前端基础建设与架构 - 前百度资深前端开发工程师 - 拉勾教育
这一讲,我们将对代码拆分和按需加载这一话题进行解析。
随着 Webpack 等构建工具的能力越来越强,开发者在构建阶段可以随心所欲打造项目流程,代码拆分和按需加载技术在业界曝光量也越来越高。事实上,代码拆分和按需加载的设计决定着工程化构建的结果,这将直接影响应用的性能表现,因为合理的加载时机和代码拆分能够使初始代码体积更小,页面加载更快。因此,如何合理设计代码拆分和按需加载,是对一个项目架构情况的直接考量。
下面我们从代码拆分和按需加载的场景入手,一同体会这一技术手段的必要性和业务价值。
代码拆分和按需加载场景
我们来看一个案例。如下图所示场景:点击左图播放按钮后,页面出现视频列表浮层(如右侧图所示,类似单页应用,视频列表仍为同一页面)。视频列表浮层包含了滚动处理、视频播放等多项复杂逻辑,因此这个浮层对应的脚本在页面初始化时,不需要被加载。那么在工程上,我们需要对视频浮层脚本单独进行拆分,和初始化脚本进行分离。当用户点击浮层触发按钮后,执行某一单独部分脚本的请求。

这其实是一个我接手并重构过的真实线上案例,通过后期对页面交互的统计数据分析发现,用户点击触发视频浮层出现按钮的概率只有 10% 左右。也就是说,大部分用户(90%)并不会看到这一浮层,也就不需要对相关脚本进行加载执行,因此延迟按需加载设计是有统计数据支持的。现在你已经了解了这个场景,下面我们从技术环节详细展开。
代码拆分和按需技术实现
按需加载和按需打包区分
从技术角度介绍按需加载概念前,我们需要先和另外一个概念:按需打包,进行区分。事实上,当前社区对于按需加载和按需打包并没有一个准确的命名上的划分约定。因此从两者命名上,难以区分其实际含义。
其实,按需加载表示代码模块在交互需要时,动态引入;而按需打包针对第三方依赖库,及业务模块,只打包真正在运行时可能会需要的代码。
我们不妨先说明按需打包的概念和实施方法,目前按需打包一般通过两种方式进行:
- 使用 ES Module 支持的 Tree Shaking 方案,在使用构建工具打包时,完成按需打包;
- 使用以
babel-plugin-import为主的 Babel 插件,实现自动按需打包 。
Tree Shaking 实现按需打包
我们来看一个场景,假设业务中使用 antd 的 Button 组件:
import { Button } from 'antd';
这样的引用,会使得最终打包的代码中包含所有 antd 导出来的内容。假设应用中并没有使用 antd 提供的 TimePicker 组件,那么对于打包结果来说,无疑增加了代码体积。在这种情况下,如果组件库提供了 ES Module 版本,并开启了 Tree Shaking,我们就可以通过 “摇树” 特性,将不会被使用的代码在构建阶段移除。
Webpack 可以在 package.json 中设置sideEffects: false。我们在 antd 源码当中可以找到(相关 chore commit):
"sideEffects": ["dist/*","es/**/style/*","lib/**/style/*","*.less"],
指定副作用模块——这是一种值得推荐的开发习惯,建议你注意 Tree Shaking 的使用,最好实际观察一下打包结果。
学习编写 Babel 插件,实现按需打包
如果第三方库不支持 Tree Shaking,我们依然可以通过 Babel 插件,改变业务代码中对模块的引用路径来实现按需打包。
比如 babel-plugin-import 这个插件,它是 antd 团队推出的一个 Babel 插件,我们通过一个例子来理解它的原理,比如:
import {Button as Btn,Input,TimePicker,ConfigProvider,Haaaa} from 'antd'
这样的代码就可以被编译为:
import _ConfigProvider from "antd/lib/config-provider";import _Button from "antd/lib/button";import _Input from "antd/lib/input";import _TimePicker from "antd/lib/time-picker";
编写一个类似的 Babel 插件也不是一件难事,Babel 插件核心依赖于对 AST 的解析和操作。它本质上就是一个函数,在 Babel 对 AST 语法树进行转换的过程中介入,通过相应的操作,最终让生成的结果发生改变。
Babel 已经内置了几个核心分析、操作 AST 的工具集,Babel 插件通过观察者 + 访问者模式,对 AST 节点统一遍历,因此具备了良好的扩展性和灵活性。比如这段代码:
import {Button as Btn, Input} from 'antd'
这样的代码,经过 Babel AST 分析后,得到结构:
{"type": "ImportDeclaration","specifiers": [{"type": "ImportSpecifier","imported": {"type": "Identifier","loc": {"identifierName": "Button"},"name": "Button"},"importKind": null,"local": {"type": "Identifier","loc": {"identifierName": "Btn"},"name": "Btn"}},{"type": "ImportSpecifier","imported": {"type": "Identifier","loc": {"identifierName": "Input"},"name": "Input"},"importKind": null,"local": {"type": "Identifier","start": 23,"end": 28,"loc": {"identifierName": "Input"},"name": "Input"}}],"importKind": "value","source": {"type": "StringLiteral","value": "antd"}}
通过上述结构,我们很容易实现遍历 specifiers 属性,至于更改最后代码的 import 部分,你可以参考 babel-plugin-import 相关处理逻辑。
首先通过buildExpressionHandler方法对 import 路径进行改写:
buildExpressionHandler(node, props, path, state) {const file = (path && path.hub && path.hub.file) || (state && state.file);const { types } = this;const pluginState = this.getPluginState(state);props.forEach(prop => {if (!types.isIdentifier(node[prop])) return;if (pluginState.specified[node[prop].name] &&types.isImportSpecifier(path.scope.getBinding(node[prop].name).path)) {node[prop] = this.importMethod(pluginState.specified[node[prop].name], file, pluginState);}});}
buildExpressionHandler方法依赖importMethod方法:
importMethod(methodName, file, pluginState) {if (!pluginState.selectedMethods[methodName]) {const { style, libraryDirectory } = this;const transformedMethodName = this.camel2UnderlineComponentName? transCamel(methodName, '_'): this.camel2DashComponentName? transCamel(methodName, '-'): methodName;const path = winPath(this.customName? this.customName(transformedMethodName, file): join(this.libraryName, libraryDirectory, transformedMethodName, this.fileName),);pluginState.selectedMethods[methodName] = this.transformToDefaultImport? addDefault(file.path, path, { nameHint: methodName }): addNamed(file.path, methodName, path);if (this.customStyleName) {const stylePath = winPath(this.customStyleName(transformedMethodName));addSideEffect(file.path, `${stylePath}`);} else if (this.styleLibraryDirectory) {const stylePath = winPath(join(this.libraryName, this.styleLibraryDirectory, transformedMethodName, this.fileName),);addSideEffect(file.path, `${stylePath}`);} else if (style === true) {addSideEffect(file.path, `${path}/style`);} else if (style === 'css') {addSideEffect(file.path, `${path}/style/css`);} else if (typeof style === 'function') {const stylePath = style(path, file);if (stylePath) {addSideEffect(file.path, stylePath);}}}return { ...pluginState.selectedMethods[methodName] };}
importMethod方法调用了@babel/helper-module-imports中的addSideEffect方法执行路径的转换操作。addSideEffect方法在源码中通过实例化一个 Import Injector,并调用实例方法完成了 AST 转换,具体源码可以参考:babel-helper-module-imports。
现在我们已经看完了按需加载打包内容,接下来,我们看看动态导入以及按需加载这个重要概念。
“重新认识” dynamic import(动态导入)
ES module 无疑在工程化方面给前端插上了一双起飞的翅膀。溯源历史我们发现:早期 import 是完全静态化的,而如今 dynamic import 的提案早已横空出世,目前已经进入了 stage 4 阶段。dynamic import 简单翻译为动态导入,从名字上看,我们就能知晓这个新特性和按需加载密不可分。但在深入讲解 dynamic import 之前,我想先从静态导入说起,以帮助你全方位地理解。
静态导入的性能优劣
标准用法的 import 属于静态导入,它只支持一个字符串类型的 module specifier(模块路径声明),这样的特性会使所有被 import 的模块在加载时就被编译。从某些角度看,这种做法对于绝大多数场景来说性能是友好的,因为这意味着对工程代码的静态分析成为可能,进而使得类似 tree-shaking 的技术有了应用空间。
但是对于一些特殊场景,静态导入也可能成为性能的短板,比如,当我们需要:
- 按需加载一个模块;
- 按运行事件选定一个模块。
此时,dynamic import 就变得尤为重要。比如在浏览器侧,根据用户的系统语言选择加载不同的语言模块,根据用户的操作去加载不同的内容逻辑。
MDN 文档中给出了 dynamic import 更具体的使用场景:
- 静态导入的模块很明显降低了代码的加载速度且被使用的可能性很低,或者并不需要马上使用它;
- 静态导入的模块很明显占用了大量系统内存且被使用的可能性很低;
- 被导入的模块在加载时并不存在,需要异步获取;
- 导入模块的说明符,需要动态构建(静态导入只能使用静态说明符);
- 被导入的模块有副作用(可以理解为模块中会直接运行的代码),这些副作用只有在触发某些条件时才被需要。
深入理解 dynamic import(动态导入)
这里我们不再赘述 dynamic import 的标准用法,你可以从官方规范和 tc39 proposal 中找到最全面和原始的内容。
除了基础用法,我想从语言层面强调一个 Function-like 的概念。我们先看这样一段代码:
// html 部分<nav><a href="" data-script-path="books">Books</a><a href="" data-script-path="movies">Movies</a><a href="" data-script-path="video-games">Video Games</a></nav><div id="content"></div>// script 部分<script>// 获取 elementconst contentEle = document.querySelector('#content');const links = document.querySelectorAll('nav > a');// 遍历绑定点击逻辑for (const link of links) {link.addEventListener('click', async (event) => {event.preventDefault();try {const asyncScript = await import(`/${link.dataset.scriptPath}.js`);// 异步加载脚本asyncScript.loadContentTo(contentEle);} catch (error) {contentEle.textContent = `We got error: ${error.message}`;}});}</script>
点击页面当中的 a 标签后,会动态加载一个模块,并调用模块定义的 loadContentTo 方法完成页面内容的填充。
表面上看,await import() 的用法使得 import 像一个函数,该函数通过 () 操作符调用并返回一个 Promise。事实上,dynamic import 只是一个 function like 的语法形式。在 ES class 特性中,super() 与 dynamic import 类似,也是一个 function like 语法形式。所以它和函数还是有着本质的区别,比如:
- dynamic import 并非继承自 Function.prototype,因此不能使用 Function 构造函数原型上的方法 impoort.call(null,
${path}),调用它是不合法的; - dynamic import 并非继承自 Object.prototype,因此不能使用 Object 构造函数原型上的方法。
虽然 dynamic import 并不是一个真正意义上的函数,但我们可以通过实现一个 dynamicImport 函数模式来实现 dynamic import,进一步加深对其语法特性的理解。
实现一个 dynamic import(动态导入)
dynamicImport 函数实现如下:
const importModule = url => {return new Promise((resolve, reject) => {const script = document.createElement("script");const tempGlobal = "__tempModuleLoadingVariable" + Math.random().toString(32).substring(2);script.type = "module";script.textContent = `import * as m from "${url}"; window.${tempGlobal} = m;`;script.onload = () => {resolve(window[tempGlobal]);delete window[tempGlobal];script.remove();};script.onerror = () => {reject(new Error("Failed to load module script with URL " + url));delete window[tempGlobal];script.remove();};document.documentElement.appendChild(script);});}
这里,我们通过动态插入一个 script 标签实现对目标 script url 的加载,并通过将模块导出内容赋值给 window 对象。我们使用__tempModuleLoadingVariable" + Math.random().toString(32).substring(2) key保证模块导出对象的命名不会出现冲突。
至此,我们对 dynamic import 的分析告一段落。总之,代码拆分和按需加载并不完全是工程化的实施,同时也要求对语言深刻掌握。
Webpack 赋能代码拆分和按需加载
通过前面的学习,我们了解了代码拆分和按需加载,学习了动态导入这一特性。接下来,我想请你思考,如何在代码中安全地使用动态导入而不用去过多关心浏览器的兼容情况,如何在工程环境中实现代码拆分和按需加载呢?
以最常见、最典型的前端构建工具——Webpack 为例,我们来分析如何在 Webpack 环境下支持代码拆分和按需加载。
总的来说,Webpack 提供了三种相关能力:
- 通过入口配置手动分割代码;
- 动态导入支持;
- 通过 splitChunk 插件提取公共代码(公共代码分割)。
其中第一种是通过配置 Entry 来由开发者手动进行代码项目打包,与我们这节内容主题并不相关,就不展开讲解了。下面我们从动态导入和 splitChunk 插件进行详细解析。
Webpack 对 dynamic import 能力支持
事实上,在 Webpack 早期版本中,提供了 require.ensure() 能力。请注意这是 Webpack 特有的实现:require.ensure() 能够将其参数对应的文件拆分到一个单独的 bundle 中,此 bundle 会被异步加载。
目前 require.ensure() 已经被符合 ES 规范的 dynamic import 取代。调用 import(),被请求的模块和它引用的所有子模块,会分离到一个单独的 chunk 中。值得学习的是,Webpack 对于 import() 的支持和处理非常 “巧妙”,我们知道 ES 中关于 dynamic import 的规范,只接受一个参数,表示模块的路径:
import(`${path}`) -> Promise
但是 Webpack 是一个构建工具,Webpack 中对于 import() 的处理,可以通过注释接收一些特殊的参数,无须破坏 ES 对于 dynamic import 规定。比如:
Webpack 在构建时,可以读取到 import 参数,即便是参数内的注释部分,Webpack 也可以获取并处理。如上述代码,webpackChunkName: "chunk-name"表示自定义新 chunk 名称;webpackMode: "lazy"表示每个 import() 导入的模块,会生成一个可延迟加载(lazy-loadable) chunk。此外,webpackMode 的取值还可以是 lazy-once、eager、weak,具体含义可参考:Webpack import()。
你可能很好奇:Webpack 在编译构建时,会如何处理代码中的 dynamic import 呢?下面,我们一探究竟。
index.js 文件:
import('./module').then((data) => {console.log(data)});
module.js 文件:
const module = {value: 'moduleValue'}export default module
我们配置入口文件为 index.js,输出文件为 bundle.js,简单的 Webpack 配置信息(webpack@4.44.2):
const path = require('path');module.exports = {mode: 'development',entry: './index.js',output: {filename: 'bundle.js',path: path.resolve(__dirname, 'dist'),},};
运行构建命令后,得到两个文件:
- 0.bundle.js
- bundle.js
bundle.js 中对 index.js dynamic import 编译结果为:
({"./index.js":!*** ./index.js ***!\******************/(function(module, exports, __webpack_require__) {eval("__webpack_require__.e(/*! import() */ 0).then(__webpack_require__.bind(null, /*! ./module */ \"./module.js\")).then((data) => {\n console.log(data)\n});\n\n//# sourceURL=webpack:///./index.js?");})});
由此可知,Webpack 对于业务中写到的 dynamic import 代码,会转换成了 Webpack 自己自定义的 webpack_require.e 函数,这个函数返回了一个 promise 数组,最终模拟出了动态导入的效果,webpack_require.e 源码如下:
__webpack_require__.e = function requireEnsure(chunkId) {var promises = [];var installedChunkData = installedChunks[chunkId];if(installedChunkData !== 0) {if(installedChunkData) {promises.push(installedChunkData[2]);} else {var promise = new Promise(function(resolve, reject) {installedChunkData = installedChunks[chunkId] = [resolve, reject];});promises.push(installedChunkData[2] = promise);var script = document.createElement('script');var onScriptComplete;script.charset = 'utf-8';script.timeout = 120;if (__webpack_require__.nc) {script.setAttribute("nonce", __webpack_require__.nc);}script.src = jsonpScriptSrc(chunkId);var error = new Error();onScriptComplete = function (event) {script.onerror = script.onload = null;clearTimeout(timeout);var chunk = installedChunks[chunkId];if(chunk !== 0) {if(chunk) {var errorType = event && (event.type === 'load' ? 'missing' : event.type);var realSrc = event && event.target && event.target.src;error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')';error.name = 'ChunkLoadError';error.type = errorType;error.request = realSrc;chunk[1](error);}installedChunks[chunkId] = undefined;}};var timeout = setTimeout(function(){onScriptComplete({ type: 'timeout', target: script });}, 120000);script.onerror = script.onload = onScriptComplete;document.head.appendChild(script);}}return Promise.all(promises);};
代码已经非常直观,webpack_require.e 主要做了如下内容:
- 定义一个 promise 数组 promises,最终以 Promise.all(promises) 形式返回;
- 通过 installedChunkData 变量判断当前模块是否已经被加载,如果已经加载过,将模块内容 push 到 promises 数组中;
- 如果当前模块没有被加载过,则先定义一个 promise,然后创建一个 script 标签,加载模块内容,并定义此 script 的 onload 和 onerror 回调;
- 最终对新增 script 标签对应的 promise (resolve/reject)处理定义在 webpackJsonpCallback 函数中。
function webpackJsonpCallback(data) {var chunkIds = data[0];var moreModules = data[1];var moduleId, chunkId, i = 0, resolves = [];for(;i < chunkIds.length; i++) {chunkId = chunkIds[i];if(Object.prototype.hasOwnProperty.call(installedChunks, chunkId) && installedChunks[chunkId]) {resolves.push(installedChunks[chunkId][0]);}installedChunks[chunkId] = 0;}for(moduleId in moreModules) {if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {modules[moduleId] = moreModules[moduleId];}}if(parentJsonpFunction) parentJsonpFunction(data);while(resolves.length) {resolves.shift()();}};
完整的源码内容我们不再一一粘贴,你可以参考下图的整个处理流程:
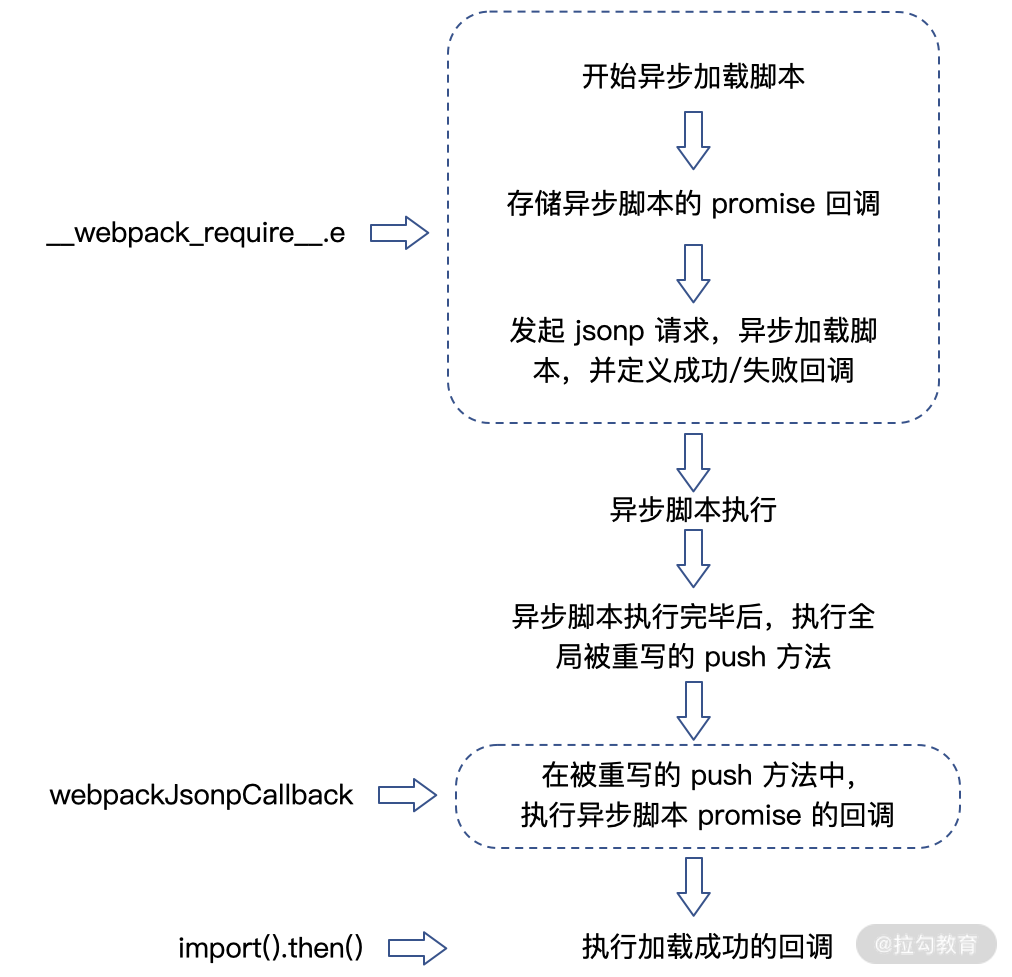
webpack_require.e 处理流程图
Webpack 中 splitChunk 插件和代码分割
你可能对 Webpack 4.0 版本推出的 splitChunk 插件并不陌生。这里需要注意的是,代码分割区别于动态加载,它们本质上是两个概念。前文介绍到的 dynamic import(动态导入)技术本质上一种是懒加载——按需加载,即只有在需要的时候,才加载代码。而以 splitChunk 插件为代表的代码分割,是一种代码拆包技术,与代码合并打包是一个相逆的过程。
代码分割的核心意义在于避免重复打包以及提升缓存利用率,进而提升访问速度。比如,我们将不常变化的第三方依赖库进行代码拆分,方便对第三方依赖库缓存,同时抽离公共逻辑,减少单个文件的 size 大小。
了解了代码分割的概念,那么就很好理解 Webpack splitChunk 插件满足下述条件时,自动进行代码分割:
- 可以被共享的(即重复被引用的)模块或者 node_modules 中的模块;
- 在压缩前体积大于 30KB 的模块;
- 在按需加载模块时,并行加载的模块不得超过 5 个;
- 在页面初始化加载时,并行加载的模块不得超过 3 个。
当然,上述配置数据是完全可以由开发者掌握主动权,并根据项目实际情况进行调整的。更多内容可以参考:split-chunks-plugin。不过需要注意的是,关于 splitChunk 插件的默认参数是 Webpack 团队所设定的通用性优化手段,是经过 “千挑万选” 确定的,因此适用于多数开发场景。如果在没有实践测量的情况下,不建议开发者手动优化这些参数。
另外, Webpack splitChunk 插件也支持上文提到的 “按需加载”,即可以和 dynamic import 搭配使用。比如,page1 和 page2 页面里动态引入 async.js,即 page1.js 和 page2.js 都有这样的逻辑:
import("./async").then(common => {console.log(common);})
在进行构建后,async.js 会被单独打包。如果进一步在 async.js 文件中引入 module.js 模块,即 async.js 中的代码如下所示:
import("./module.js").then(module => {console.log(module);})
依赖关系图如下图所示:
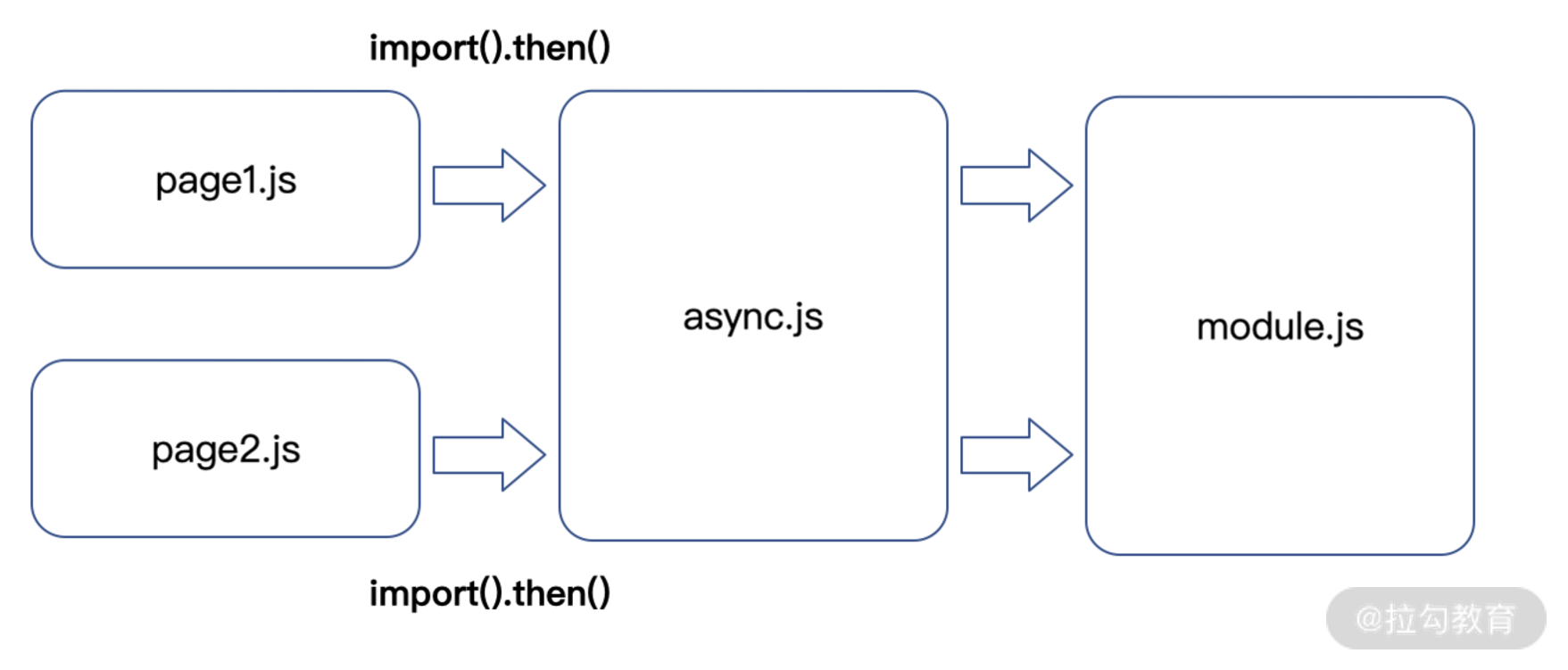
三重依赖关系图
最终打包结果会按需动态引入 async.js,同时 module.js 也被成功单独拆分出来。
总结
这一讲我们就代码拆分和按需加载这一话题进行了分析:
- 首先从代码拆分和按需加载的业务场景入手,分析了这一技术手段的必要性和业务价值;
- 接着,我们从 ES 规范入手,深入解读了 dynamic import 动态加载这一核心语言特性,同时从 Tree Shaking 和编写 Babel 插件的角度,在较深层的语法和工程理念上对比了按需打包这一话题;
- 最后,我们通过对 Webpack 能力的探究,剖析了如何在工程中实现代码拆分和按需加载。
在实际工作中,我希望你能利用本节内容,并结合项目实际情况,排查代码拆分和按需加载是否合理;如果有不合理之处,可以动手实践、实验,进行论证。
本节内容既有理论内容,又有工程实践,只要你有 “庖丁解牛” 的决心,相信很快就有 “入木三分” 的理解。

若有收获,就点个赞吧
0 人点赞
