前端基础建设与架构 - 前百度资深前端开发工程师 - 拉勾教育
前端工程化和基础建设这个话题,自然少不了分析构建工具。作为前端工程中最常见、最经典的构建工具,Webpack 必须要有一个独立小节进行精讲。可是,关于 Webpack 什么样的内容才更有意义呢?当前社区,Webpack 插件编写、loader 编写相关内容已经非常多了,甚至 Tapable 机制也已经有了涉猎。
这一讲,我们独辟蹊径,从 Webpack 的实现入手,帮助你构建一个自己的工程化工具。
Webpack 的初心和揭秘
我不建议对着 Webpack 源码讲解,因为 Webpack 是一个庞大的体系,其源码逐行讲解太过枯燥,真正能转化在技术积累上的内容较少。今天,我们先抽丝剥茧,从 Webpack 的使命谈起,相信你会有一个更加清晰的认知。
Webpack 的介绍只有简单一句:
Webpack is a static module bundler for modern JavaScript applications.
虽然 Webpack 看上去无所不能,但从其本质上来说,Webpack 实质就是一个 “前端模块打包器”。前端模块打包器做的事情很简单:它帮助开发者将 JavaScript 模块(各种类型的模块化规范)打包为一个或多个 JavaScript 脚本文件。
我们回到最初起源,前端为什么需要一个模块打包器呢?其实理由很简单:
- 不是所有浏览器都直接支持 JavaScript 规范;
- 前端需要管理依赖脚本,把控不同脚本加载的顺序;
- 前端需要按顺序加载不同类型的静态资源。
想象一下,我们的 Web 应用有这样一段内容:
<html><script src="/src/1.js"></script><script src="/src/2.js"></script><script src="/src/3.js"></script><script src="/src/4.js"></script><script src="/src/5.js"></script><script src="/src/6.js"></script></html>
每个 JavaScript 文件都需要额外的 HTTP 请求获取,并且因为依赖关系,1.js到6.js需要按顺序加载。因此,打包需求应运而生:
<html><script src="/dist/bundle.js"></script></html>
这里需要注意几点:
- 随着 HTTP/2 技术的推广,未来长远上看,浏览器像上述代码一样发送多个请求不再是性能瓶颈,但目前来看还过于乐观(更多内容参见 HTTP/2 简介);
- 并不是将所有脚本都打包在一起就是性能最优,
/dist/bundle.js的 size 一般较大,但这属于另外 “性能优化” 话题了,相关内容,我们在10 讲 “代码拆分和按需加载:缩减 bundle size,把性能做到极致”中已有涉及。
总之,打包器的需求就是前端 “刚需”,实现上述打包需要也并不简单,需要考虑:
- 如何维护不同脚本的打包顺序,保证
bundle.js的可用性; - 如何避免不同脚本、不同模块的命名冲突;
- 在打包过程中,如何确定真正需要的脚本,而不将没有用到的脚本排除在
bundle.js之外?
事实上,虽然当前 Webpack 依靠 loader 机制实现了对于不同类型资源的解析和打包,依靠插件机制实现了第三方介入编译构建的过程,但究其本质,Webpack 只是一个 “无所不能” 的打包器,实现了:
a.js + b.js + c.js. => bundle.js
的能力。
下面我们继续揭秘 Webpack 在打包过程中的奥秘。
为了简化,我们以 ESM 模块化规范举例。假设我们有:
circle.js模块求圆形面积;square.js模块求正方形面积;app.js模块作为主模块。
对应内容分别如下代码:
const PI = 3.141;export default function area(radius) {return PI * radius * radius;}export default function area(side) {return side * side;}import squareArea from './square';import circleArea from './circle';console.log('Area of square: ', squareArea(5));console.log('Area of circle', circleArea(5));
经过 Webpack 打包之后,我们用bundle.js来表示 Webpack 处理结果(精简并可读化处理后):
const modules = {'circle.js': function(exports, require) {const PI = 3.141;exports.default = function area(radius) {return PI * radius * radius;}},'square.js': function(exports, require) {exports.default = function area(side) {return side * side;}},'app.js': function(exports, require) {const squareArea = require('square.js').default;const circleArea = require('circle.js').default;console.log('Area of square: ', squareArea(5))console.log('Area of circle', circleArea(5))}}webpackBundle({modules,entry: 'app.js'});
如上代码,我们维护了modules变量,存储了不同模块信息,这个 map 中,key 为模块路径名,value 为一个被 wrapped 过的模块函数,我们先称之为module factory function,该函数形如:
function(exports, require) {}
这样做是为每个模块提供exports和require能力,同时保证了每个模块都处于一个隔离的函数作用域范围。
有了modules变量还不够,我们依赖webpackBundle方法,将所有内容整合在一起。webpackBundle方法接收modules模块信息以及一个入口脚本。代码如下:
function webpackBundle({ modules, entry }) {const moduleCache = {};const require = moduleName => {if (moduleCache[moduleName]) {return moduleCache[moduleName];}const exports = {};moduleCache[moduleName] = exports;modules[moduleName](exports, require);return moduleCache[moduleName];};require(entry);}
上述代码中需要注意:webpackBundle 方法中声明的require方法和 CommonJS 规范中的 require 是两回事,该require方法是 Webpack 自己实现的模块化解决方案。
我们通过下图来总结一下 Webpack 风格的打包器原理和流程:

Webpack 打包器原理和流程图
讲到这里,我们再扩充一下另一个打包器——Rollup 的打包原理,针对上述代码,Rollup 打包过后的产出为:
const PI = 3.141;function circle$area(radius) {return PI * radius * radius;}function square$area(side) {return side * side;}console.log('Area of square: ', square$area(5));console.log('Area of circle', circle$area(5));
如上代码,我们看到,Rollup 的原理思想与 Webpack 不同:Rollup 不会维护一个 module map,而是将所有模块拍平(flatten)放到 bundle 中,也就不存在包裹函数(module factory function)。
为了保证命名冲突不出现,Rollup 将函数和变量名进行了改写,在模块脚本circle.js和square.js中,都命名了一个area方法。经过 Rollup 打包后,area方法根据模块主体,进行了重命名。
我们将 Webpack 和 Rollup 的打包方式进行对比总结。
- Webpack 理念:
- 使用了 module map,维护项目中的依赖关系;
- 使用了包裹函数,对每个模块进行包裹;
- 使用了一个 “runtime” 方法(这里举例为
webpackBundle),最终合成 bundle 内容。
- Rollup 理念:
- 将每个模块拍平;
- 不使用包裹函数,不需要对每个模块进行包裹。
不同的理念也会造成不同的打包结果,这里我想给你留一个思考题:在 Rollup 处理理念下,如果模块出现了循环依赖,会发生什么现象呢?
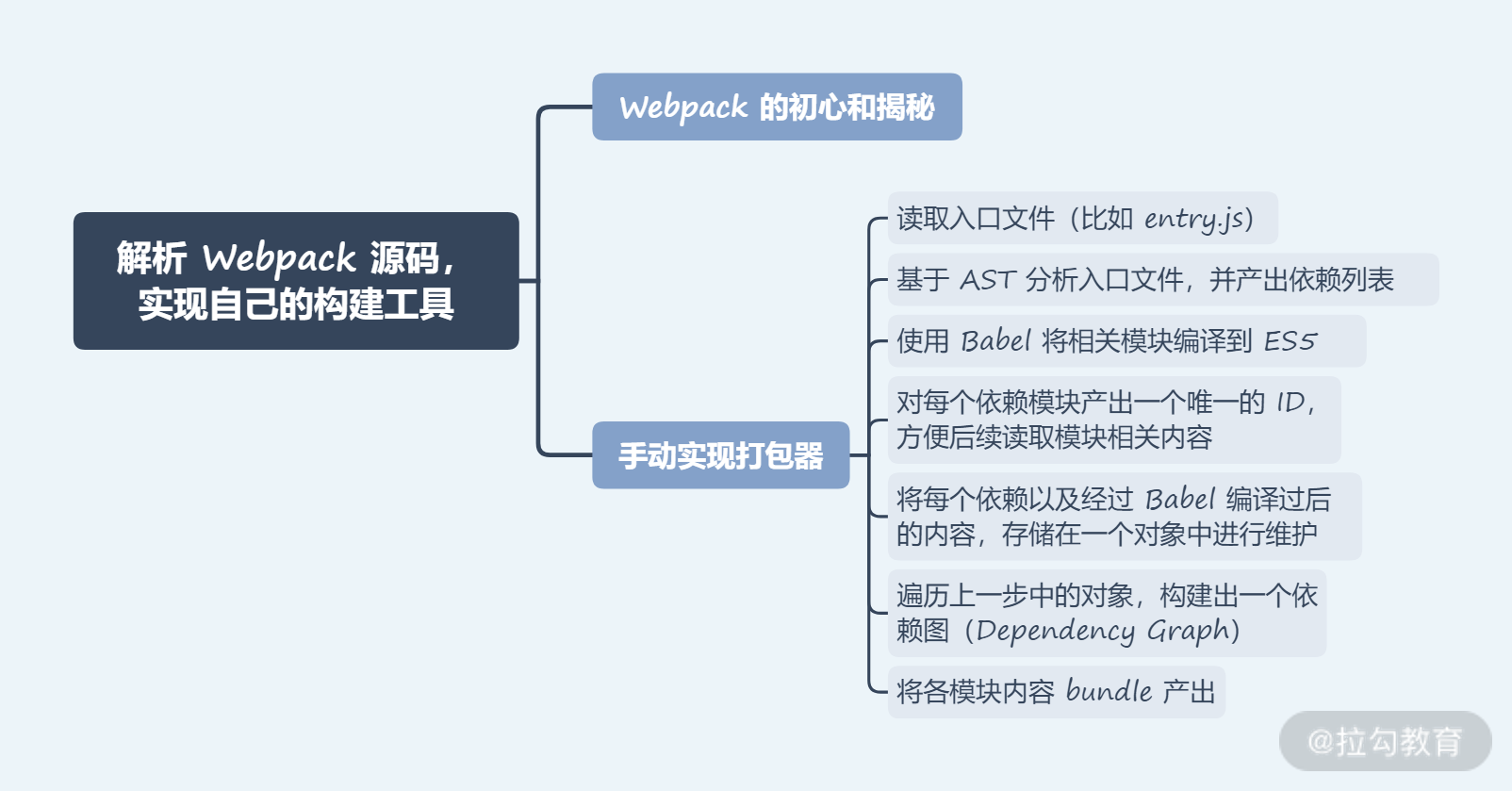
手动实现打包器
前面内容我们剖析了以 Webpak、Rollup 为代表的打包器核心原理。下面内容,我们将手动实现一个自己的简易打包器,我们的目标将会向 Webpack 打包设计对齐。核心思路如下:
- 读取入口文件(比如
entry.js); - 基于 AST 分析入口文件,并产出依赖列表;
- 使用 Babel 将相关模块编译到 ES5;
- 对每个依赖模块产出一个唯一的 ID,方便后续读取模块相关内容;
- 将每个依赖以及经过 Babel 编译过后的内容,存储在一个对象中进行维护;
- 遍历上一步中的对象,构建出一个依赖图(Dependency Graph);
- 将各模块内容 bundle 产出。
我们来一步一步实现。首先创建项目:
mkdir bundler-playground && cd $_
并启动 npm:
安装以下依赖:
@babel/parser用于分析源代码,产出 AST;@babel/traverse用于遍历 AST,找到 import 声明;@babel/core用于编译,将源代码编译为 ES5;@babel/preset-env搭配@babel/core使用;resolve用于获取依赖的绝对路径。
相关命令:
npm install --save @babel/parser @babel/traverse @babel/core @babel/preset-env resolve
做完了这些,我们开始核心逻辑的编写,创建index.js,并引入如下依赖代码:
const fs = require("fs");const path = require("path");const parser = require("@babel/parser");const traverse = require("@babel/traverse").default;const babel = require("@babel/core");const resolve = require("resolve").sync;
接着,我们维护一个全局 ID,并通过遍历 AST,访问ImportDeclaration节点,收集依赖到deps数组中,同时完成 Babel 降级编译:
let ID = 0;function createModuleInfo(filePath) {const content = fs.readFileSync(filePath, "utf-8");const ast = parser.parse(content, {sourceType: "module"});const deps = [];traverse(ast, {ImportDeclaration: ({ node }) => {deps.push(node.source.value);}});const id = ID++;const { code } = babel.transformFromAstSync(ast, null, {presets: ["@babel/preset-env"]});return {id,filePath,deps,code};}
上述代码中,相关注释已经比较明晰了。这里需要指出的是,我们采用了自增 ID的方式,如果采用随机的 GUID,会是更安全的做法。
至此,我们实现了对一个模块的分析,并产出:
- 该模块对应 ID;
- 该模块路径;
- 该模块的依赖数组;
- 该模块经过 Babel 编译后的代码。
接下来,我们生成整个项目的依赖树(Dependency Graph)。代码如下:
function createDependencyGraph(entry) {const entryInfo = createModuleInfo(entry);const graphArr = [];graphArr.push(entryInfo);for (const module of graphArr) {module.map = {};module.deps.forEach(depPath => {const baseDir = path.dirname(module.filePath);const moduleDepPath = resolve(depPath, { baseDir });const moduleInfo = createModuleInfo(moduleDepPath);graphArr.push(moduleInfo);module.map[depPath] = moduleInfo.id;});}return graphArr;}
上述代码中,我们使用一个数组类型的变量graphArr来描述整个项目的依赖树情况。最后,我们基于graphArr内容,将相关模块进行打包。
function pack(graph) {const moduleArgArr = graph.map(module => {return `${module.id}: {factory: (exports, require) => {${module.code}},map: ${JSON.stringify(module.map)}}`;});const iifeBundler = `(function(modules){const require = id => {const {factory, map} = modules[id];const localRequire = requireDeclarationName => require(map[requireDeclarationName]);const module = {exports: {}};factory(module.exports, localRequire);return module.exports;}require(0);})({${moduleArgArr.join()}})`;return iifeBundler;}
如上代码,我们创建一个对应每个模块的模板对象:
return `${module.id}: {factory: (exports, require) => {${module.code}},map: ${JSON.stringify(module.map)}}`;
在factory对应的内容中,我们包裹模块代码,并注入exports和require两个参数。同时,我们构造了一个 IIFE 风格的代码区块,用于将依赖树中的代码串联在一起。最难理解的部分在于:
const iifeBundler = `(function(modules){const require = id => {const {factory, map} = modules[id];const localRequire = requireDeclarationName => require(map[requireDeclarationName]);const module = {exports: {}};factory(module.exports, localRequire);return module.exports;}require(0);})({${moduleArgArr.join()}})`;
针对这段代码,我们进行更细致的分析。
- 使用 IIFE 的方式,来保证模块变量不会影响到全局作用域。
- 构造好的项目依赖树(Dependency Graph)数组,将会作为名为
modules的行参,传递给 IIFE。 - 我们构造了
require(id)方法,这个方法的意义在于:
- 通过
require(map[requireDeclarationName])方式,按顺序递归调用各个依赖模块; - 通过调用
factory(module.exports, localRequire)执行模块相关代码; - 该方法最终返回
module.exports对象,module.exports 最初值为空对象({exports: {}}),但在一次次调用factory()函数后,module.exports对象内容已经包含了模块对外暴露的内容了。
总结
这一讲虽然标题包含 “解析 Webpack 源码”,但我们并没有采用源码解读的方式展开,而是从打包器的设计原理入手,换一种角度进行 Webpack 源码解读,并最终动手实现了一个自己的简易打包器。
实际上,打包过程主要分为两步:依赖解析(Dependency Resolution)和代码打包(Bundling):
- 在依赖解析过程中,我们通过 AST 技术,找到每个模块的依赖模块,并组合为最终的项目依赖树。
- 在代码打包过程中,我们使用 Babel 对源代码进行编译,其中也包括了对 imports / exports(即对 ESM) 的编译。
整个过程稍微有些抽象,需要你用心体会。
主要内容总结为下图:
在实际生产环节,打包器当然功能更多,比如需要考虑:code spliting 甚至 watch mode 以及 reloading 能力等。但是不管什么样的特性和能力,只要我们理清最初心,掌握最基本的思想,任何疑问都会迎刃而解。

若有收获,就点个赞吧
0 人点赞
