前端基础建设与架构 - 前百度资深前端开发工程师 - 拉勾教育
不管是团队的扩张还是业务的发展,都会导致项目代码量出现爆炸式增长。为了防止 “野蛮生长” 现象,我们需要有一个良好的技术选型和成熟的架构做支撑,也需要团队中每一个开发者都能用心维护项目。在此方向上,除了人工 code review 以外,相信大家对于一些规范工具并不陌生。
作为一名前端工程师,在使用现代化工具的基础上,如何尽可能发挥其能量?在必要的情况下,如何开发适合自己团队需求的工具?这一讲,我们将围绕这些问题展开。
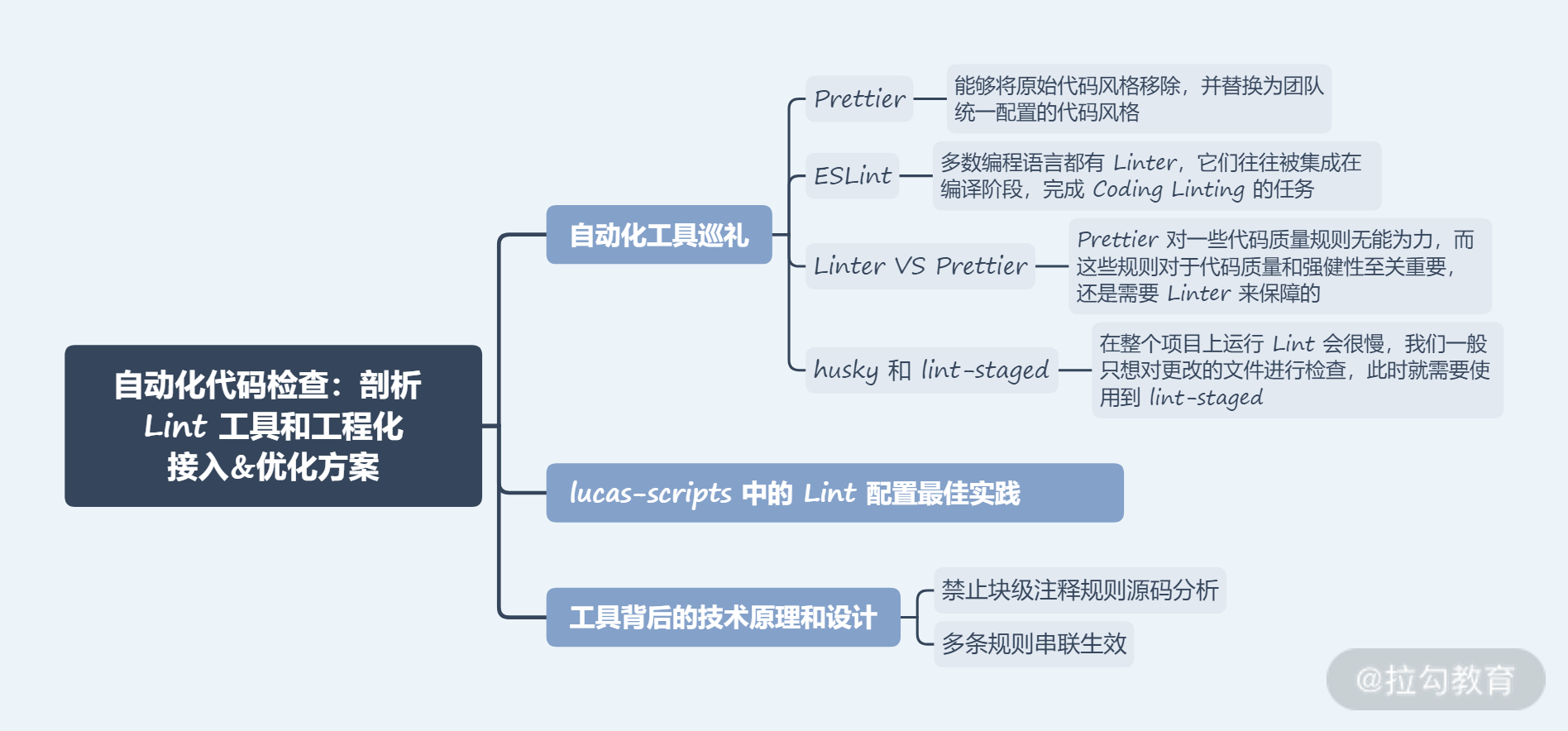
自动化工具巡礼
现代前端开发,“武器” 都已经非常自动化了。不同工具的分工不同,我们的目标是合理结合各种工具,打造一条完善的自动化流水线,以高效率、低投入的方式,为我们的代码质量提供有效保障。
Prettier
首先从 Prettier 说起,英文单词 prettier 是 pretty 的比较级,pretty 译为 “漂亮、美化”。顾名思义,Prettier 这个工具能够美化我们的代码,或者说格式化、规范化代码,使其更加工整。它一般不会检查我们代码具体的写法,而是在 “可读性” 上做文章。目前支持包括 JavaScript、JSX、Angular、Vue、Flow、TypeScript、CSS(Less、SCSS)、JSON 等多种语言、数据交换格式、语法规范扩展。
总的来说,它能够将原始代码风格移除,并替换为团队统一配置的代码风格。虽然几乎所有团队都在使用这款工具,这里我们还是简单分析一下使用它的原因:
- 构建并统一代码风格
- 帮助团队新成员快速融入团队
- 开发者可以完全聚焦业务开发,不必在代码整理上花费过多心思
- 方便,低成本灵活接入,并快速发挥作用
- 清理并规范已有代码
- 减少潜在 Bug
- 丰富强大的社区支持
当然,Prettier 也可以与编辑器结合,在开发者保存后立即进行美化,也可以集成到 CI 环境中,或者 Git pre-commit 的 hook 阶段。比如使用 pretty-quick:
yarn add prettier pretty-quick husky --dev
并在 package.json 中配置:
{"husky": {"hooks": {"pre-commit": "pretty-quick --staged"}}}
在 husky 中,定义 pre-commit 阶段,对变化的文件运行 Prettier,—staged 参数表示 pre-commit 模式:只对 staged 的文件进行格式化。
这里我们使用了官方推荐的 pretty-quick 来实现 pre-commit 阶段的美化。这只是实现方式之一,还可以通过 lint-staged 来实现,我们会在下面 ESLint 和 husky 部分介绍。
通过 Demo 我们能看出,Prettier 确实很灵活,且自动化程度很高,接入项目也十分方便。
ESLint
下面来看一下以 ESLint 为代表的 Linter。Code Linting 表示基于静态分析代码原理,找出代码反模式的过程。多数编程语言都有 Linter,它们往往被集成在编译阶段,完成 Coding Linting 的任务。
对于 JavaScript 这种动态、宽松类型的语言来说,开发者更容易犯错。由于 JavaScript 不具备先天编译流程,往往会在运行时暴露错误,而 Linter,尤其最具代表性的 ESLint 的出现,允许开发者在执行前发现代码错误或不合理的写法。
ESLint 最重要的几点哲学思想:
- 所有规则都插件化
- 所有规则都可插拔(随时开关)
- 所有设计都透明化
- 使用 Espree 进行 JavaScript 解析
- 使用 AST 分析语法
想要顺利执行 ESLint,还需要安装应用规则插件。
那么如何声明并应用规则呢?在根目录中打开 .eslintrc 配置文件,我们在该文件中加入:
{"rules": {"semi": ["error", "always"],"quote": ["error", "double"]}}
semi、quote 就是 ESLint 规则的名称,其值对应的数组第一项可以为:off/0、warn/1、error/2,分别表示关闭规则、以 warning 形式打开规则、以 error 形式打开规则。
- off/0:关闭规则
- warn/1:以 warning 形式打开规则
- error/2:以 error 形式打开规则
同样我们还会在 .eslintrc 文件中发现:
"extends": "eslint:recommended"
这行表示 ESLint 默认的规则都将会被打开。当然,我们也可以选取其他规则集合,比较出名的有:
我们继续拆分 .eslintrc 文件,其实它主要由六个字段组成:
module.exports = {env: {},extends: {},plugins: {},parser: {},parserOptions: {},rules: {},}
- env:表示指定想启用的环境。
- extends:指定额外配置的选项,如 [‘airbnb’] 表示使用 Airbnb 的 Linting 规则。
- plugins:设置规则插件。
- parser:默认情况下 ESLint 使用 Espree 进行解析。
- parserOptions:如果将默认解析器更改,需要制定 parserOptions。
- rules:定义拓展并通过插件添加的所有规则。
注意,上文中 .eslintrc 文件我们采用了 .eslintrc.js 的 JavaScript 文件格式,此外还可以采用 .yaml、.json、yml 等格式。如果项目中含有多种配置文件格式,优先级顺序为:
- .eslintrc.js
- .eslintrc.yaml
- .eslintrc.yml
- .eslintrc.json
- .eslintrc
- package.json
最终,我们在 package.json 中可以添加 script:
"scripts": {"lint": "eslint --debug src/","lint:write": "eslint --debug src/ --fix"},
我们对上述 npm script 进行分析,如下:
- lint 这个命令将遍历所有文件,并在每个找到错误的文件中提供详细日志,但需要开发者手动打开这些文件并更正错误。
- lint:write 与 lint 命令类似,但这个命令可以自动纠正错误。
Linter VS Prettier
我们应该如何对比以 ESLint 为代表的 Linter 和 Prettier 呢,它们到底是什么关系?就像开篇提到的那样,它们解决不同的问题,定位不同,但是又可以相辅相成。
所有的 Linter 类似 ESLint,其规则都可以划分为两类。
- 格式化规则(Formatting Rules)
这类 “格式化规则” 典型的有 max-len、no-mixed-spaces-and-tabs、keyword-spacing、comma-style,它们 “限制一行的最大长度”“禁止使用空格和 Tab 混合缩进” 等代码格式方面的规范。事实上,即便开发者写出的代码违反了这类规则,如果在 Lint 阶段前,先经过 Prettier 处理,这些问题会在 Prettier 阶段被纠正,因此 Linter 不会抛出提醒,非常省心,这也是 Linter 和 Prettier 重叠的地方。
- 代码质量规则(Code Quality Rules)
这类 “代码质量规则” 类似 no-unused-vars、no-extra-bind、no-implicit-globals、prefer-promise-reject-errors,它们限制 “声明未使用变量”“不必要的函数绑定” 等代码写法规范。这个时候,Prettier 对这些规则无能为力,而这些规则对于代码质量和强健性至关重要,还是需要 Linter 来保障的。
如同 Prettier,ESLint 也可以集成到编辑器或者 Git pre-commit 阶段。前文已经演示过了 Prettier 搭配 husky,下面我们来介绍一下 husky 到底是什么。
husky 和 lint-staged
其实,husky 就是 Git 的一个钩子,在 Git 进行到某一时段时,可以交给开发者完成某些特定的操作。比如每次提交(commit 阶段)或者推送(push 阶段)代码时,就可以执行相关 npm 脚本。需要注意的是,在整个项目上运行 Lint 会很慢,我们一般只想对更改的文件进行检查,此时就需要使用到 lint-staged。比如如下代码:
"scripts": {"lint": "eslint --debug src/","lint:write": "eslint --debug src/ --fix","prettier": "prettier --write src/**/*.js"},"husky": {"hooks": {"pre-commit": "lint-staged"}},"lint-staged": {"*.(js|jsx)": ["npm run lint:write", "npm run prettier", "git add"]},
上述代码表示在 pre-commit 阶段对于 js 或者 jsx 后缀且修改的文件执行 ESLint 和 Prettier 操作,通过之后再进行 git add 添加到暂存区。
lucas-scripts 中的 Lint 配置最佳实践
结合上一讲内容,我们可以扩充 lucas-scripts 项目关于 Lint 的抽象设计。相关脚本:
const path = require('path')const spawn = require('cross-spawn')const yargsParser = require('yargs-parser')const {hasPkgProp, resolveBin, hasFile, fromRoot} = require('../utils')let args = process.argv.slice(2)const here = p => path.join(__dirname, p)const hereRelative = p => here(p).replace(process.cwd(), '.')const parsedArgs = yargsParser(args)const useBuiltinConfig =!args.includes('--config') &&!hasFile('.eslintrc') &&!hasFile('.eslintrc.js') &&!hasPkgProp('eslintConfig')const config = useBuiltinConfig? ['--config', hereRelative('../config/eslintrc.js')]: []const defaultExtensions = 'js,ts,tsx'const ext = args.includes('--ext') ? [] : ['--ext', defaultExtensions]const extensions = (parsedArgs.ext || defaultExtensions).split(',')const useBuiltinIgnore =!args.includes('--ignore-path') &&!hasFile('.eslintignore') &&!hasPkgProp('eslintIgnore')const ignore = useBuiltinIgnore? ['--ignore-path', hereRelative('../config/eslintignore')]: []const cache = args.includes('--no-cache')? []: ['--cache','--cache-location',fromRoot('node_modules/.cache/.eslintcache'),]const filesGiven = parsedArgs._.length > 0const filesToApply = filesGiven ? [] : ['.']if (filesGiven) {args = args.filter(a => !parsedArgs._.includes(a) || extensions.some(e => a.endsWith(e)),)}const result = spawn.sync(resolveBin('eslint'),[...config, ...ext, ...ignore, ...cache, ...args, ...filesToApply],{stdio: 'inherit'},)process.exit(result.status)
npm-script 的 eslintrc.js 就比较简单了,我们默认使用以下配置:
const {ifAnyDep} = require('../utils')module.exports = {extends: [require.resolve('XXXX'),ifAnyDep('react', require.resolve('XXX')),].filter(Boolean),rules: {},}
上述代码中的规则配置,我们可以采用自定义的 eslint config,也可以选用社区上流行的 config。
具体流程执行原理上一讲中已经梳理,我们不再展开。下面,我们从 AST 的层面,深入 Lint 原理,并根据其实现和扩展能力,开发更加灵活的工具集。
工具背后的技术原理和设计
我们挑选实现更为复杂精妙的 ESLint 来分析。你应该很清楚,ESLint 是基于静态语法分析(AST)进行工作的,AST 已经不是一个新鲜话题。ESLint 使用 Espree 来解析 JavaScript 语句,生成 AST。
有了完整的解析树,我们就可以基于解析树,对代码进行检测和修改。ESLint 的灵魂是每一条 rule,每条规则都是独立且插件化的,我们挑一个比较简单的 “禁止块级注释规则” 源码来分析:
module.exports = {meta: {docs: {description: '禁止块级注释',category: 'Stylistic Issues',recommended: true}},create (context) {const sourceCode = context.getSourceCode()return {Program () {const comments = sourceCode.getAllComments()const blockComments = comments.filter(({ type }) => type === 'Block')blockComments.length && context.report({message: 'No block comments'})}}}}
从中我们看出,一条规则就是一个 node 模块,它由 meta 和 create 组成。meta 包含了该条规则的文档描述,相对简单。而 create 接受一个 context 参数,返回一个对象,如下代码:
{meta: {docs: {description: '禁止块级注释',category: 'Stylistic Issues',recommended: true}},create (context) {return {}}}
从 context 对象上我们可以取得当前执行扫描到的代码,并通过选择器获取当前需要的内容。如上代码,我们获取代码的所有 comments(sourceCode.getAllComments()),如果 blockComments 长度大于 0,则 report No block comments 信息。了解了这些,相信你也能写出 no-alert、no-debugger 的规则内容。
虽然 ESLint 背后的技术内容比较复杂,但是基于 AST 技术,它已经给开发者提供了较为成熟的 APIs。写一条自己的规则并不是很难,只需要开发者找到相关的 AST 选择器。更多的选择器可以参考:Selectors - ESLint - Pluggable JavaScript linter,熟练掌握选择器,将是我们开发插件扩展的关键。
当然,更复杂的场景远不止这么简单,比如,多条规则是如何串联起来生效的?
多条规则串联生效
事实上,规则可以从多个源来定义,比如代码的注释当中,或者配置文件当中。
ESLint 首先收集到所有规则配置源,将所有规则归并之后,进行多重遍历:遍历由源码生成的 AST,将语法节点传入队列当中;之后遍历所有应用规则,采用事件发布订阅模式(类似 Webpack Tapable),为所有规则的选择器添加监听事件;在触发事件时执行,如果发现有问题,会将 report message 记录下来。最终记录下来的问题信息将会被输出。
请你再思考,我们的程序中免不了有各种条件语句、循环语句,因此代码的执行是非顺序的。相关规则比如:“检测定义但未使用变量”“switch-case 中避免执行多条 case 语句”,这些规则的实现,就涉及 ESLint 更高级的 Code Path Analysis 概念等。ESLint 将 Code Path 抽象为 5 个事件:
- onCodePathStart
- onCodePathEnd
- onCodePathSegmentStart
- onCodePathSegmentEnd
- onCodePathSegmentLoop
利用这 5 个事件,我们可以更加精确地控制检测范围和粒度。更多的 ESLint rule 实现,你可以翻看源码进行学习,总之根据这 5 种事件,我们可以监测非顺序性代码,其核心原理还是事件机制。
这种优秀的插件扩展机制对于设计一个库,尤其是设计一个规范工具来说,是非常值得借鉴的模式。事实上,Prettier 也会在新的版本中引入插件机制,目前已经在 Beta 版引入,感兴趣的读者可以尝鲜。
总结
这一讲我们深入工程化体系的重点细节自动化代码检查,并反过来使用 lucas-scripts 实现了一套智能的代码 Lint 脚本,建议你结合上一讲内容共同学习。
本讲内容总结如下:
在规范化的道路上,只有你想不到,没有你做不到。简单的规范化工具用起来非常清爽,但是背后的实现却蕴含了很深的设计与技术细节,值得我们深入学习。同时,作为前端工程师,我们应该从平时开发的痛点和效率瓶颈入手,敢于尝试,不断探索。保证团队开发的自动化程度,就能减少不必要的麻烦。
在工程化基建当中,除了项目管理和规范相对 “偏硬” 的强制规范手段;一些“软方向”,比如团队氛围、code review 等,也直接决定着团队的代码质量。进阶的工程师不仅需要在技术上成长,在团队建设上更需要主动交流。下一讲我们换一个方向,深入一个更具体的方案——前端 + 移动端离线包设计,请继续学习!

若有收获,就点个赞吧
0 人点赞
