前端基础建设与架构 - 前百度资深前端开发工程师 - 拉勾教育
在前面第 28 讲 “设计性能守卫系统:完善 CI/CD 流程”中我们提到了 Puppeteer。事实上,以 Puppeteer 为代表的 Headless 浏览器在 Node.js 中的应用极为广泛,这一讲,就让我们对 Puppeteer 进行深入分析和应用。
Puppeteer 介绍和原理
我们先对 Puppeteer 进行一个基本介绍。(Puppeteer 官方地址)
Puppeteer 是一个 Node 库,它提供了一整套高级 API,通过 DevTools 协议控制 Chromium 或 Chrome。正如其翻译为 “操纵木偶的人” 一样,你可以通过 Puppeteer 提供的 API 直接控制 Chrome,模拟大部分用户操作,进行 UI 测试或者作为爬虫访问页面来收集数据。
整个定义非常好理解,这里需要开发者注意的是,Puppeteer 在 1.7.0 版本之后,会同时给开发者提供:
- Puppeteer
- Puppeteer-core
两个版本。它们的区别在于载入安装 Puppeteer 时,是否会下载 Chromium。Puppeteer-core 默认不下载 Chromium,同时会忽略所有 puppeteer_ 环境变量。对于开发者来说,使用 Puppeteer-core 无疑更加轻便,但是*需要提前保证环境中已经具有可执行的 Chromium(具体说明可见puppeteer vs puppeteer-core)。
具体 Puppeteer 的应用场景有:
- 为网页生成页面 PDF 或者截取图片;
- 抓取 SPA(单页应用)并生成预渲染内容;
- 自动提交表单,进行 UI 测试、键盘输入等;
- 创建一个随时更新的自动化测试环境,使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试;
- 捕获网站的timeline trace,用来帮助分析性能问题;
- 测试浏览器扩展。
下面我们就梳理一些 Puppeteer 应用的重点场景,并详细介绍如何使用 Puppeteer 实现一个高性能的海报 Node.js 服务。
Puppeteer 在 SSR 中的应用
区别于第 27 讲介绍的“同构渲染架构:实现一个 SSR 应用”,使用 Puppeteer 实现服务端预渲染出发点完全不同。这种方案最大的好处是不需要对项目代码进行任何调整,却能获取到 SSR 应用的收益。当然,相比同构渲染,基于 Puppeteer 技术的 SSR 在灵活性和扩展性上都有所局限。甚至在 Node.js 端渲染的性能成本也较高,不过该技术也逐渐落地,并在很多场景发挥了重要价值。
比如对于这样的一个页面,代码如下:
<html><body><div id="container"></div></body><script>function renderPosts(posts, container) {const html = posts.reduce((html, post) => {return `${html}<li class="post"><h2>${post.title}</h2><div class="summary">${post.summary}</div><p>${post.content}</p></li>`;}, '');container.innerHTML = `<ul id="posts">${html}</ul>`;}(async() => {const container = document.querySelector('#container');const posts = await fetch('/posts').then(resp => resp.json());renderPosts(posts, container);})();</script></html>
该页面是一个典型的 CSR 页面,依靠 Ajax,实现了页面动态化渲染。
当在 Node.js 端使用 Puppeteer 渲染时,我们可以实现ssr.mjs,完成渲染任务,如下代码:
import puppeteer from 'puppeteer';const RENDER_CACHE = new Map();async function ssr(url) {if (RENDER_CACHE.has(url)) {return {html: RENDER_CACHE.get(url), ttRenderMs: 0};}const start = Date.now();const browser = await puppeteer.launch();const page = await browser.newPage();try {await page.goto(url, {waitUntil: 'networkidle0'});await page.waitForSelector('#posts');} catch (err) {console.error(err);throw new Error('page.goto/waitForSelector timed out.');}const html = await page.content();await browser.close();const ttRenderMs = Date.now() - start;console.info(`Headless rendered page in: ${ttRenderMs}ms`);RENDER_CACHE.set(url, html);return {html, ttRenderMs};}export {ssr as default};
对应server.mjs代码:
import express from 'express';import ssr from './ssr.mjs';const app = express();app.get('/', async (req, res, next) => {const {html, ttRenderMs} = await ssr(`xxx/index.html`);res.set('Server-Timing', `Prerender;dur=${ttRenderMs};desc="Headless render time (ms)"`);return res.status(200).send(html);});app.listen(8080, () => console.log('Server started. Press Ctrl+C to quit'));
当然上述实现比较简陋,只是进行原理说明。如果更进一步,我们可以从以下几个角度进行优化:
- 改造浏览器端代码,防止重复请求接口;
- 在 Node.js 端,abort 掉不必要的请求,以得到更快的服务端渲染响应速度;
- 将关键资源内连进 HTML;
- 自动压缩静态资源;
- 在 Node.js 端,渲染页面时,重复利用 Chrome 实例。
这里我们用简单代码进行说明:
import express from 'express';import puppeteer from 'puppeteer';import ssr from './ssr.mjs';let browserWSEndpoint = null;const app = express();app.get('/', async (req, res, next) => {if (!browserWSEndpoint) {const browser = await puppeteer.launch();browserWSEndpoint = await browser.wsEndpoint();}const url = `${req.protocol}:const {html} = await ssr(url, browserWSEndpoint);return res.status(200).send(html);});
至此,我们从原理和代码层面分析了 Puppeteer 在 SSR 中的应用。接下来我们来了解更多的 Puppeteer 使用场景,请你继续阅读。
Puppeteer 在 UI 测试中的应用
Puppeteer 在 UI 测试(即端到端测试)中也可以大显身手,比如和 Jest 结合,通过断言能力实现一个完备的端到端测试系统。
比如下面代码:
const puppeteer = require('puppeteer');test('baidu title is correct', async () => {const browser = await puppeteer.launch()const page = await browser.newPage()await page.goto('https://xxxxx')const title = await page.title()expect(title).toBe('xxxx')await browser.close()});
上面代码简单清晰地勾勒出了 Puppeteer 结合 Jest 实现端到端测试的场景。实际上,现在流行的主流端到端测试框架,比如 Cypress 原理都如上代码所示。
接下来,我们来分析 Puppeteer 结合 Lighthouse 应用场景。
Puppeteer 结合 Lighthouse 应用场景
在第 28 讲 “设计性能守卫系统:完善 CI/CD 流程”中我们也提到了 Lighthouse,既然 Puppeteer 可以和 Jest 结合实现一个端到端测试框架,当然也可以和 Lighthouse 结合——这就是一个简单的性能守卫系统的雏形。
我们再通过代码来说明,如下代码:
const chromeLauncher = require('chrome-launcher');const puppeteer = require('puppeteer');const lighthouse = require('lighthouse');const config = require('lighthouse/lighthouse-core/config/lr-desktop-config.js');const reportGenerator = require('lighthouse/lighthouse-core/report/report-generator');const request = require('request');const util = require('util');const fs = require('fs');(async() => {const opts = {logLevel: 'info',output: 'json',disableDeviceEmulation: true,defaultViewport: {width: 1200,height: 900},chromeFlags: ['--disable-mobile-emulation']};const chrome = await chromeLauncher.launch(opts);opts.port = chrome.port;const resp = await util.promisify(request)(`http:const {webSocketDebuggerUrl} = JSON.parse(resp.body);const browser = await puppeteer.connect({browserWSEndpoint: webSocketDebuggerUrl});page = (await browser.pages())[0];await page.setViewport({ width: 1200, height: 900});console.log(page.url());const report = await lighthouse(page.url(), opts, config).then(results => {return results;});const html = reportGenerator.generateReport(report.lhr, 'html');const json = reportGenerator.generateReport(report.lhr, 'json');await browser.disconnect();await chrome.kill();fs.writeFile('report.html', html, (err) => {if (err) {console.error(err);}});fs.writeFile('report.json', json, (err) => {if (err) {console.error(err);}});})();
整体流程非常清晰,是一个典型的 Puppeteer 与 Lighthouse 结合的案例。事实上,我们看到 Puppeteer 或 Headless 浏览器可以和多个领域能力相结合,在 Node.js 服务上实现平台化能力。接下来,我们再看最后一个案例,请读者继续阅读。
Puppeteer 实现海报 Node.js 服务
社区上我们常见生成海报的技术分享。应用场景很多,比如文稿中划线,进行 “金句分享”,如下图所示:

一般来说,生成海报可以使用html2canvas这样的类库完成,这里面的技术难点主要有跨域处理、分页处理、页面截图时机处理等。整体来说,并不难实现,但是稳定性一般。另一种生成海报的方式就是使用 Puppeteer,构建一个 Node.js 服务来做页面截图。
下面我们来实现一个名叫 posterMan 的海报服务,整体技术链路如下图:
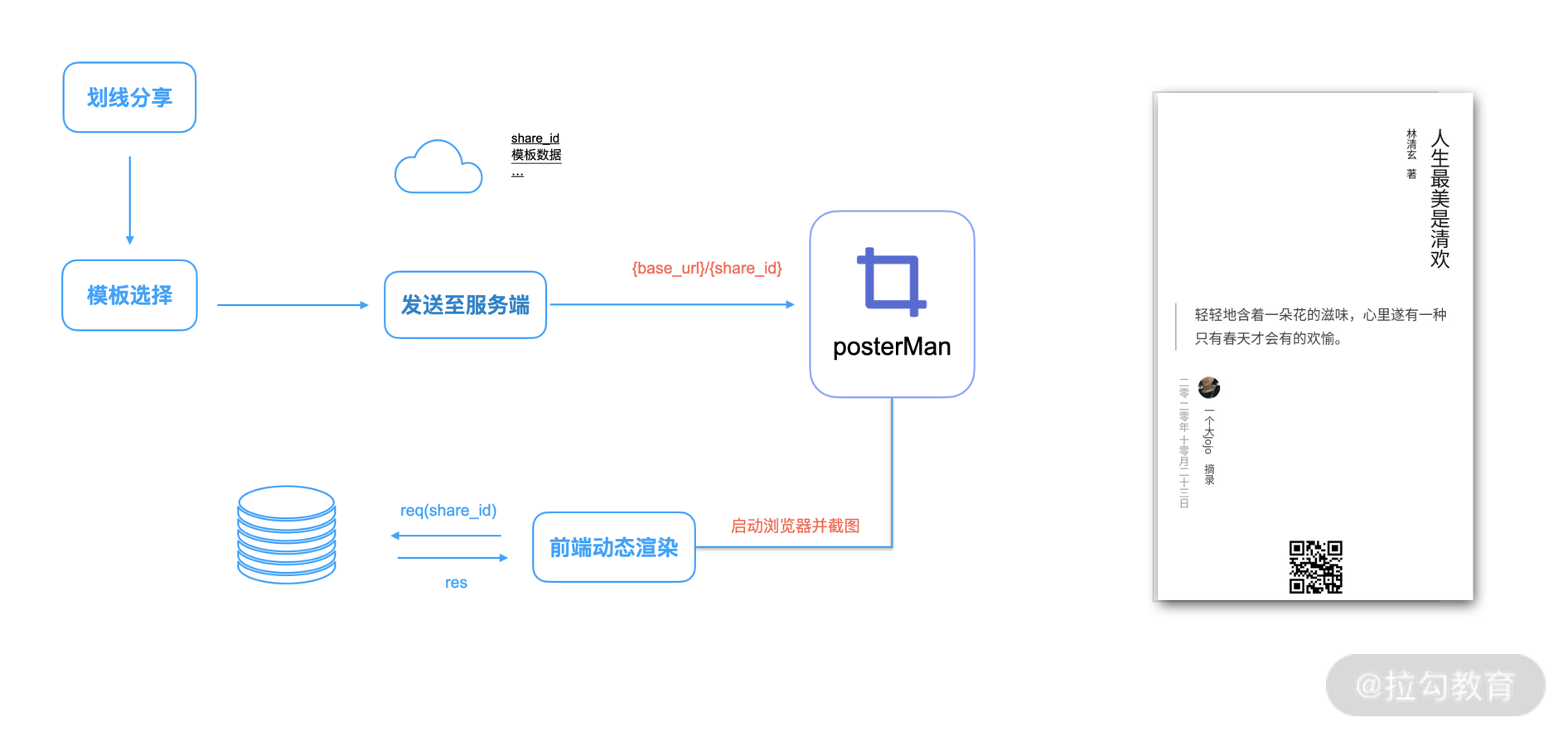
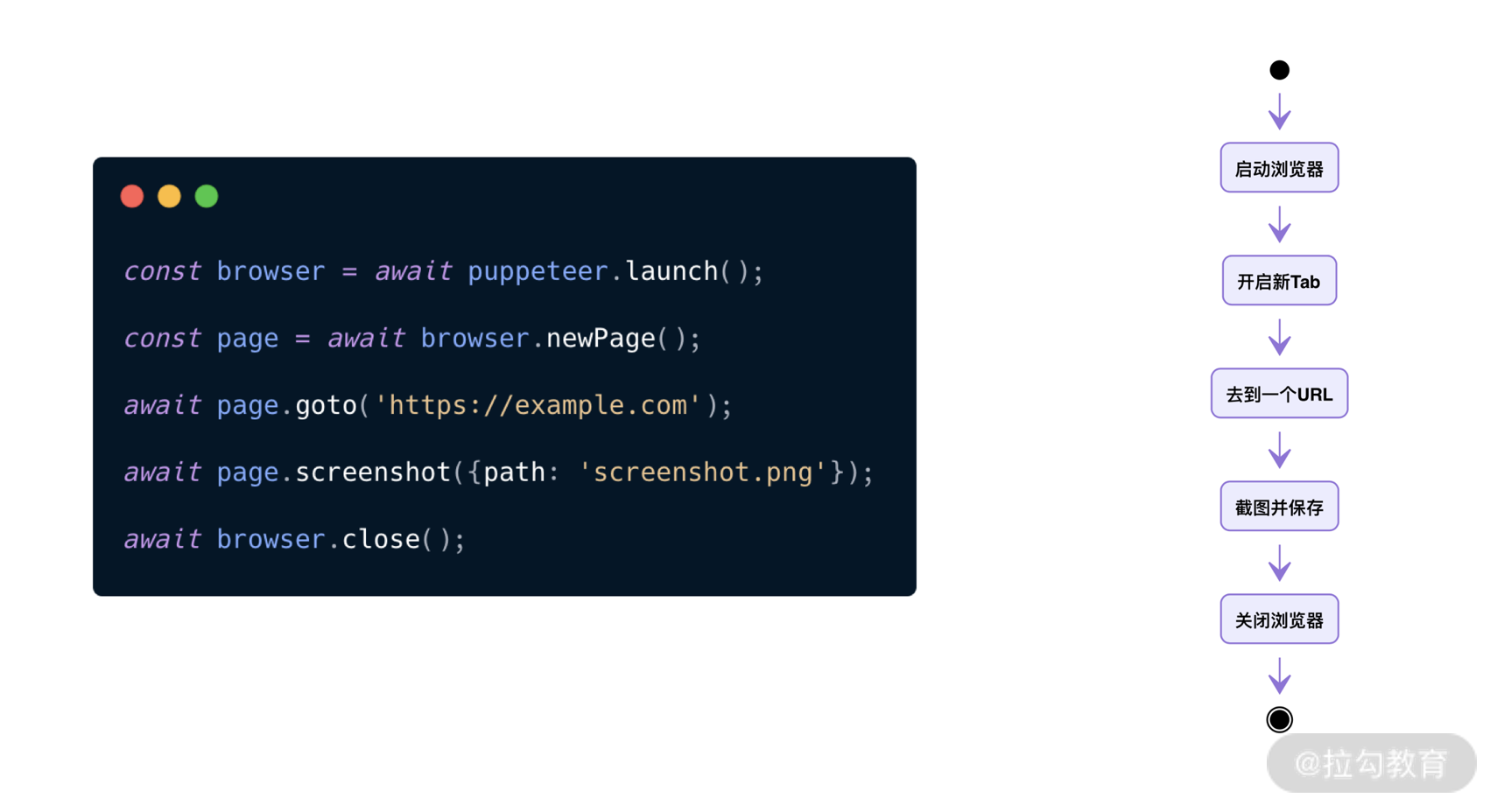
核心技术无外乎使用 Puppeteer,访问页面并截图,这与前面几个场景是一样的,如下图所示:
这里需要特别强调的是,为了实现最好的性能,我们设计了一个链接池来存储 Puppeteer 实例,以备所需,如下图所示:
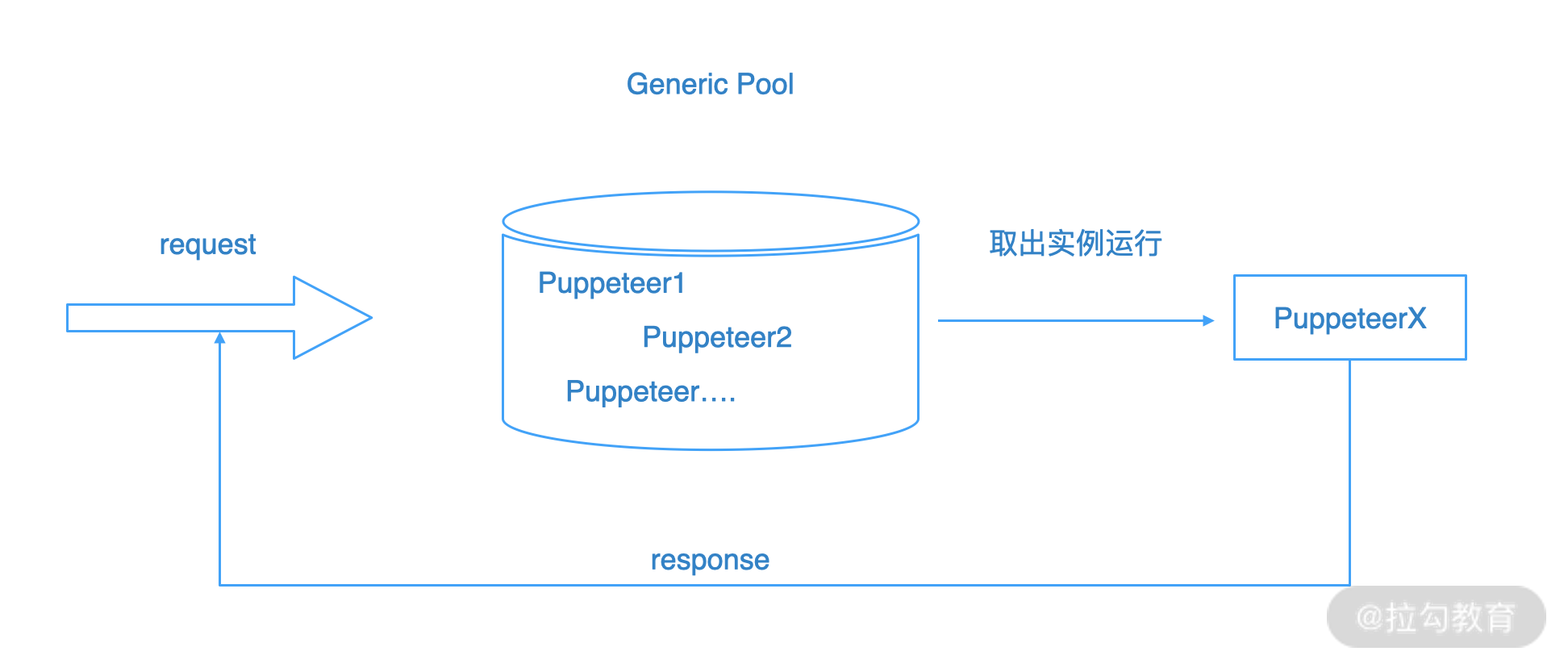
在实现上,我们依赖generic-pool库,这个库提供了 Promise 风格的通用池,可以用来对一些高消耗、高成本资源的调用实现防抖或拒绝服务能力,一个典型场景是对数据库的连接。这里我们把它用于 Puppeteer 实例的创建,如下代码所示:
const puppeteer = require('puppeteer')const genericPool = require('generic-pool')const createPuppeteerPool = ({max = 10,min = 2,idleTimeoutMillis = 30000,maxUses = 50,testOnBorrow = true,puppeteerArgs = {},validator = () => Promise.resolve(true),...otherConfig} = {}) => {const factory = {create: () =>puppeteer.launch(puppeteerArgs).then(instance => {instance.useCount = 0return instance}),destroy: instance => {instance.close()},validate: instance => {return validator(instance).then(valid =>Promise.resolve(valid && (maxUses <= 0 || instance.useCount < maxUses)))}}const config = {max,min,idleTimeoutMillis,testOnBorrow,...otherConfig}const pool = genericPool.createPool(factory, config)const genericAcquire = pool.acquire.bind(pool)pool.acquire = () =>genericAcquire().then(instance => {instance.useCount += 1return instance})pool.use = fn => {let resourcereturn pool.acquire().then(r => {resource = rreturn r}).then(fn).then(result => {pool.release(resource)return result},err => {pool.release(resource)throw err})}return pool}module.exports = createPuppeteerPool
使用连接池的方式也很简单,如下代码,./pool.js:
const pool = createPuppeteerPool({puppeteerArgs: {args: config.browserArgs}})module.exports = pool
有了 “武器弹药”,我们来看看渲染一个页面为海报的具体逻辑。如下代码所示render方法,该方法支持接受一个 URL 也支持接受具体的 HTML 字符串去生成相应海报:
const pool = require('./pool')const config = require('./config')const render = (ctx, handleFetchPicoImageError) =>pool.use(async browser => {const { body, query } = ctx.requestconst page = await browser.newPage()let html = bodyconst {width = 300,height = 480,ratio: deviceScaleFactor = 2,type = 'png',filename = 'poster',waitUntil = 'domcontentloaded',quality = 100,omitBackground,fullPage,url,useCache = 'true',usePicoAutoJPG = 'true'} = querylet imagetry {await page.setViewport({width: Number(width),height: Number(height),deviceScaleFactor: Number(deviceScaleFactor)})if (html.length > 1.25e6) {throw new Error('image size out of limits, at most 1 MB')}await page.goto(url || `data:text/html,${html}`, {waitUntil: waitUntil.split(',')})image = await page.screenshot({type: type === 'jpg' ? 'jpeg' : type,quality: type === 'png' ? undefined : Number(quality),omitBackground: omitBackground === 'true',fullPage: fullPage === 'true'})} catch (error) {throw error}ctx.set('Content-Type', `image/${type}`)ctx.set('Content-Disposition', `inline; filename=${filename}.${type}`)await page.close()return image})module.exports = render
至此,基于 Puppeteer 的海报系统就已经开发完成了。它是一个对外的 Node.js 服务。
我们也可以生成各种语言的 SDK 客户端,调用该海报服务。比如一个简单的 Python 版 SDK 客户端实现如下代码:
import requestsclass PosterGenerator(object):def generate(self, **kwargs):"""生成海报图片,返回二进制海报数据:param kwargs: 渲染时需要传递的参数字典:return: 二进制图片数据"""html_content = render(self._syntax, self._template_content, **kwargs)url = POSTER_MAN_HA_PROXIES[self._api_env.value]try:resp = requests.post(url,data=html_content.encode('utf8'),headers={'Content-Type': 'text/plain'},timeout=60,params=self.config)except RequestException as err:raise GenerateFailed(err.message)else:if not resp:raise GenerateFailed(u"Failed to generate poster, got NOTHING from poster-man")try:resp.raise_for_status()except requests.HTTPError as err:raise GenerateFailed(err.message)else:return resp.content
总结
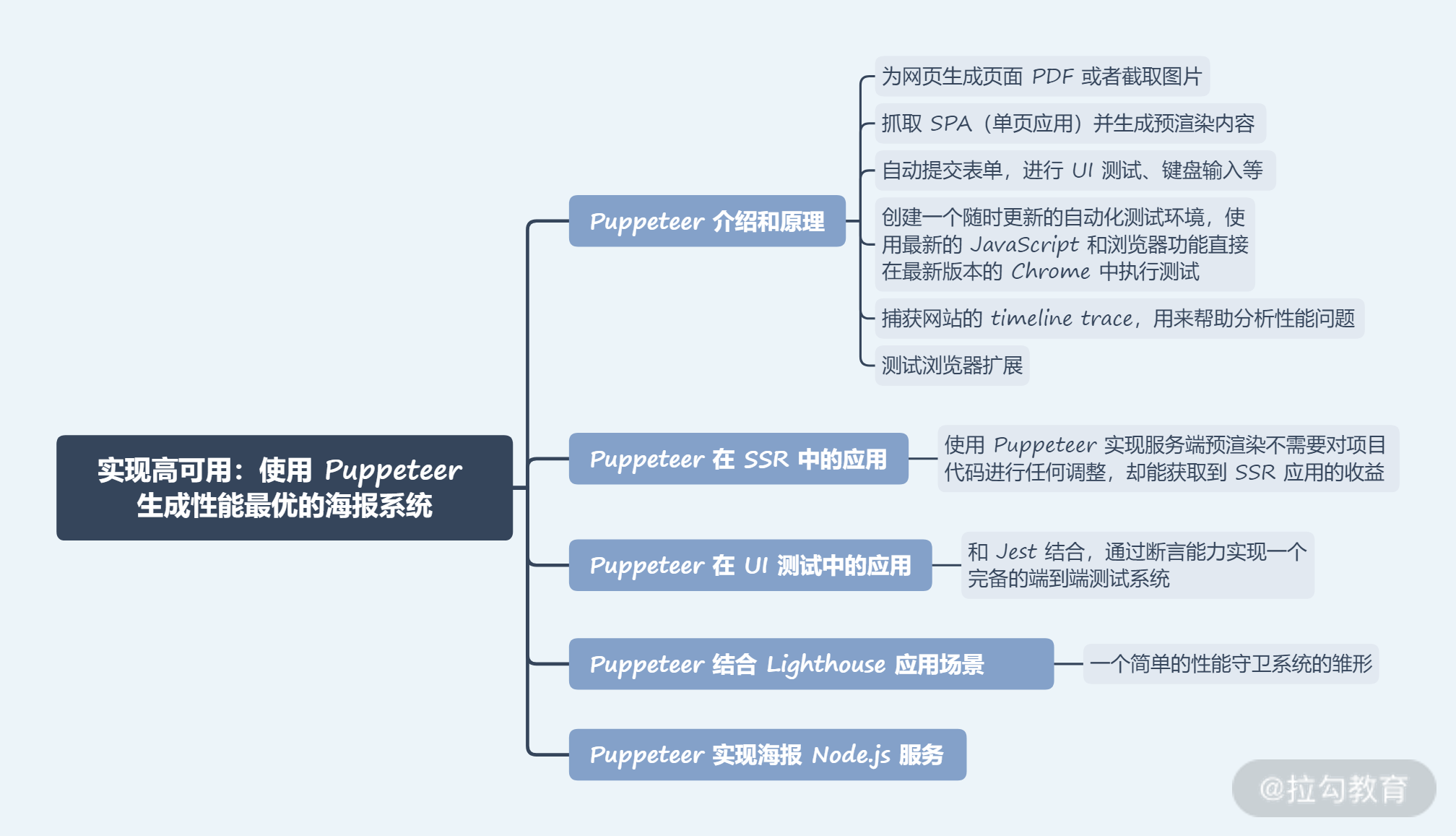
这一讲我们介绍了 Puppeteer 的各种应用场景,并重点介绍了一个基于 Puppeteer 设计实现的海报服务系统。
本讲内容总结如下:
通过这几讲的学习,希望你能够从实践出发,对 Node.js 落地应用有一个更全面的认知。这里我也给大家留一个思考题,你平时开发中使用过 Puppeteer 吗?你还能基于 Puppeteer 想到哪些使用场景呢?欢迎在留言区和我分享你的经验。

若有收获,就点个赞吧
0 人点赞
