,具体代码如下:
npm install @common/Perf -S;import { perfInit } from '@common';perfInit ();
或者以外链的形式接入:
<script type="text/javascript">https:try {perfInit ();} catch (err) {console.warn(err);}
除了性能 SDK 自身的方案设计之外,提供帮助文档(如示例代码、 QA 列表等),也可以提高性能 SDK 的易用性。
具体来说,我们可以搭建一个简单的性能 SDK 网站,进入站点后,前端工程师可以看到使用文档,包括各种平台下如何接入,接入的示例代码是怎样的,接入性能 SDK 后去哪个 URL 看数据,遇到异常问题时怎么调试,等等。
另外,还可以设置性能分析小助手,快速定位一些基础问题。这个小助手怎么实现呢?我们在 SDK 中通过检测访问页面的 URL 是不是加了调试参数(PERF_DEV_MODEL=PERF_DEV_MODEL),如果访问的页面 URL 中加了调试参数,打开页面后就可以看到一个性能分析小助手的圆形图标。通过它,前端工程师可以快速进入诊断模式,定位一些基础问题,如性能 SDK 初始化失败,采集数据异常,发送的请求参数不正确等问题。
但有时候前端工程师在接入时也会遇到帮助文档里也没有提供解决办法的问题。这时怎么办呢?可以借助代码存放的 Gitlab 平台,让前端工程师通过 issue 的方式提交问题,看到问题后我们及时回复解决。如果问题很紧急,也可以通过平台上的联系方式联系开发者,开发者解决完问题后,发布代码并通知前端工程师。
SDK 运行设计
SDK 如果想运行高效,必须有好的兼容性策略、容错机制和测试方案。
所谓兼容性策略,就是性能 SDK 可以在各个业务下都可以稳定运行。
我们知道,前端性能优化会面临的业务场景大致有:
- 各类页面,如平台型页面、3C 类页面、中后台页面;
- 一些可视化搭建的平台,如用于搭建天猫双十一会场页这种用于交易运行页面的魔方系统;
- 各个终端,如 PC 端,移动端,小程序端等。
这就要求性能 SDK 要能适应这些业务,及时采集性能指标并进行上报。那具体怎么做呢?
一般不同页面和终端,它们的技术栈也会不同,如 PC 端页面使用 React,移动端页面使用 VUE 。这个时候,我们可以尽可能用原生 JavaScript 去做性能指标的采集,从而实现跨不同技术栈的采集。
不同终端方面,我设计了一个适配层来抹平采集方面的差异。具体来说,小程序端可以用有自己的采集 API,如 minaFMP,其他端可以直接用 FMP,这样在性能 SDK 初始化时,根据当前终端类型的不同,去调用各自的性能指标采集 API。
容错方面怎么做呢?
如果是性能 SDK 自身的报错,可以通过 try catch 的方式捕获到,然后上报异常监控平台。注意,不要因为 SDK 的报错而影响引入性能 SDK 页面的正常运行。
除此之外,好的自测和 QA 的测试也是性能 SDK 运行平稳的一大保障。
在开发 SDK 时,我们可以根据用户实际的浏览器和机型分布比例,确定 top10% 用户的机型和浏览器类型。然后在每次开发完成并进行代码 review 后,使用这些机型和浏览器类型进行自测。
另外,在升级性能 SDK 时,不论功能大小,为了保证不影响到所有业务方线上稳定运行,最好都进行一次冒烟测试用例。
上报策略设计
上报策略是指在性能指标采集完成后,上报到性能平台所采用的具体策略。比如通过 SDK 上报到性能平台后端,是数据直接上传还是做一些过滤处理,是全量上传数据还是抽样,是选择 H5 接口上报还是 native 接口上报,等等,这些都需要我们确定一下。
日志数据过滤
我的建议是,在采集性能指标之后,最好先对异常数据进行过滤。
异常数据分一般有两类,第一类是计算错误导致的异常数据,比如负值或者非数值数据,第二类是合法异常值、极大值、极小值,属于网络断掉或者超时形成的数值,比如 15s 以上的首屏时间。
负值的性能指标数据影响很大,它会严重拖低首屏时间,也会把计算逻辑导致负值的问题给掩盖掉。
还有首屏时间是非数值数据的时候也非常麻烦,比如首屏时间是 “200”,我这里使用引号是因为它是字符串类型,在采集过程中计算时,遇到加法时,会出现 “200”+30=20030,而不是你预期的 230 的情况。后来遇到负值数据和非数值数据后,我都会用程序打印日志记录,并上报到错误异常平台。
数据抽样策略
性能 SDK 上报数据是全量还是抽象,需要根据本身 App 或者网站的日活来确定,如果日活 10 万以下,那抽样就没必要了。如果是一款日活千万的 App,那就需要进行数据抽样了,因为如果上报全量日志的话,会耗费大量用户的流量和请求带宽。
像 58 同城,我们做的就是 10% 的抽样率,这也有百万级的数据了。除了在 SDK 里面设置抽样策略,业界还有通过服务器端下发数据抽样率的方式,来动态控制客户端向服务器端上报性能数据的量。比如,双十二运营活动当天,日活跃用户激增,抽样率由 10% 降低到 5%,可以大大降低运营活动时统计服务器的负载。
上报机制选择
一般,为了节省流量,性能 SDK 也会根据网络能力,选择合适的上报机制。在强网环境(如 4G/WIFI),直接进行上报;在弱网(2G/3G)下,将日志存储到本地,延时到强网下再上报。
除了网络能力,我们还可以让 SDK 根据 App 忙碌状态,选择合适的上报策略。如果 App 处于空闲状态,直接上报;如果处于忙碌状态,等到闲时(比如凌晨 2-3 点)再进行上报。
除此之外,还有一些其他的策略,如批量数据上报,默认消息数量达到 30 条才上报,或者只在 App 启动时上报等策略,等等。你可以根据实际情况进行选择。
在上报能力选择方面,由于使用 native 接口上报时,SDK 可以复用客户端的请求连接,采取延时上报或者批量上报等策略。所以虽然我们支持 H5 和 native 两种接口上报方式,但实际工作中建议优先使用 native 接口进行数据上报。
小结
这一讲我们主要介绍了性能 SDK 的设计原则和上报策略,在这个过程中还需要注意一点。 那就是, 在性能指标上报之前,也就是请求指标转换为请求参数环节,SDK 内部最好做一次参数校验处理。
为什么我会强调这一点呢?因为我曾经遇到过类似问题。当初在一个业务接入性能 SDK 后,上报性能数据时出现了平台看不到对应指标数据的情况。我定位问题后发现,原来是 API 接口取性能指标数据时,把 Windows 对象上的某个方法给字符串化后当作参数了。这个参数内容特别多,直接导致 GET 请求时参数过长,出现报错,后端并没有拿到请求参数。
最后,在这里给你留一个问题:
在前面的上报策略时,我提到了数据抽样,如果是抽样的数据,怎么能确保性能异常的数据不会被漏掉呢?
你可以把回复写在下方的留言区哦。
一般来说,性能指标数据通过 SDK 采集完成后,会上报给性能监控平台,通过它来对性能进行监控和预警,那么这个平台怎么搭建呢?下一讲,我将和你介绍下如何从 0 到 1 搭建性能优化平台。再见。

若有收获,就点个赞吧
0 人点赞
