Node.js 应用开发实战 - 高级前端开发工程师 - 拉勾教育
在开始本讲之前,我们先了解一个特点,在前端因为某些用户的特殊性,导致的逻辑 Bug 会造成这个用户服务异常,但是在服务端如果没有做好异常保护,因为某个用户的特殊操作可能会导致整个进程退出,从而无法提供服务,因此如何做好监控和进程安全保护就显得尤为重要。
本讲我将介绍在 Node.js 代码层面应该如何降低异常出现的概率,其次会介绍当出现现网问题时,如何及时发现并通知相应的开发去处理。
Node.js 进程安全
这里我们主要讲解为什么 Node.js 的进程安全和健康状况很重要。
进程安全很重要
这里举一个例子,想象一下我们家庭电网的安全保护策略,一般情况下家庭都会有短路跳闸设施,其次插座或者电器也设有短路保护功能。
如果电器没有安全保护措施,就会直接导致家庭电网跳闸整体不可用,但是由于有了跳闸保护,至少我们可以重启,从而服务正常,但是这期间一家人由于一个人的原因,导致了比如说弟弟无法继续看书了、爸爸无法继续洗热水澡了、妈妈无法继续做饭了。
再说 Node.js,由于一个用户的异常访问或者数据异常,加上没有做好异常处理和安全保护,直接导致了整个 Node.js 服务重启了,从而中断了所有人的请求,用户体验非常差。
接下来我们再往上升级,如果家庭电网没有跳闸短路保护措施,将直接导致上一层电网异常重启,从而影响到其他居民,这样影响面又更大了,从而导致的问题也更严重了。
这就是和 Node.js 一样的原理,因此我们要尽可能地在最小处进行安全保护,也就是我们所说的在每个插电设备上尽量装有短路保护设备一样,这样就最小地影响用户,比如这个用户的异常数据只影响了该用户,而不会因为这个用户影响到整个服务的用户。
哪些场景会导致 Node.js 异常?
- 由于 Node.js 使用的是 JavaScript,而JavaScript 是一个弱类型语言,因此在现网经常会引发一些由代码逻辑的异常导致的进程异常退出。
- 其次在 Node.js 中也经常会因为内存的使用不当,导致内存泄漏,当在 64 位系统中达到 1.4 G(32 位系统 0.7 G)时,Node.js 就会异常崩溃。
- 再而由于Node.js 的 I/O 较多也较为频繁,当启用较多 I/O 句柄,但是没有及时释放,同样会引发进程问题。
这些都会导致服务器异常退出,就没办法正常提供服务了,从而引发现网问题。
接下来我们就从代码逻辑和服务器异常两个方面来介绍哪些场景会导致这些问题,并且我们应该如何去杜绝这类问题,其次还将演示一个搭建 Node.js 性能告警平台,来解决告警通知机制。
代码逻辑异常汇总
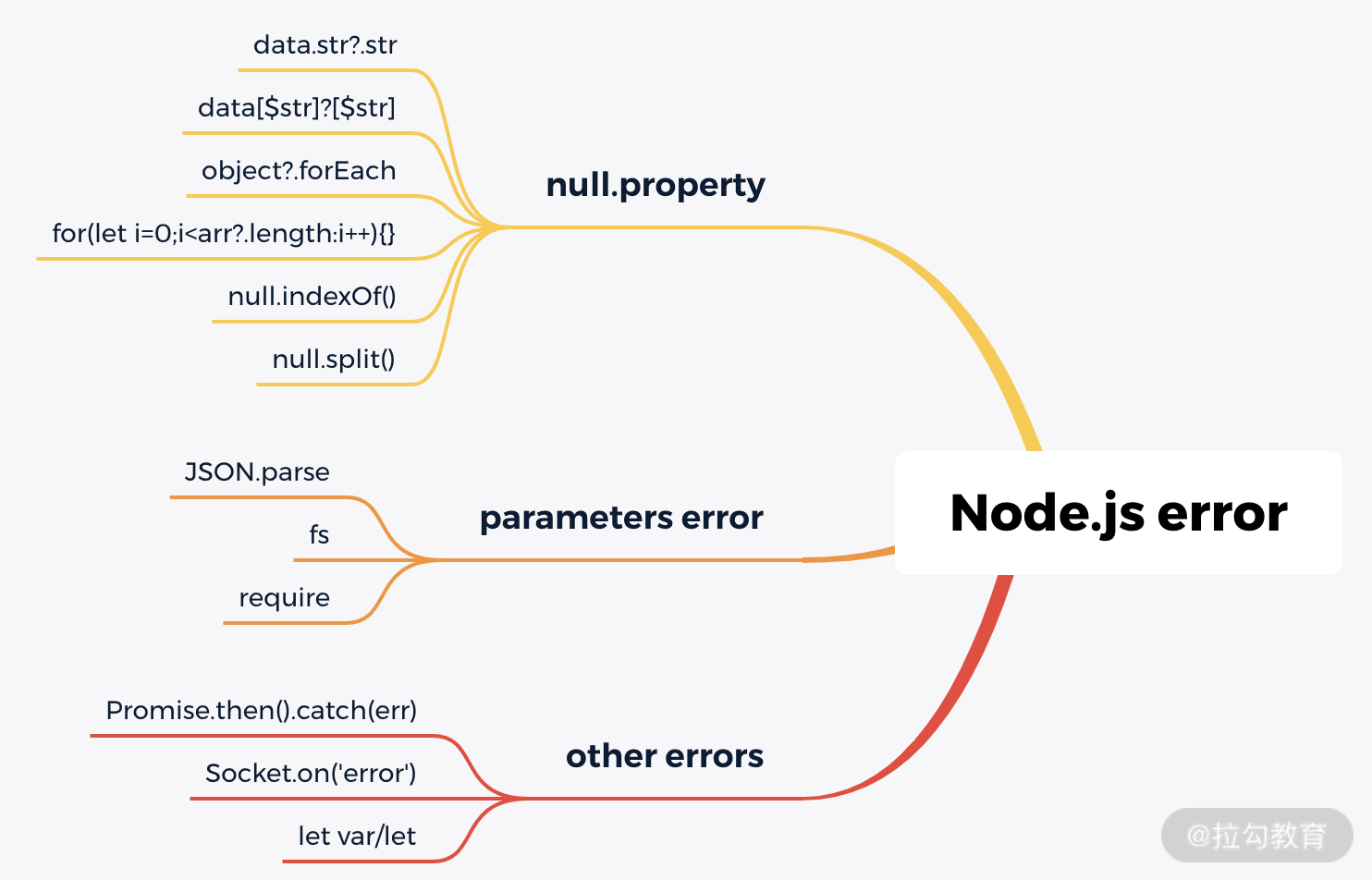
图 1 Node.js 异常问题
以上是一个异常问题的部分汇总,前端同学都应该掌握这些基本问题的解决方案,不过我们也来详细地看看每个问题出现的场景。
null.property
由于 JavaScript 是一个弱类型语言,因此如果对数据没有严格的判断就进行逻辑处理的话,会导致代码服务异常退出,从而影响用户体验。这里我们统一看 null.property 这种问题。
首先第一种就是多层数据嵌套时 (data.str?.str),需要逐层地进行数据判断,如下代码所示:
const Controller = require('../core/controller');class Error extends Controller {obj() {let data = {'userinfo' : {'nick' : 'node','name' : 'nodejs','age' : 10}};let nick = data.userinfo.nick;data.userinfo = null;let name = data.userinfo.name;return this.resApi(true, 'good', {nick, name});}}module.exports = Error;
你可以看到由于 userinfo 是一个 null,使用 null.name 是一定会报错的,而这个报错就会直接导致进程退出,在我们源码的框架中由于做了保护,是不会退出,而是给出一个如下的提示信息:
TypeError: Cannot read property 'name' of nullat Error.obj (/Users/XXX/Desktop/专栏技术/nodejs/nodejs-column/10/src/controller/error.js:18:34)
data.str?.str 和 data[str] 是类似的,但是data[
str] 这种问题在现网出现会更多,由于 $str 是一个变量,因此这个变量都有可能为 null,如下代码所示:
arrObj() {let data = {'userinfo' : {'nick' : 'node','name' : 'nodejs','lastName' : 'js','age' : 10},'js-nodejs' : {'Chinese' : '90','English' : '80','Mathematics' : '99'}};let lastName = data.userinfo.lastName;let name = data.userinfo.name;let fullName = `${lastName} ${name}`;let chineseFraction = data[fullName]['Chinese'];return this.resApi(true, 'good', {chineseFraction});}
以上问题在实际开发过程中更常见,由于 fullName 是一个变量,而变量往往是不同的值,因此出现问题的概率性更高。
避免上面两个问题的方式也非常简单,就是对数据进行一些必要的检查就可以了,下面就是修复后的逻辑:
let nick = data.userinfo.nick;data.userinfo = null;if(!data || !data.userinfo){return this.resApi(true, 'data error');}let name = data.userinfo.name;
主要是对每一层数据都进行校验,从 data 到 data.userinfo,而如果有四层,那么就需要前三层逐层去判断,代码可读性以及后期可维护性都比较低。
这样会发现一个问题,当数据结构非常复杂时,你的判断逻辑也会非常复杂,从而影响了开发效率,为了解决这个问题我们可以使用 lodash 这个库的 get 方法,代码修改如下:
let lastName = data.userinfo.lastName;let name = data.userinfo.name;let fullName = `${lastName} ${name}`;let chineseFraction = _.get(data, `${fullName}.Chinese`, 0);
在上面代码中的第 5 行,就简化了这部分判断逻辑,可以直接去获取属性,如果未获取到则设置默认 0 这个值,避免异常情况。
这样以后在系统层面就不会报错了,建议后续我们都使用这种方法来尽量避免以上的异常问题。
object?.forEach和for(let i=0;i<arr?.length:i++){} 这类问题和上面基本相似。不过这里是类型的判断,应用这些方法之前都需要进行类型的检测,不然也会引发现网异常,例如下面这种处理方式才是正确的。
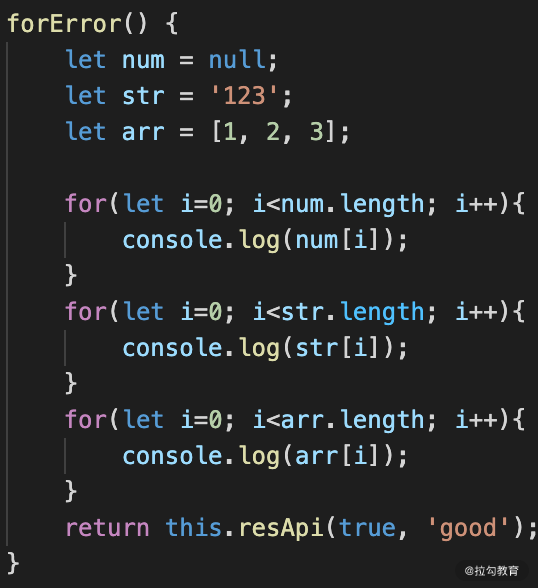
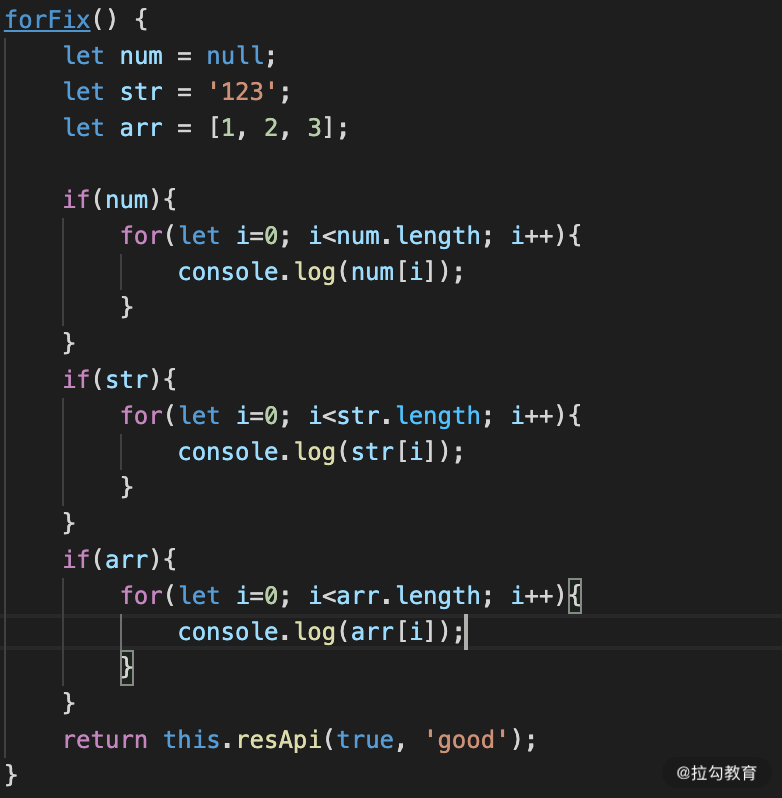
图 2 for 类型检测方法
我们对比下左右两边的逻辑,只需要判断是否为 null 就行了,因为我们需要使用数组的 length 属性,如果是一个 null.length 则会引发报错。
parameters error
接下来我们看下内部参数导致的一些问题,主要来看下常用的JSON.parse。
关于 JSON.parse 很多时候我们都比较自然地将其他接口或者第三方的数据拿来解析,但是这里往往会忽略其非 JSON 字符串的问题,比如下面这段代码就会引发异常:
jsonParse() {let str = 'nodejs';let obj = JSON.parse(str);return this.resApi(true, 'good', obj);}
为了解决这个问题,我们需要进行try catch 异常判断,如下代码所示:
jsonParse() {let str = 'nodejs';let obj = {};try {obj = JSON.parse(str);} catch (err) {console.log(err);}return this.resApi(true, 'good', obj);}
在我们框架中也存在一个问题,就是require的时候未进行异常判断,这部分你可以去第 09 讲源码中查看,并与本讲的代码进行对比,看看哪部份进行了修改。
其次 Node.js 的 fs 这个模块应用是非常多的,在应用 fs 的方法时,最好是使用 try catch 进行异常处理,因为很多时候可能存在权限不足或者文件不存在等问题。
other errors
JavaScript 也存在一些语法问题,由于 Node.js 是运行时报错,因此语法问题也只会在运行期间被发现,比如我们常发现的同变量重新申明的问题,特别是 let 和 var 声明同一个变量。
当前 Node.js 的 Promise 应用越来越广泛了,因此对于 Promise 的 catch 也应该多进行重视,对于每个 Promise 都应该要处理其异常 catch 逻辑,不然系统会提示 warning 信息。
还有一些常见的长连接的服务,比如 Socket、Redis、Memcache 等等,我们需要在连接异常时进行处理,如果没有处理同样会导致异常,比如 Socket 提供了 Socket.on(‘error’) 的监听。
还有其他的常见问题,希望各位同学在下面补充,我们一起来完善这份报错指引。
常见服务异常解析
服务器异常在 Node.js 中最常见的问题主要是内存泄漏、句柄泄漏以及网络模块调用。
接下来我们看看一些更深层次的关于 Node.js 的问题,我们先来回顾下在《08 | 优化设计:在 I/O 方面应该注意哪些要点?》所介绍的高性能日志模块的设计:
- 设置最大临时缓存数,超出则不使用缓存;
- 设置最大缓存句柄数,超出则不使用缓存;
- 定时清理当前的临时缓存和句柄缓存。
这三个设计的目的主要是为了避免内存泄漏、句柄泄漏问题。可以思考下,如果不进行定时清理或者上限限制,随着时间的增长,其中文件句柄会越来越多,其次在并发较高时,临时缓存的日志内容可能超出 1.4 G,从而引发重启。
具体实际开发中还有哪些场景我们也来详细分析下。
全局变量
一般情况下不建议使用全局变量,因为全局变量是最容易引发内存泄漏问题的,举个简单的例子,比如我们需要将用户的 session 保存在一个全局变量中,随着用户越来越多,这个 session 变量保存的数据也会越来越大,而且没有清理的规则,即使有清理规则,清理时间的长短影响用户体验,其次也影响内存的大小。
包括我们上面所说的日志模块就是一个全局变量,这个全局变量必须要有一定的上限和清理规则才能保证服务的安全。
单例模块中的变量
要注意一个点,有些模块我们使用单例的模式,就是在每次 require 后都返回这个对象,这种情况也比较容易引发内存泄漏的问题。
因为单例模式会引发每个用户访问的数据的叠加,比如下面这个模块的代码:
let singleton;const userList = [];class Singleton {add(uid) {userList.push(uid);}getLength() {return userList.length;}}module.exports = () => {if(singleton){return singleton;}singleton = new Singleton();return singleton;}
以上代码就是一个单例模式,其中会无限地往 userList push 数据,每调用一次 add 插入一条数据,这样会导致内存泄漏的问题,我们在 GitHub 源码的 error.js 中的 controller 有一个 singletonTest 方法,你会发现每调用一次数组长度就 +1,并且永远不会减少,除非重启。
对于这种单例的代码,我们要严格地进行 CR,因为这种问题真的很容易被忽视。
打开文件后,未主动关闭
这个是最容易理解的,一般打开文件句柄后,我们都应该主动关闭,如果未主动关闭,就会导致文件句柄越来越多,从而引发句柄泄漏问题。
在 Node.js 里 fs 的模块中都提供了打开文件句柄关闭的方法,比如 fs.open 提供了 fs.close 的方法,其次比如 fs.createWriteStream 提供了 fileStream.end 的方法。
网络句柄
网络句柄超出的情况一般还好,因为目标服务器会主动拒绝了你的请求,但是作为调用方,应该也要复用句柄,主动避免这类问题。其次还要注意连接超时控制,特别是在使用 Node.js 第三方库 request 以及 Socket 模块时。
监控告警介绍
图 3 是一个最简单的层级结构图,具体每个层级设计其实是非常复杂的。
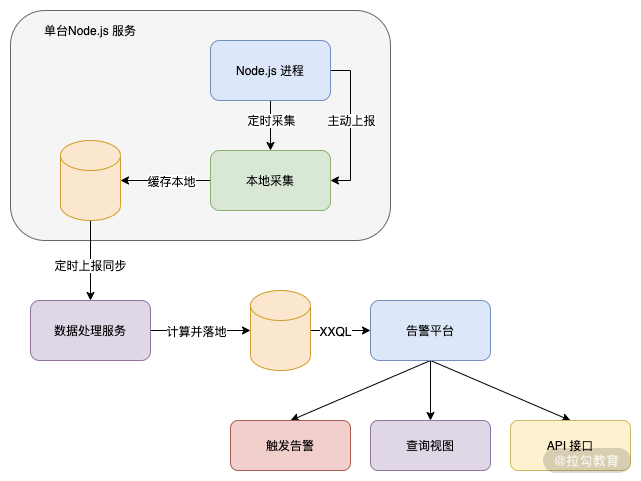
图 3 监控告警平台简单流程图
我们可以看到在 Node.js 服务器中,会包含两部分:
- 自动定时采集进程的指标数据;
- 接口被调用或者访问后主动上报的信息。
以上的两部分信息都会异步地发送给本地一个采集服务,落地到本地临时缓存中,然后定时地将本地临时缓存的上报信息发送给监控数据处理服务。
监控数据处理经过一系列的复杂计算,按照一定的数据要求落入监控平台的数据存储中,告警平台则使用特定 QL 语法查询数据库,主要服务于三种类型:
- 触发告警,根据告警平台的设置,当数据落入后判断是否满足告警机制,满足则调用告警模块触发告警;
- 查询视图,这部分就是一个前端可交互的界面,用户可以在这个平台查询监控信息;
- API 接口,有些情况需要针对告警进行一些研发操作,因此也支持 API 来查询监控告警信息。
接下来我们再来看看 Node.js 到底有哪些监控告警平台,以及监控的指标会有哪些。
平台介绍
在系统监控告警方面,Node.js 的 PM2 提供了付费服务,你可以直接用 PM2 来构建一个专门的监控告警机制,其中覆盖的进程管理功能也是比较齐全的。
不过还有另外一个方式就是自己构建一套开源免费的 prometheus 服务,如果是公司级别应用的话,可以参考 prometheus 官网自己搭建一套这种服务,其对 Node.js 的支持也是非常到位的,扩展请参考GitHub prom-client 库。
而在业务告警方面你可以直接复用当前后台侧的业务告警系统,或者prometheus也是可以的,又或者目前常用的一套组合系统Grafana(主要是监控系统界面操作平台)+InfluxDB(数据存储)+telegraf(数据采集) 也可以。
以上工具,具体如何安装、配置、使用,你可以去官网按照指引进行即可,我们接下来看下到底会监控哪些指标以及各个指标的含义。
监控指标
在进程监控告警层面,我们要了解到底应该监控 Node.js 的哪些指标属性,其次在业务层面我们又应该主动上报哪些信息来作为监控指标。
在 Node.js 进程方面我们要监控以下几个指标。
- 事件延迟,因为 Node.js 主要是事件循环,如果主线程被长时间占用,就会导致事件执行有延迟,而最简单的办法就是使用 setTimeout 来判断。当我们设定 1000ms 执行某个事件,但是真正开始执行的时间大于 1000ms,那么我们就可能存在事件延迟了,而如果这个延迟越来越长,那么就必须进行告警提示开发者需要查看是否有异常事件被卡住,或者服务压力过大。
- CPU 使用率,这是一个非常重要的指标,当发现 CPU 使用率长期维持在 70% 以上,我们就要考虑是否需要扩容,或者是增加进程的方式来解决这个问题,如果长期在 100% 那么肯定是需要扩容,或者检查内部代码逻辑是否存在问题。
- 内存变化,Node.js 的内存泄漏还是比较常见的,其最大的问题就是导致垃圾回收时间变长,从而影响 Node.js 的服务性能,最大的影响就是内存达到上限后进行重启,从而中断用户请求,引发在重启过程中的用户请求。
- 句柄变化,由于服务器的句柄是有上限的,如果无节制地开启句柄,将会导致系统性能损耗,从而影响进程的性能,因此我们必须在未使用句柄时进行释放,而如果长期不释放就会在达到上限时,导致新的请求无法开启新的句柄,从而无法正常提供服务。
- 进程异常重启次数,也是用来判断我们代码逻辑是否足够健壮的一个点,如果存在异常重启次数,那么一定是我们代码中存在未 catch 住的异常,或者说上面提到的内存泄漏上限问题。
以上指标在达到一定限度的时候,就应该进行告警提示开发者。
在业务层面,我们主要是关心服务提供的业务响应速度,我们需要把所有的接口按照以下指标进行上报(这点和其他后台服务差异不大)。
- 接口名称,主要是用来区分接口的唯一性。
- 接口请求时服务器时间,用来保留用户请求的时间节点。
- 接口的请求用户分类标识,有些需要根据设备、地区、网络运营商、版本信息等进行不同纬度的数据统计,因此这部分需要根据自身业务进行上报。
- 接口请求耗时,尽量细分,比如 Node.js 内部逻辑耗时、第三方接口耗时以及一些存储服务的请求耗时,例如 Redis、MySQL、MongoDB 等。
- 当前服务器 IP,有些可能和服务器有关,比如如果负载均衡未做好,导致部分机器分发的请求过大,从而引发部分机器过载的问题,因此上报当前服务器的 IP 也是非常关键的点。
拿到上面这些指标数据后,我们就可以在类似 Grafana 平台中进行数据配置和监控告警设置,当接口耗时对比昨天同时刻出现较大波动时,或者超出用户可接受的响应时间时则进行告警。
总结
学完本讲后,你首先应该明白为什么进程的安全是一个比较重要的原因,其次要掌握一些基础的会导致进程异常的问题以及如何优化的方案,最后就是要了解目前 Node.js 监控指标以及当前适合 Node.js 的告警监控平台。
别忘了上文提到的,让我们在留言区一起完善报错指引。
下一讲我们将针对本讲中所提到的内存泄漏问题进行详细阐述,教你如何一步步定位到内存泄漏的问题,其次在 GitHub 源码中会发现 router 的路由对象越来越大了,我们也需要进一步去优化,在下一讲中,我们会直接使用优化后的路由文件,也会顺便介绍优化的方法。

《大前端高薪训练营》
对标阿里 P7 技术需求 + 每月大厂内推,6 个月助你斩获名企高薪 Offer。点击链接,快来领取!

若有收获,就点个赞吧
0 人点赞
