Node.js 应用开发实战 - 高级前端开发工程师 - 拉勾教育
在《06 | 哪些因素会影响 Node.js 性能?》中我们有提到 I/O 不会影响整体 Node.js 服务的性能,但是会因为 I/O 影响服务器系统,从而侧面影响到 Node.js 性能。本讲就着重介绍磁盘 I/O 和网络 I/O 两个方面在研发过程中注意的要点。
I/O 基础介绍
I/O(Input/Output)意思是输入输出,其实就是数据传递的一个过程,作为后台服务需要更多地与外部进行数据交互,那么就免不了 I/O 操作。I/O 的类型也是非常多的,我们应该掌握常用的一些 I/O 模型分类。
I/O 分为以下 5 种模型,在介绍分类之前,我们先了解 I/O 在系统层面会有 2 个阶段(以读为例子):
- 第一个阶段是读取文件,将文件放入操作系统内核缓冲区;
- 第二阶段是将内核缓冲区拷贝到应用程序地址空间。
1. 阻塞 I/O
例如读取一个文件,我们必须要等待文件读取完成后,也就是完成上面所说的两个阶段,才能执行其他逻辑,而当前是无法释放 CPU 的,因此无法去处理其他逻辑。
2. 非阻塞 I/O
非阻塞的意思是,我们发起了一个读取文件的指令,系统会返回正在处理中,然后这时候如果要释放进程中的 CPU 去处理其他逻辑,你就必须间隔一段时间,然后不停地去询问操作系统,使用轮询的判断方法看是否读取完成了。
3. 多路复用 I/O
这一模型主要是为了解决轮询调度的问题,我们可以将这些 I/O Socket 处理的结果统一交给一个独立线程来处理,当 I/O Socket 处理完成后,就主动告诉业务,处理完成了,这样不需要每个业务都来进行轮询查询了。
它包括目前常见的三种类型:select 、poll 和 epoll。首先 select 是比较旧的,它和 poll 的区别在于 poll 使用的是链表来保存 I/O Socket 数据,而 select 是数组,因此 select 会有上限 1024,而 poll 则没有。select、poll 与 epoll 的区别在于,前两者不会告诉你是哪个 I/O Socket 完成了,而 epoll 会通知具体哪个 I/O Socket 完成了哪个阶段的操作,这样就不需要去遍历查询了。
当然这里有一个重点是这三者只会告知文件读取进入了操作系统内核缓冲区,也就是上面我们所说的第一阶段,但是第二阶段从内核拷贝到应用程序地址空间还是同步等待的。
4. 信号驱动 I/O
这种模式和多路复用的区别在于不需要有其他线程来处理,而是在完成了读取进入操作系统内核缓冲区后,立马通知,也就是第一阶段可以由系统层面来处理,不需要独立线程来管理,但是第二阶段还是和多路复用一样。
5. 异步 I/O
和信号驱动不同的是,异步 I/O 是两个阶段都完成了以后,才会通知,并不是第一阶段完成。
我们常说的 Node.js 是一个异步 I/O 这个是没有错的。具体来说 Node.js 是其 libv 库自行实现的一种类似异步 I/O 的模型,对于 Node.js 应用来说是一个异步 I/O,因此无须处理两个过程,而在 libv 内部实现,则是多线程的一个 epoll 模型。这点是非常重要的,希望你可以牢记。
在了解了以上基础知识后,我们再来分析在 Node.js 中如何进行代码优化才能达到极致的性能。我们从两个方面来介绍:
- 本地磁盘 I/O;
- 远程网络 I/O。
本地磁盘 I/O
根据以上结论,我们可以思考以下六点:
- 如果是写 I/O,并且不需要获取写入结果时,则不需要进行回调处理,减少主线程压力,比如最常见的例子就是写日志;
- 如果是写 I/O,可以使用文件流的方式,避免重复的打开同一个文件,损耗不必要的打开和关闭文件的过程;
- 如果是写 I/O,为了缓解写并发对系统的压力,可以将需要写入的日志放入一个临时内存中,从而降低系统并发处理压力,从而降低系统负载;
- 如果是读 I/O,并且需要获取读取结果时,能够使用缓存尽量使用缓存,因为读 I/O 是需要时间,虽然不影响主线程性能,但是会影响用户响应时间,当读 I/O 过大,则系统压力较大,从而影响整体读接口的性能,因此需要使用缓存,减少并发对系统的 I/O 压力;
- 如果是读 I/O,并且无法进行缓存的,则尽量考虑不使用本地磁盘 I/O 操作;
- 如果是读 I/O,涉及大文件读取操作时,则应使用数据流的方式,而不是一次性读取内存中进行处理。
接下来我们看下几个实际场景,并且介绍如何去实现上面几点。
文件读取
后台服务会涉及较多的配置文件,而读取配置文件是与第 4 个场景相似的,因此这类情况处理比较简单,只需要在程序启动时,将配置文件读取到内存中即可。
另外一种就是读取大文件,这点和第 6 个大文件场景相似,比如说一次性读取一个 Excel 的大文件,然后对每一行进行处理,这时候如果使用 Node.js 的 fs 会导致性能问题,并且处理时间也会非常长,这部分应该尽量使用文件流方式。
日志模块
日志存在很大的写情况,和我们上面说的 1、2 、3 场景是一致的,因此我们需要从这 3 个方面去提升性能。
接下来我们就来实现一个简单版本,包含这 3 个性能提升的点的模块:
- 保存待写入的日志信息,当超出最大保存日志条数时,则直接写入,不保存在日志信息中,主要是避免内存过大,引起垃圾回收性能问题;
- 定时从临时缓存中,取出数据写入文件中;
- 写入文件后,无须处理回调。
为了避免内存占用过大,我们设置最大的文件句柄保存数为 1000 个,每个文件最大的日志临时保存数为 100000 ,因此最大可能占用的内存为 1000*100000/1024/1024,约等于 100 M。将这些默认参数作为日志的变量,可供外部传入配置,如下所示:
** @param {boolean} cacheEnable 是否打开日志缓存模式,默认打开* @param {int} cacheTime 缓存处理时间,默认 2 秒,会定时入文件* @param {int} maxLen 单个日志文件最大缓存长度,默认100000* @param {int} maxFileStream 最大缓存文件句柄数,默认是 1000*/constructor(cacheEnable=true, cacheTime=2000, maxLen=100000, maxFileStream=1000) {this.cacheTime = cacheTime;this.cacheEnable = cacheEnable;this.maxLen = maxLen;this.maxFileStream = maxFileStream;this.currentFileStreamNum = 0;}
接下来我们看下整体日志逻辑的设计流转,如图 1 所示。

图 1 日志模块逻辑
在上面逻辑中日志写入有 2 个入口:
- info(假设只有一种 info 日志)
- start
info 会调用 _flush 判断当前缓存是否已满,或者是否开启了缓存,如果没有开启或者缓存已满,则直接调用 _addLog 写入日志,其他情况都写入缓存中。
start 会定时从临时缓存中获取待写入的日志内容,如果有则调用 _addLog 写入日志,写入完成后会调用 _clean 清理已经写入的内容,其次会清理未使用的空文件流句柄,避免空文件夹、 句柄流占用缓存。
_addLog 根据类型获取需要写入的文件路径,并调用 _getFileStream 来获取文件流句柄,这里就会用到文件流缓存,当缓存有则返回,没有则创建一个文件流句柄。
我们主要看下 _flush 和 _intervalWrite 两个代码,_flush 的代码实现逻辑如图 2 所示:
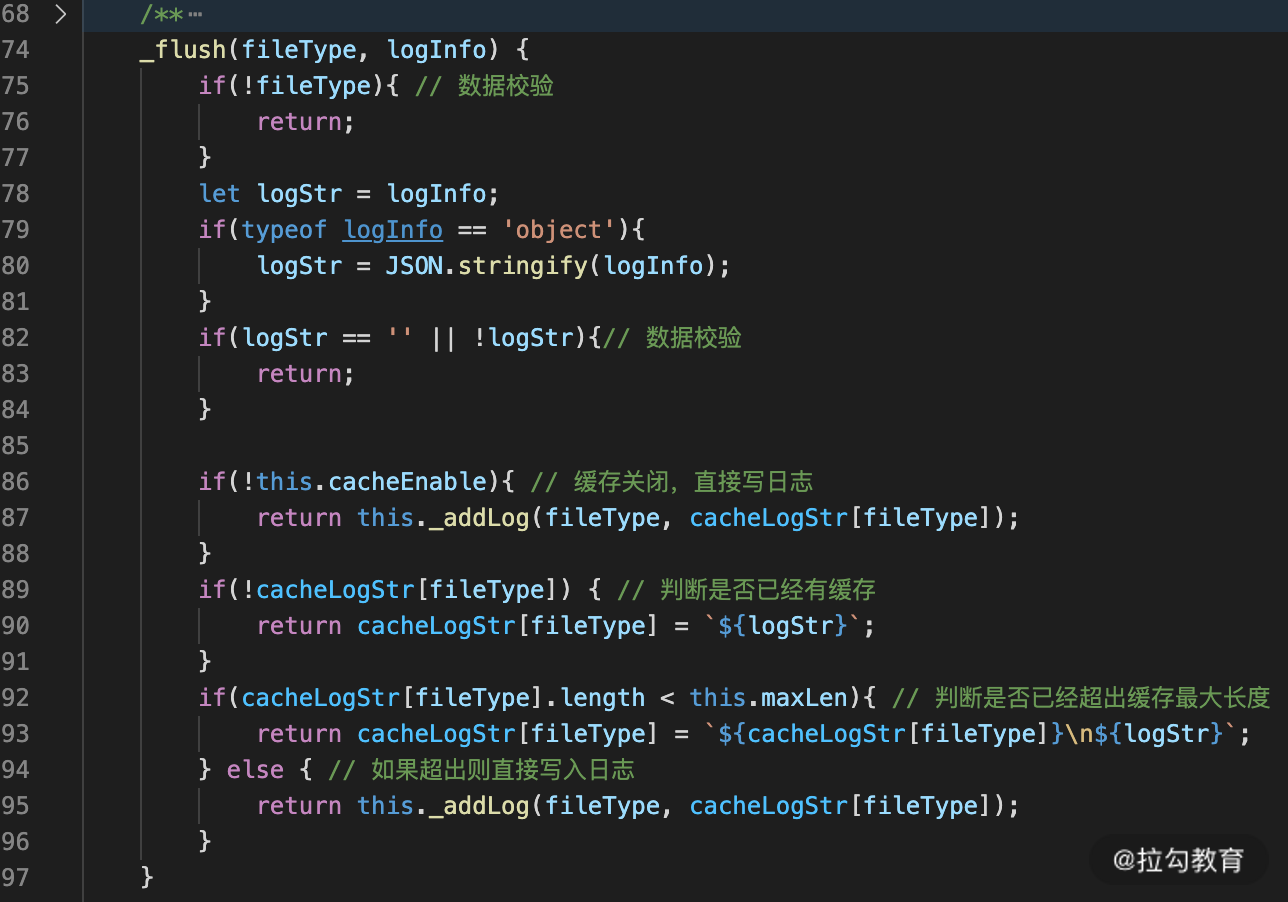
图 2 _flush 代码实现逻辑
这块代码最主要就是判断是否开启了缓存以及当前文件流是否超出了最大缓存,如果这两个条件任意一个满足,则直接写日志,不经过临时缓存。
_intervalWrite 的代码实现逻辑如图 3 所示:
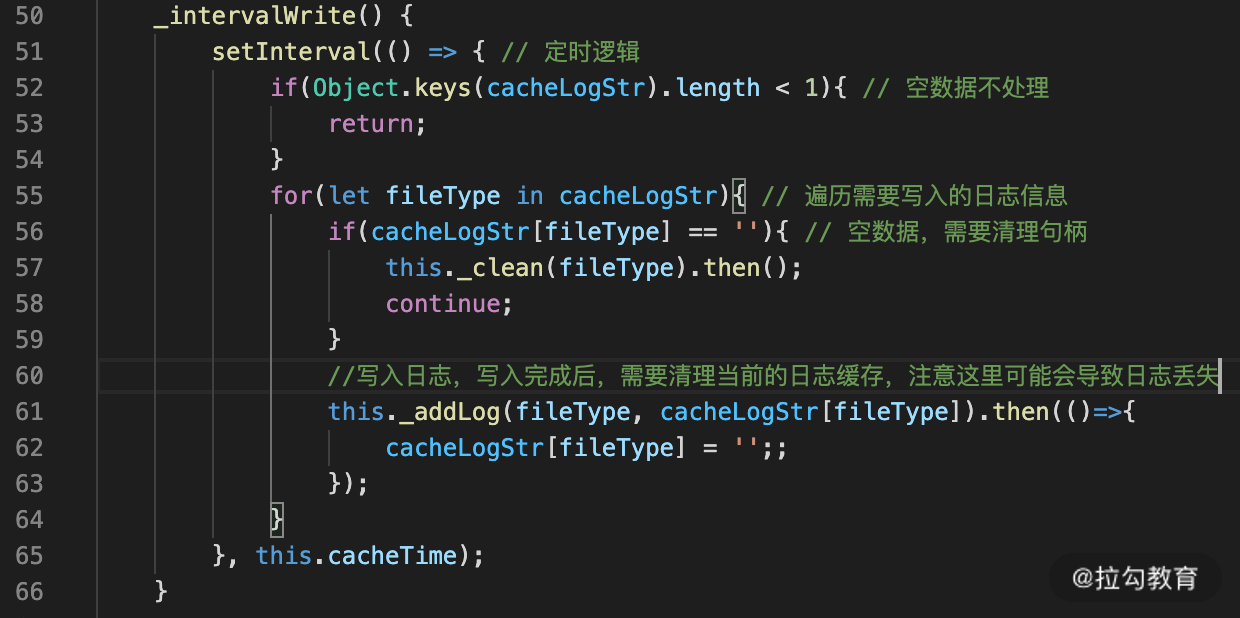
图 3 _intervalWrite 代码实现
在上面代码中使用了 setInterval 定时获取临时缓存数据,并写入文件。
在代码 57 行中,对空缓存的文件流句柄进行清理,避免一些没用的句柄缓存一直占用缓存数据。
其次在代码 61 行中可能会丢失日志,主要是在写入日志完成后,还没清理,又有数据写入了临时缓存中,导致部分丢失的现象,默认情况下允许这种情况,因为这种丢失的现象概率比较低。
在 GitHub 源码中,我们可以打开本讲的代码,并且在项目根目录运行以下命令,启动调试。
运行成功后,访问如下地址:
然后打开根目录下的 log 文件夹,就可以看到具体的日志信息了,具体信息如下所示:
good success 0.4400041351511781good success 0.8533540410020264good success 0.05602191887030328good success 0.9211995961759676good success 0.18125957486134014
以上就是一个性能较好的日志服务,具体的性能数据我们后续再通过《12 | 性能分析:性能影响的关键路径以及优化策略》中的压测来进行对比分析。
网络 I/O
在后台服务中常见的网络 I/O 有如下几种类型:
- 缓存型,如 MemCache、Redis;
- 数据存储型,如 MySQL、MongoDB;
- 服务型,如内网 API 服务或者第三方 API。
网络 I/O 的成本是最高的,因为会涉及两个最重要的点:
- 依赖其他服务的性能;
- 依赖服务器之间的延时。
针对上面的两个最重要的点,我们可以从以下几个方面来考虑优化的策略:
- 减少与网络 I/O 的交互,比如缓存已获取的内容;
- 使用更高性能的网络 I/O 替代其他性能较差的、成本更高的网络 I/O 类型,比如数据库读写的 I/O 成本是明显高于缓存型的,因此可以使用缓存型网络 I/O 替换存储型;
- 降低目标网络 I/O 服务的并发压力,可以采用异步队列方式。
下面我们就来看下以上三种方式的实现方案。
减少网络 I/O
对于一些与用户维度不相关的数据,或者批次用户数据类似的情况,我们可以通过网络 I/O 获取数据后,缓存在本地服务器上,后面只需要从本地内存中读取即可。
这部分我们还是来看一个计算的逻辑,在 Controller 新增了一个叫作 locaCache.js 的文件,然后创建 yes 和 no 两个方法,分别对应接口路由为:
代码实现如图 4 所示:
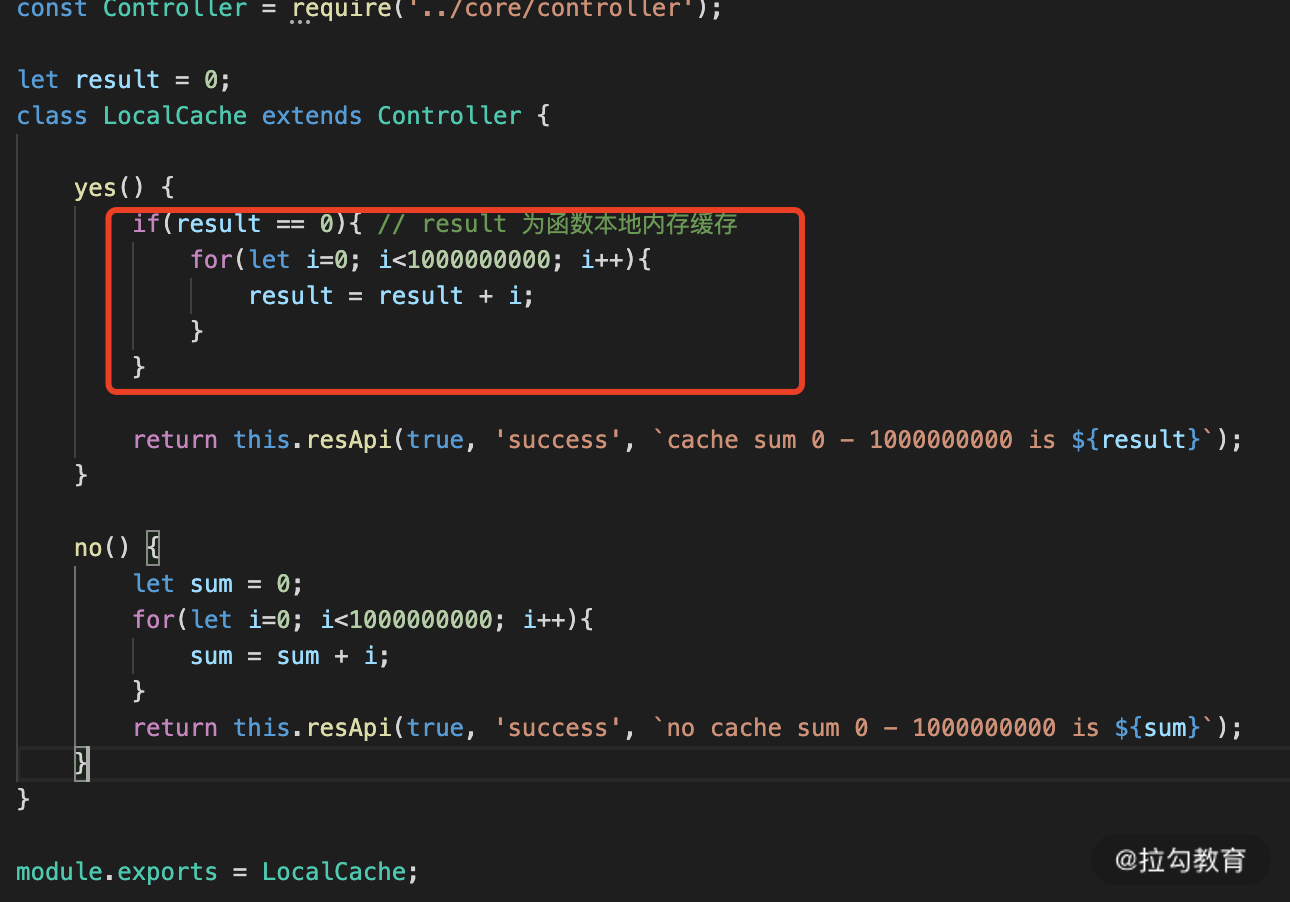
图 4 本地缓存代码例子
其中 yes 函数中就是增加了本地内存缓存,而 no 则没有。
接下来启动服务,我们使用如下两条命令(或者使用浏览器,打开 Chrome 的 Network 查看耗时)多次运行查看耗时情况。
time curl http:time curl http:
你会发现 /v1/cache 只有第一次耗时比较久,后面都非常快,而 /v1/no-cache 则每次耗时都比较久。
因此本地缓存对于这种固定化,并且无用户差别的数据是可以进行缓存的,而且非常有必要。比如说,我们常见的一些客户端配置化信息。
不过本地内存缓存有一个最大的问题点在于,每台机器可能缓存了不同的数据,比如每台机器缓存了运营配置,这时候运营修改了配置,不同机器过期时间不一致,导致用户每次刷新可能出现不同的首页配置。那么这个问题就需要高性能替换方案(共享内存方案)来解决了。
高性能替换
本地缓存是直接本地内存,性能高过共享内存,也就是网络 I/O 中的共享内存方式,但是网络 I/O 共享内存的性能高于网络 I/O 中的磁盘 I/O 性能。比如 Redis 的性能是远高于 MySQL 的,主要有一点是前两者是共享内存的方式,内存的操作是快于磁盘 I/O。因此可以通过 MySQL 获取数据后保存在高性能网络 I/O 的 Redis 上,这样可以大大提升性能。其次共享内存方案也可以解决本地缓存中数据不一致的问题。
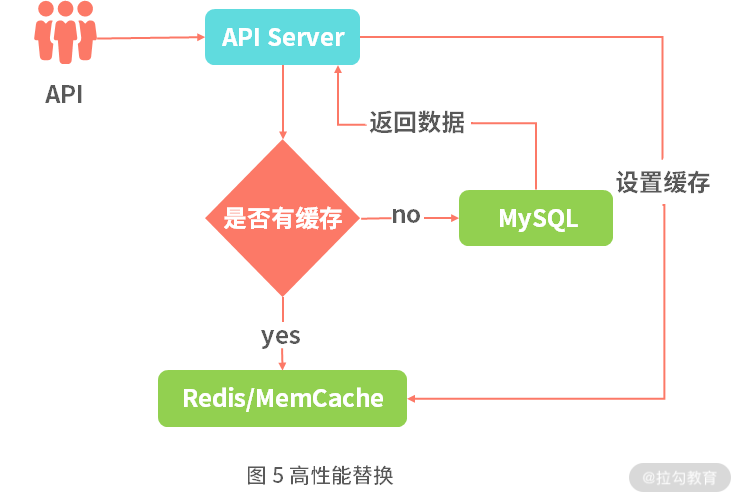
在图 5 中我们访问 API 服务,在 API 中判断获取的数据是否有缓存,有缓存则直接从共享内存服务中读取,如果没有则先前往 MySQL 获取具体的数据,返回到 API 服务以后,再设置共享内存,这样下次用户来访问该数据时,就有相应的数据了。从而实现了高性能网络 I/O 替换低性能网络 I/O 的方案。
共享内存适合那些可以延迟更新的数据服务,并且与用户维度无关,每个用户(或者有限用户分类)拉取的内容都是一致的。如果每个用户内容不一致,会导致缓存命中较低,同时浪费大量的内存空间。
异步队列
举一个用户抢票的例子,如果每个用户抢票,我们都执行一次查询并且购票,那么对于目标机器则压力非常大,特别像 12306 这种几亿人同时抢的情况,那么这里就可以采用异步队列的方式,也就是用户发送请求后只告知用户,你已经进入队列,但是真正情况是用户的请求会缓存在一个队列中,再一个个前往具体的网络 I/O 服务中,独立去处理,这时候并发压力就可控,因此也不会出现性能问题。
具体方案如图 6 所示:
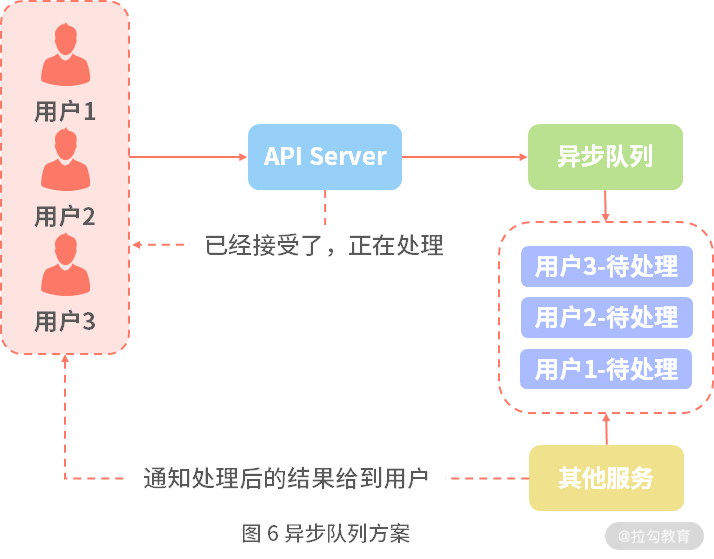
如图所示,假设我们现在有 3 个(实际情况可能几千万甚至几亿)用户同时向服务器请求,这时候服务器肯定是处理不过来的,只能告诉用户,你的请求我们已经收到了,并且在处理中了,请耐心等待通知。这时候将用户的请求放到一个队列中,然后通过另外一个服务,定时从队列中获取待处理的消息,根据实际情况处理完成后,将处理后的结果通知给具体的每个用户。
异步队列一个比较高性能的网络 I/O ,通过一个高性能网络 I/O 将其他的业务逻辑封装,让用户无感知,只是延迟了用户收到结果的时间。
以上就是网络 I/O 常见的三种优化策略,在实际应用过程中需要更巧妙和灵活的使用,我们在实战部分会详细介绍这部分代码的应用实践。
总结
本讲介绍了 I/O 的基础模型分类,需要了解 Node.js 应用层是一个异步 I/O 模型,但是其底层 libv 库是一个基于 epoll 的 I/O 模型,这点希望你可以牢记,后续面试说不定也会被问及。并介绍了在 Node.js 中常见的两种 I/O:磁盘和网络,对于这两者都存在非常多的性能问题点,本讲详细介绍了如何处理这些会导致性能问题的场景。希望学完本讲后,你能够解决 Node.js 开发过程中各种 I/O 性能问题,并且能够给出一定的性能调优方案。
那在日常开发中你遇到过哪些 I/O 性能问题,以及你是如何解决的呢,欢迎在交流区留下你的回答。
本讲中有提及用缓存来解决一部分 I/O 场景的问题,但是没有系统性地介绍,在接下来的一讲我们将详细介绍缓存的分类以及缓存的应用方案。

《大前端高薪训练营》
对标阿里 P7 技术需求 + 每月大厂内推,6 个月助你斩获名企高薪 Offer。点击链接,快来领取!

若有收获,就点个赞吧
0 人点赞
