数据结构与算法面试宝典 - 前微软资深软件工程师 - 拉勾教育
并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。通常会用到两种操作。
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union:将两个子集合并成同一个集合。
因此,这种数据结构称为并查集。
在工程中,并查集往往较多用于数据清理分类等操作,并且能够以 O(N) 的时间复杂度处理较大的数据量,出现在大厂的面试题中也就不奇怪了。
学完这一讲,你将会收获:
- 并查集的模板代码
- 如何利用并查集解决连通域问题
- 如何利用虚拟点与虚拟边
- 如何利用路径压缩的技巧
并查集基础
首先来看一下并查集要解决的问题,主要有两个。
- Find:查询 item 属于哪个集合
- Union:将两个集合进行合并
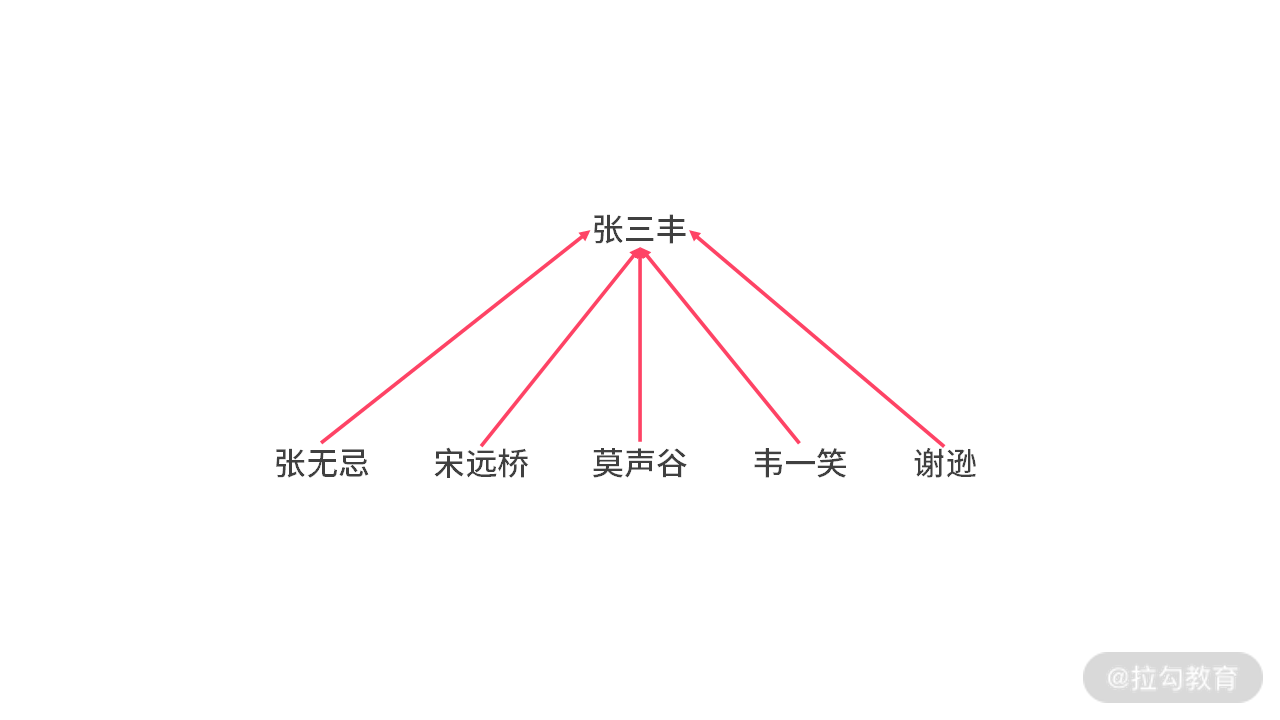
我们以一个有趣的问题展开。在《倚天屠龙记》这部武侠小说中,有很多帮派,比如:
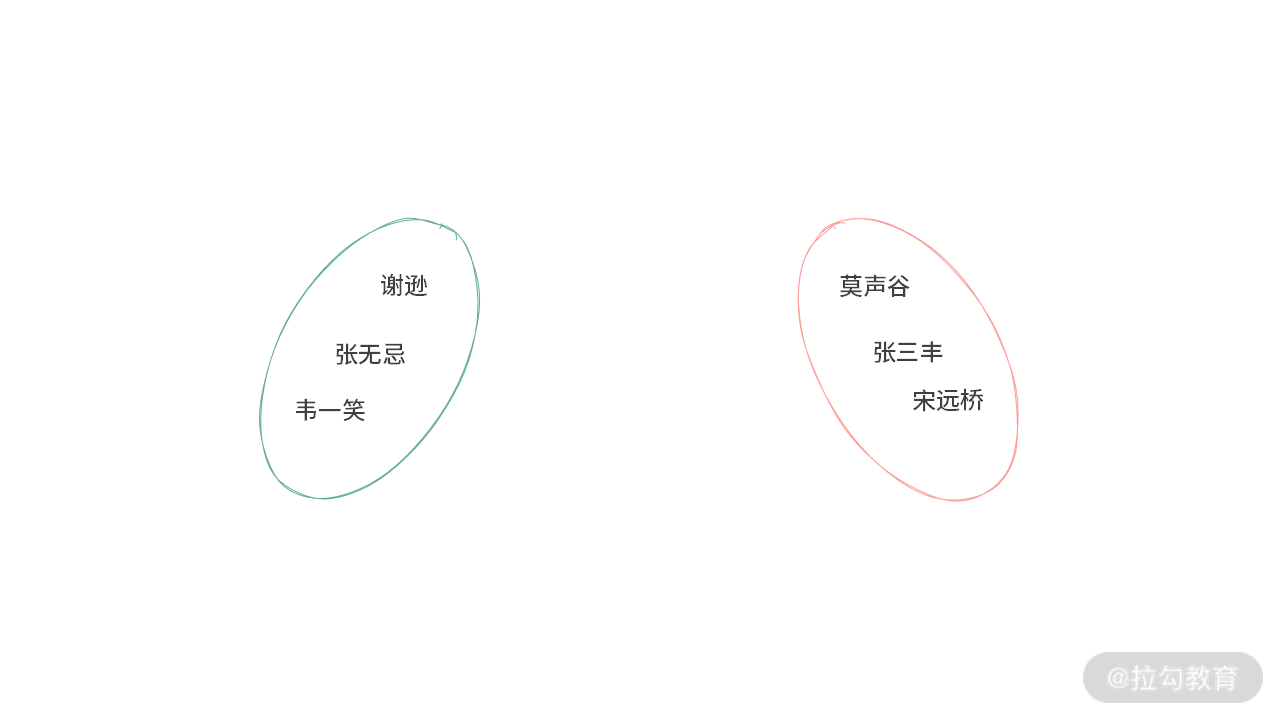
其中张无忌、谢逊、韦一笑属于明教,而张三丰、莫声谷、宋远桥属于武当派。
方法 1
我们首先设计这样一种方案:采用数组 / 哈希的方法,记录每个人所在的门派。伪代码如下:
Map<String, String> = new HashMap<>();H["谢逊"] = "明教"H["张无忌"] = "明教"H["韦一笑"] = "明教"H["莫声谷"] = "武当"H["张三丰"] = "武当"H["宋远桥"] = "武当"
那么就可以这样查询:
String Find(String person) {return H.get(person);}
至此,我们已经完成一个功能了。时间复杂度也很低,可以达到 O(1)。
那我们再看一下合并。假设某一天,张三丰要闭关修炼,决定将武当派暂时交给张无忌代管理,为了方便管理两个帮派,张无忌号令明教的人前往武当派。那么此时就需要进行一个合并 Union 操作,也就是将所有 “明教” 的人归入“武当”。代码如下:
void Union(String A, String B) {for (item : H) {if item.value == "明教":item.value = "武当"}}
但是如此一来,整个时间复杂度就上去了,Union 的时候,时间复杂度变成 O(N)。如果 Union 操作很频繁,那么这种算法就变得不可接受。
方法 2
在这里我们换一种思路,看看能不能解决 Union 复杂度过高的问题。采用江湖中通常的做法,认帮主!当帮主一样的时候,就认为我们是一个帮派的。
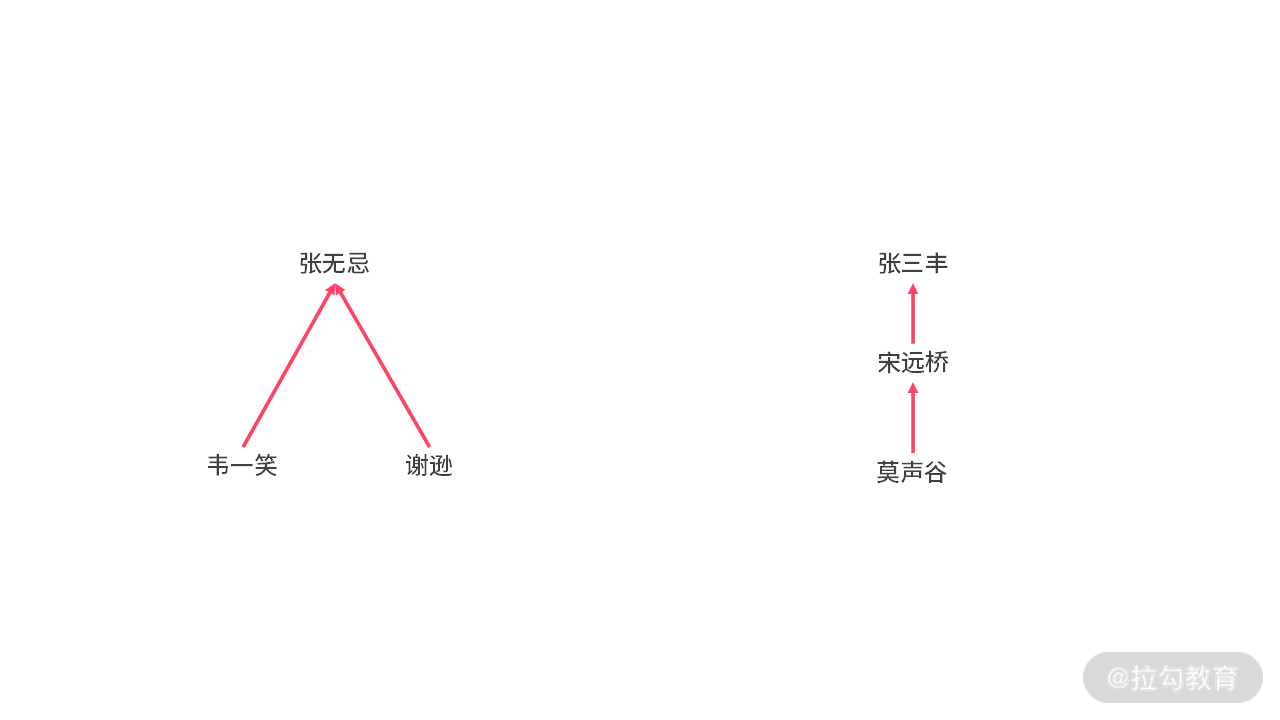
每个人都指向自己的大哥,帮主最牛,指向帮主自己。那么要进行 Union 操作的时候。直接修改指针就可以了。代码如下:
void Union(String A, String B) {String A帮主 = Find(A);String B帮主 = Find(B);H.put(A帮主, B帮主);}
在 Union 的最后,我们只需要将 A 帮主指向 B 帮主就可以了。比如,将明教与武当合并,如下图所示:
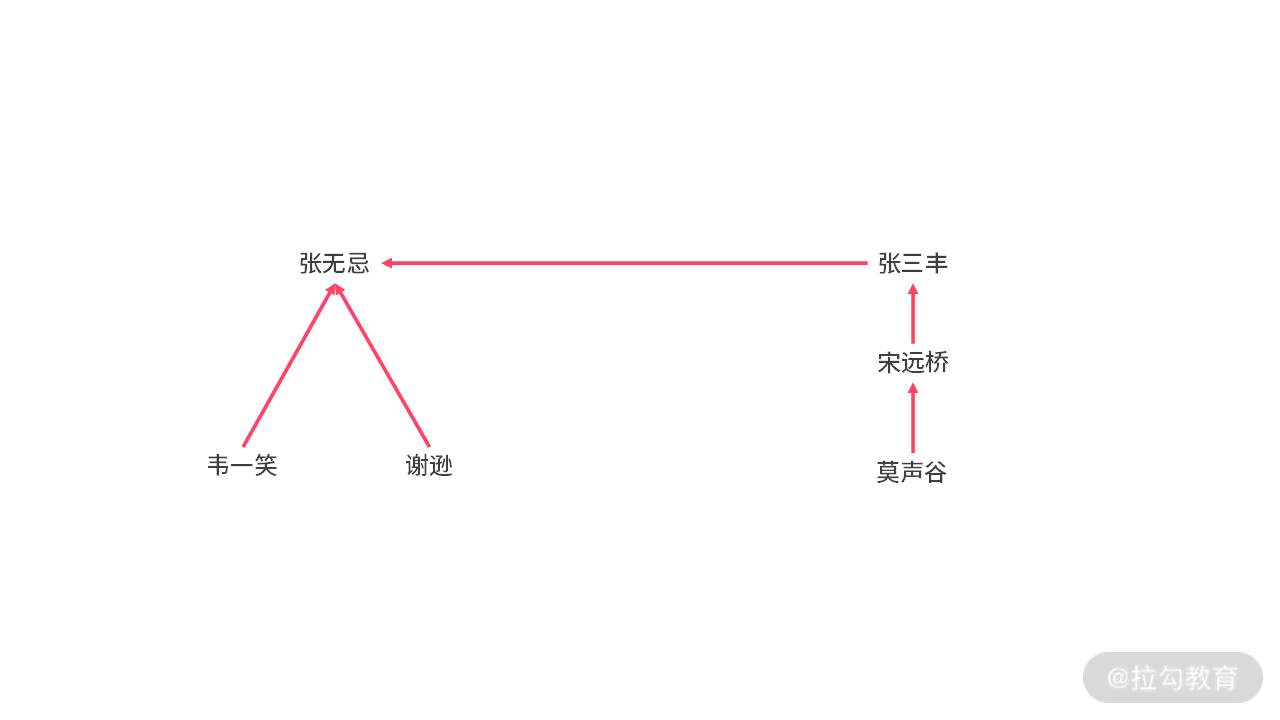
我们再看一下 Find 函数,代码如下:
String Find(String A) {while (A != H.get(A)) {A = H.get(A);}return A;}
虽然这种办法在 Union 时比较方便,但是在 Find 时却容易引入较高的复杂度。下面我们一起来看一下为什么 Find 起来比较麻烦:

在这种情况下,Find 查询时,总是会查询很多次 O(N)。也就是说,Union 的时间复杂度较低的时候,Find 的时间复杂度又上升了。
那么,有没有更好一点的办法呢?能让 Union 和 Find 的时间复杂度都低一点。
路径压缩
办法还是有的,就叫路径压缩,我们发现,在方法 2 中,如果能将层级结构 “拍扁”,那么 Find 和 Union 的时间复杂度都会特别低。
因此,我们还需要在 Find 函数里面做一些手脚。当我们找到一帮主之后,就把这条路径上的所有人的大哥都改成帮主。代码如下(解析在注释里):
String Find(String A) {String start = A;while (A != H.get(A)) {A = H.get(A);}while (H.get(start) != A) {String next = H.get(start);H.put(start, A);start = next;}return A;}
再看这个例子:经过合并,成立糖葫芦帮之后。如下图所示:
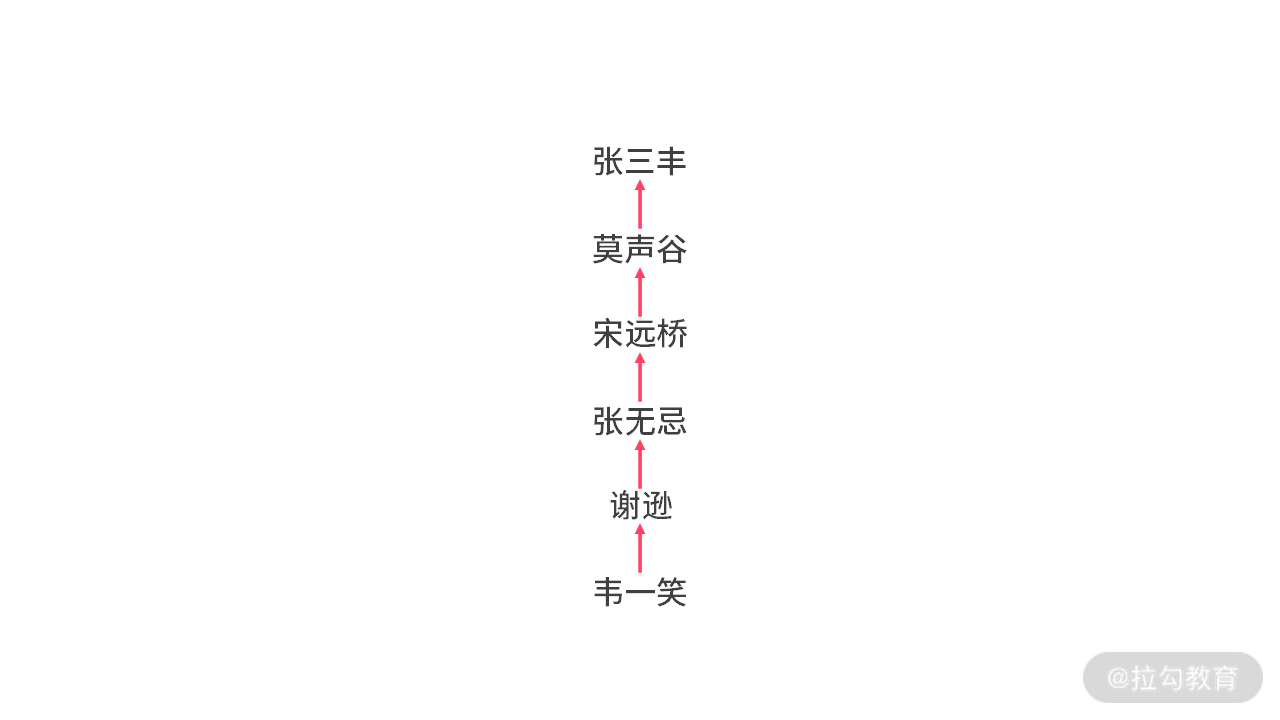
如果一旦执行 Find(“韦一笑”),那么糖葫芦帮派就会变成大饼帮派。
所有人的帮主都会指向张三丰。也就是说,除了第一次 Find 复杂度为 O(N),后面的查询复杂度都是 O(1)。至此,我们已经讲清楚带路径压缩的并查集的原理。接下来我们看代码如何实现。
并查集模板
前面使用的都是比较形式化的语言和伪代码。接下来我们看一下具体如何实现并查集。这里我以整数替换前面的人名,操作起来更加方便。
初始化
首先假设有 N 个整数,范围为 [0, N)。那么记录每个人的信息,就需要一个长度为 N 的数组。
在初始化的时候,每个人都是自成一派。
for (int i = 0; i < N; i++) {F[i] = i;}
查询
根据前面所讲,可以得到查询操作的代码如下(解析在注释里):
int Find(int x) {int b = x;while (F[x] != x) {x = F[x];}while (F[b] != x) {int p = F[b];F[b] = x;b = p;}return x;}
合并
完成查询操作,我们就要把两个集合进行合并,代码如下:
int Union(int x, int y) {F[find(x)] = find(y);}
这两个函数的代码还是显得有点长,并且不太容易记。我在刷题和面试时,更喜欢,或者说常用一份精简过的代码。下面我将分享给你。
两行代码
这里我整理了:两行并查集核心代码模板(用 C 语言实现,方便记忆):
int F[N];int Find(int x) {return x == F[x] ? x : F[x] = Find(F[x]);}void Union(int x, int y) {F[find(x)] = find(y);}
注:根据不同的语言,你可能需要修改不同的 Find 函数。
两个功能
当真正使用并查集的时候,面试官可能会问你两个问题:
- 有多少个集合?
- 每个集合里面有多少个元素?
下面我们依次回答这两个问题。
1. 集合数目:在执行 Find 的时候,集合个数不可能有变化。如果发生变化,只可能发生在两个集合合并的时候。
再来具体看一下初始化和合并操作。
- 初始化:在并查集开始初始化的时候,一共有 N 个元素,那么一开始集合个数为 N。
- 合并:合并的时候,需要查看合并的两个集合是不是同一个,如果不是,那么集合个数减 1。
2. 每个集合中元素的个数:在执行 Find 的时候,每个集合中元素的个数不可能发生变化。如果发生变化,只可能是两个集合合并的时候。
下面我们具体看一下初始化和合并操作。
- 初始化:在并查集开始初始化的时候,每个元素都属于独立的元素,那么一开始每个集合里面的个数都是 1。如果我们用 Count[] 数组记录每个元素的个数,那么一开始初始化 Count[] = 1。
- 合并:当 A 集合要合并到 B 集合里面的时候,可以认为 A 集合里面所有的元素都变成 B 集合里面的元素。当然是 B 集合里面的个数增加了,那么 Count[Find(B)] + = Count[Find(A)]。
注意:在记录集合中元素个数的时候,只有根结点的信息是准确的。当查询结点 i 所属集合的信息时,只能使用 Count[Find(i)],而不能使用 Count[i]。因为如果要保证每个点 Count[i] 的信息都是准确的,那么每次合并的时候,整个集合中的元素的信息都要更新,这样时间复杂度就很高了,Union 操作的时间复杂度就不再是 O(lgN),而变成 O(N)。
为了方便你刷题和应对面试,这里我给出了并查集的完整代码,你可以作为参考。
完整 Java 代码
int[] F = null;int count = 0;int[] Cnt = null;void Init(int n) {F = new int[n];Cnt = new int[n];for (int i = 0; i < n; i++) {F[i] = i;Cnt[i] = 1;}count = n;}int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}void Union(int x, int y) {int xpar = Find(x);int ypar = Find(y);if (xpar != ypar) {F[xpar] = ypar;Cnt[ypar] += Cnt[xpar];count--;}}int Size(int i) {return Cnt[Find(i)];}
注:这里是以整数和数组为例。如果关键字是 String,也可以使用哈希表将字符串映射到整数再进行并查集的操作。
复杂度分析:并查集的初始化时间复杂度为 O(N),而 Find 和 Union 的操作时间复杂度都是 O(lgN),其中 N 为点的总数。这里只使用了长度为 N 的数组,所以空间复杂度为 O(2N)。
例 1:最小生成树
【题目】给定一个图的点集,边集和权重,返回构建最小生成树的代价。
输入:N = 2, conn = [[1, 2, 37], [2, 1, 17], [1, 2, 68]]
输出:17
解释:图中只有两个点 [1, 2],当然是选择最小连接 [2, 1, 17]
【分析】利用并查集 + 贪心算法,可以生成一个图的最小生成树,这种方法也被称为 Kruskal 算法。并查集可以用来将两个点进行 Union,不过在并查集的 Union 代码中,并没有权重这一项,那我们该怎么办呢?
在 Union 的时候,就直接根据边的权重来排序,然后再处理,这不就是经典的 Kruskal 算法。
这里我们可以讲一下最小生成树的思路:
- 首先初始化并查集
- 将边集按照权重排序
- 利用边集将不同的两点进行 Union
- 将不同的集合进行 Union 时需要加上新加入的边的代价(即边的权重)。
【代码】这里我们可以写出经典的 Kruskal 算法,代码如下(解析在注释里):
class Solution {private long cost = 0;private int[] F = null;private void Init(int n) {F = new int[n+1];for (int i = 0; i <= n; i++) {F[i] = i;}cost = 0;}private int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}private void Union(int x, int y, int pay) {if (Find(x) != Find(y)) cost += pay;F[Find(x)] = Find(y);}public long Kruskal(int n, int m, int[][] conn) {Init(n);Arrays.sort(conn, 0, m, new Comparator<int[]>() {public int compare(int[] a, int[] b) {return a[2] - b[2];}});for (int i = 0; i < m; i++) {Union(conn[i][0], conn[i][1], conn[i][2]);}return cost;}}
复杂度分析:程序主要分为两块,一部分为边集 E 的排序,复杂度为 O(ElgE);另外一部分为每条边的 Union 操作,复杂度为 O(ElgN)。在大部分时候,边的数目往往比点的数目要多,因此时间复杂度为 O(ElgE)。
【小结】本质上 Kruskal 算法就是并查集算法 + 贪心算法。使用 Kruskal 算法有一个很重要的前提——题目是假设输入边能将所有的点加到一个连通域中,也就是保证最后必然能够生成一棵树。
这里给你留一道练习题,你可以利用它检验和巩固自己的学习成果。
练习题 1:给定点集和边集,求最小生成树的代价,如果最后不能生成最小生成树,那么返回 MAX_INT。
接下来我们一起看一下关于并查集的其他考察形式与考点。
连通域的数目
我们可以把最小生成树当成一个连通域,只不过需要用最小的代价来生成这么一个连通域。除了求解最小生成树,并查集的另外一个常见的用途是求解连通域的数目。在微软和 EMC 的面试中都出现过,但是可能会通过两种方式给出图的结构,比如:
- 点集和边集,告诉你有哪些点,以及哪些边;
- 矩阵表示。
不管是通过哪一种图表示,利用并查集解决连通域数目的步骤都是以下两步:
- 用 F[] 数组和点集进行初始化
- 利用边集进行 Union
最后的集合数目就是连通域的数目。
利用本讲前面学过的模板和思路,相信你已经可以解决面试中的高频出现的算法题了。
例 2:帮派的数目
【题目】江湖上有 N 个人,编号从 [1 ~ N],现在只能告诉你,其中两人是一个帮派的,请你输出帮派的数目。
输入:N = 4, [[1, 2], [2,3]]
输出:2
解释:一共有 4 个人,[1,2, 3] 成为一个帮派,[4] 独自成为一个帮派,那么一共有 2 个帮派。
【分析】在一开始,你可以认为他们都是独自成为一个帮派,当告诉你每两个人是一个帮派时,相当于要把这两个人合并到一个集合中。问题是一共有多少个帮派,显然这就是一个非常标准的并查集的问题了。我们可以直接套用前面所讲的并查集的模板进行求解。
【代码】直接利用并查集的代码模板,代码如下(解析在注释里):
int count = 0;int[] F = null;void Init(int n) {F = new int[n + 1];for (int i = 0; i <= n; i++) {F[i] = i;}count = n;}int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}void Union(int x, int y) {if (Find(x) != Find(y))count--;F[Find(x)] = Find(y);}int findGangNumber(int n, int[][] conn) {Init(n);int m = conn.length;for (int i = 0; i < m; i++) {Union(conn[i][0], conn[i][1]);}return count;}
代码:Java/C++/Python
复杂度分析:整个算法的时间复杂度为 O(mlogN) ,这里 n 表示人的数目,而 m 表示两两成对的输入数目。
【小结】在这里我们直接利用并查集的模板搞定了一道题目。
延伸:如果将这里的每个点都当成一个 “图” 结构中的一个点,将两两成对的输入当成 “图” 结构中的边。那么问题就变成了求解图的连通域个数。
下面我们一起来看一下这个曾经在微软的电面中出现的 2 道题目。
练习题 2:给定一个黑白图像,其中白色像素用 ‘1’ 表示,黑色像素用 ‘0’ 表示。如果把上下左右相邻的白色像素看成一个连通域,给定一幅图(用矩阵表示),请问图中有几个连通域。
输入:A = [[‘1’, ‘1’, ‘0’], [‘0’, ‘1’, ‘0’]]
输出:1
解释:图中所有的 ‘1’ 都是连在一起的,所以只有一个连通域。
练习题 3:给定一个图(不是图像)的矩阵,A[i][j] = 1 表示点 i 与点 j 相连,求这个图里面连通域的数目。
输入:A = [[1,0,0],[0,1,0],[0,0,1]]
输出:3
解释:[0, 1, 2] 三个点中,每个点都不与其他点相连,所以连通域有 3 个。
例 3: 换工位
【题目】因为要实施结对编程,想让两个员工的工位挨在一起:要求 [0,1] 员工坐在一起,[2, 3] 员工坐在一起,以此类推。不过挨着具体坐的位置并不重要,只要能挨在一起就可以了。比如 [0, 1, 3, 2] 与 [2, 3, 1, 0] 都是满足要求的。现在给定一个数组 A[],求换工位的最少次数,尽量让两个员工坐在一起。(给定 N 个员工,他们的编号总是 [0~N-1] ,并且 N 总是偶数)。
输入:A[] = [0, 3, 2, 1]
输出:1
解释:只需要换 1 次就可以了,比如,将 0 号员工与 2 号员工交换。
【分析】初看这道题的时候,没有什么思路,那么我们进行一下模拟,看看能不能发现什么规律。
1. 模拟
当 N = 2 时,无论是 [0, 1] 还是 [1, 0] 这两种排列都满足要求,因为我们总是想让 [0, 1] 这两个员工坐在一起,而只有两个员工时,他们总是挨在一起的。假设结对成功的两个人坐在一起的时候,就像做在链条上的环一样。
由于 N 必须为偶数,所以接下来我们看一下 N = 4 时的情况。比如 A = [0, 3, 2, 1],此时 4 个人都没有结对成功,相当于两个环还扣一起。
这时我们只需要交换 0, 2 形成 [2,3,0,1],如果按配对划分,那就是 [2, 3] 和 [0, 1]。结对成功之后,这两个环就可以拆开了。操作如下图所示:
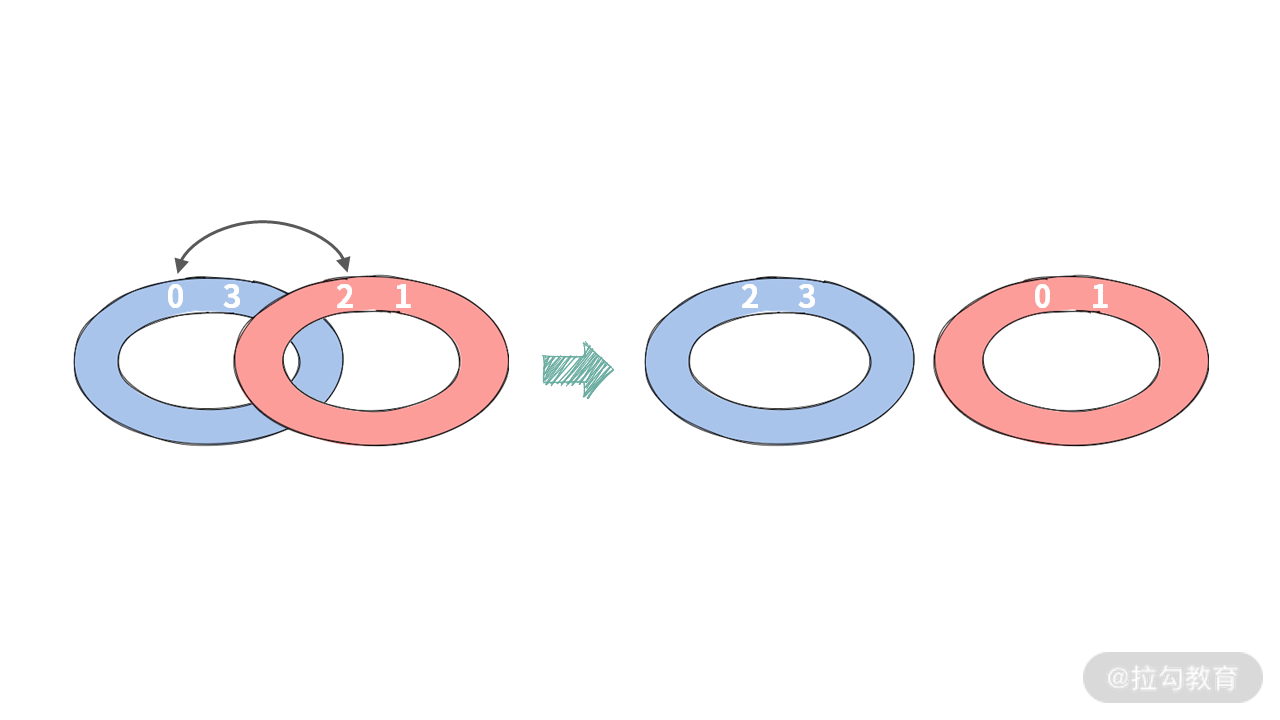
通过这个示例,还可以发现,如果不经过交换,虽然 [3, 2] 这两个员工已经坐在一起了,但是不操作,那么 0 号员工和 1 号员工是无法结对编程的。
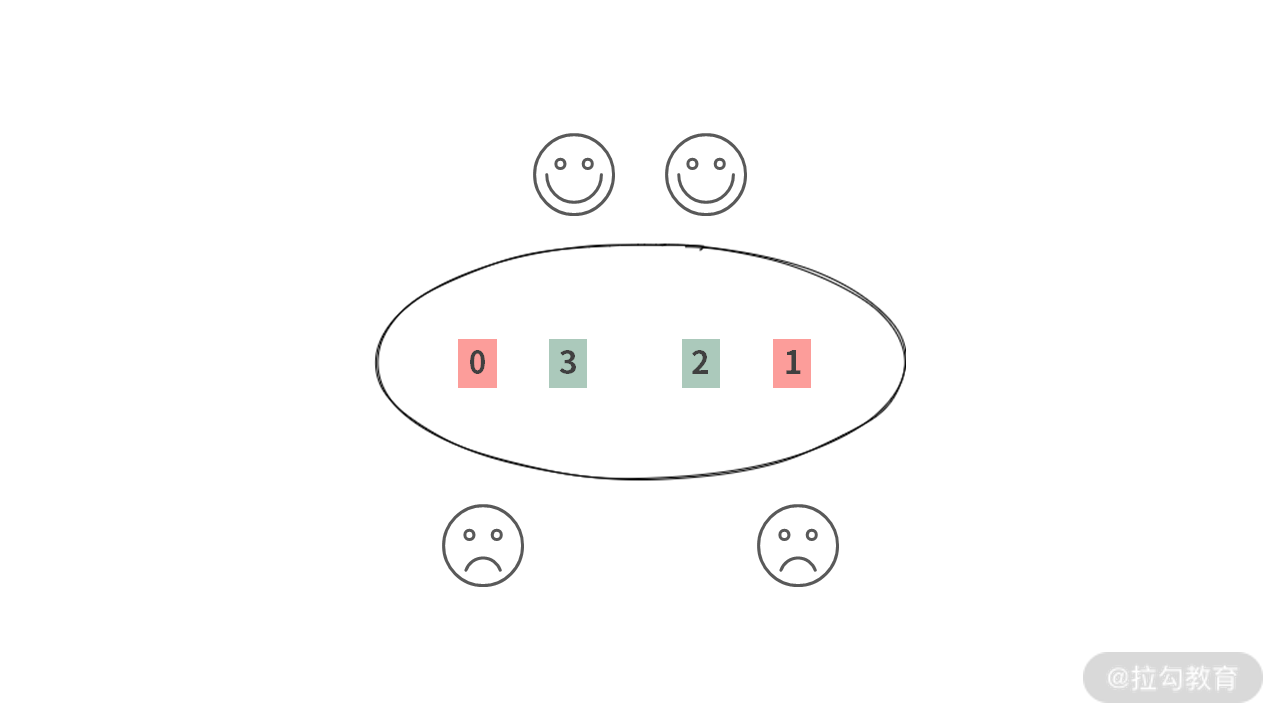
因此,我们可以得到结论 1:结对的时候,数组中只能偶数下标与奇数下标配比。比如 A[0] 与 A[1] 结对。不能奇数下标与偶数下标结对,比如 A[1] 与 A[2] 结对。
接下来我们再看一下 N = 6 的情况, 比如 A = [0, 2, 3, 5, 1, 4]:我们在执行交换的时候,可以这样操作:
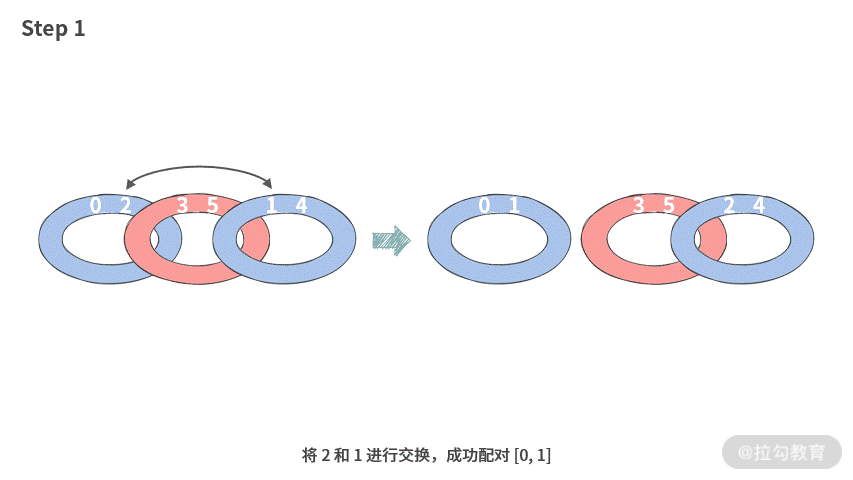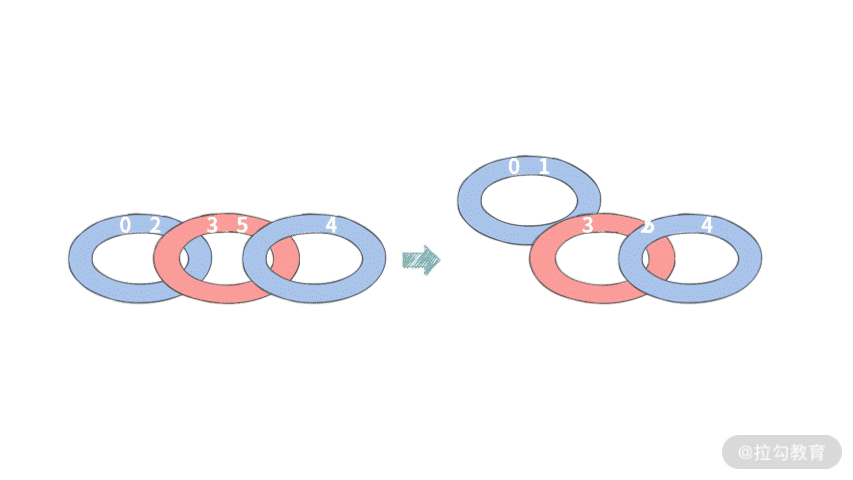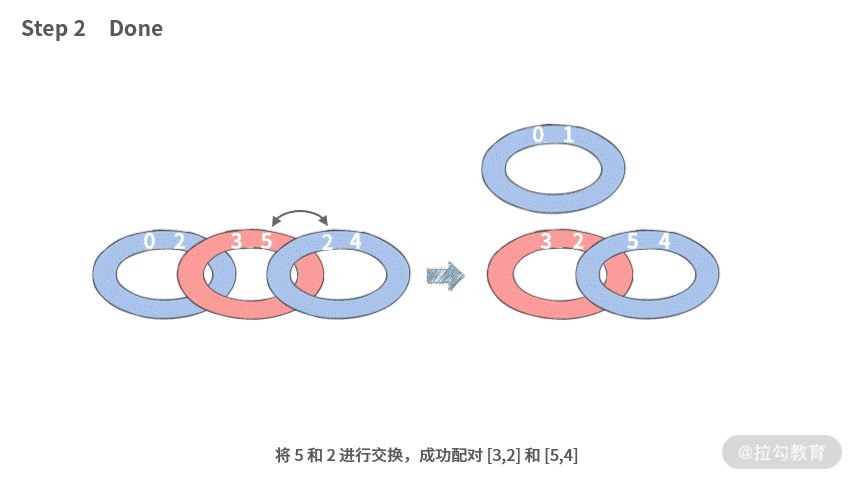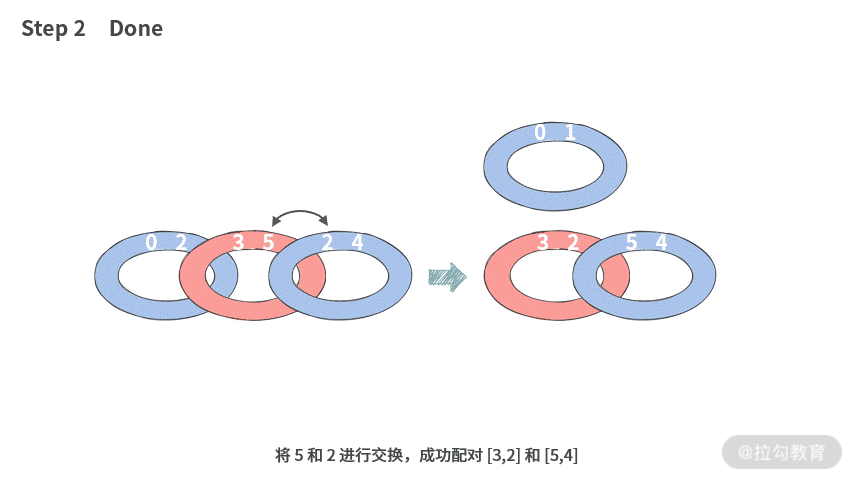
所以成功切分出三个配对集合 [0, 1], [3, 2], [5, 4],需要 2 步。
2. 规律
通过前面的模拟,我们还需要进一步的总结规律。将里面没有成功结对的序列看成一条锁链。并且拆分出结对成功的两个元素,独立位于一个环中,并不与别人相扣在一起。
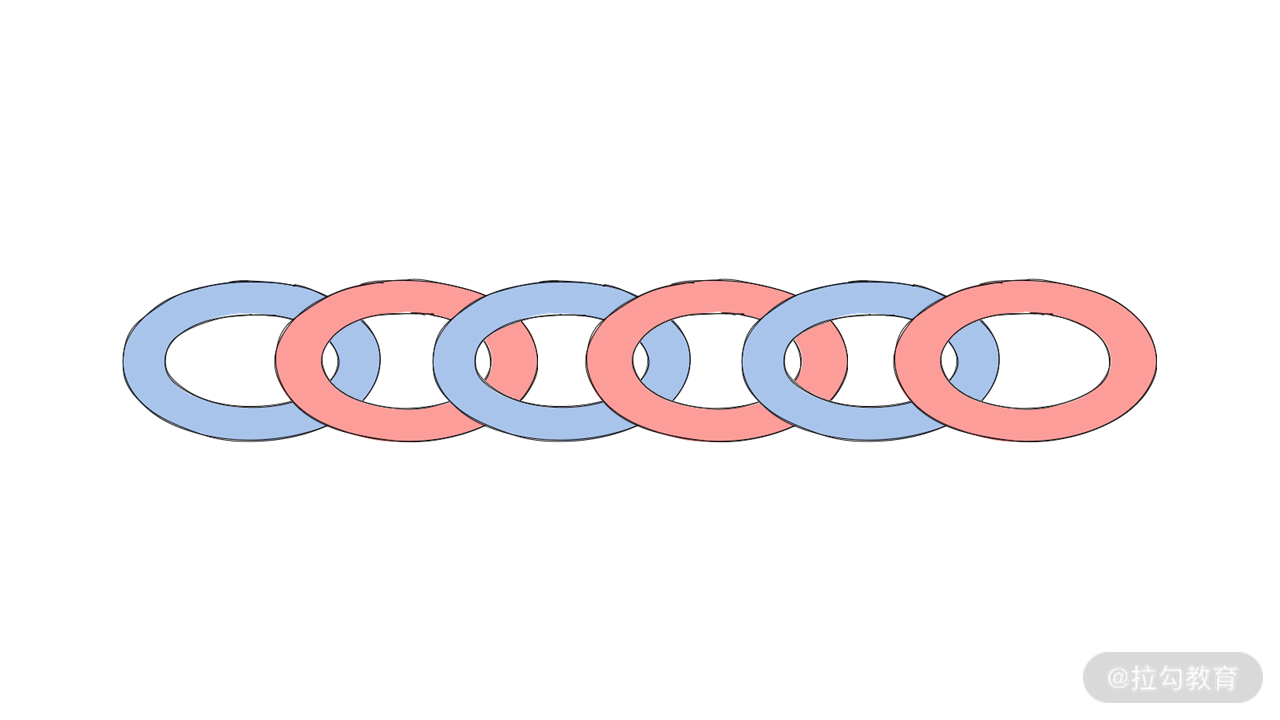
每 1 次操作,交换两个元素,就相当于从锁链中成功拆一个环下来。
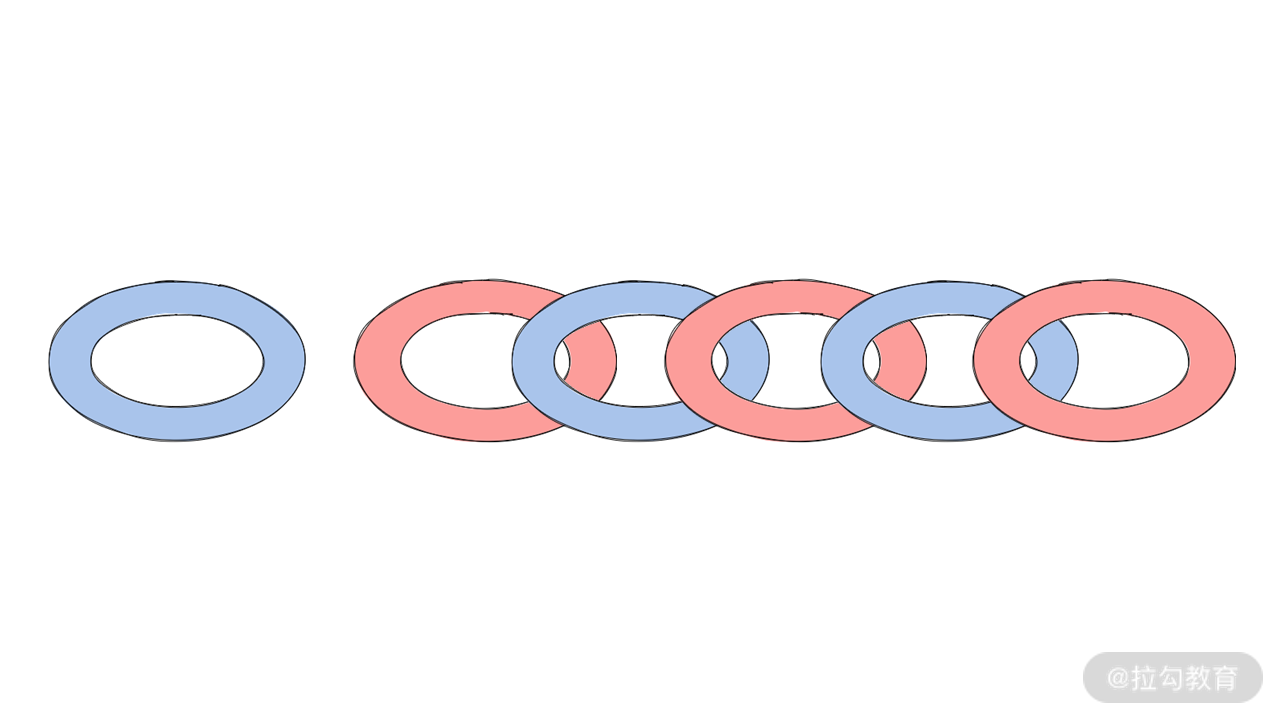
那么,我们可以得到结论 2:有 2x 个元素,也就是 x 个环的锁链,就需要 x-1 次操作。
至此,我们就将题目成功变成了:给定一个数组,需要找到里面有几条锁链。比如给定数组 A = [6, 4, 5, 2, 3, 7, 0, 1]。
此时应该可以分出两条锁链来,如下图所示:
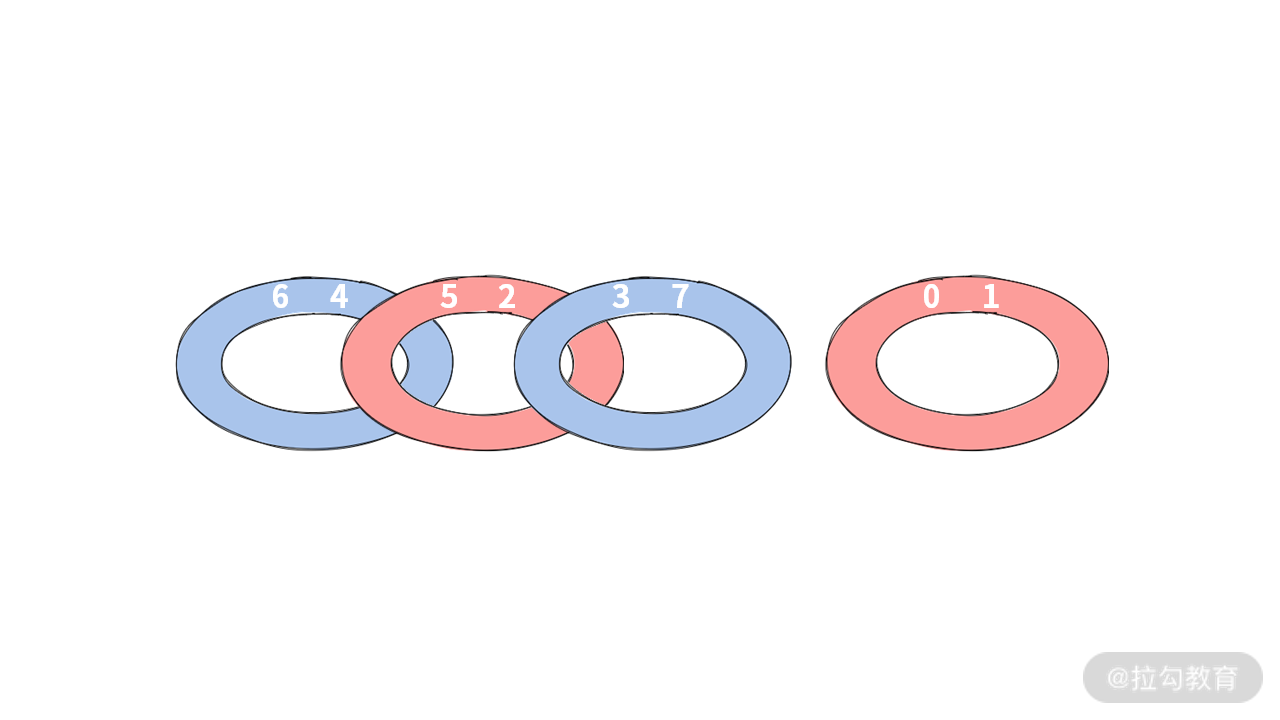
我们再看每个锁链中的环的数目就可以得到最少操作次数。比如这里的 A[] 数组有 2 条锁链,需要的操作次数是 (3 - 1) + (1-1) = 2。也就是最少操作 2 次。
那么现在问题的关键就是,如何才能通过数组得到锁链呢?这里我们还发现一个有趣的结论 3:本就结对的两个员工必然在同一个链条中。比如 6 和 5 在没有结对的情况下,也必然在同一条锁链中。
3. 匹配
如果将锁链当成集合,就可以对应到并查集了。这里再细化一下:
- 通过结论 3,我们应该将一个偶数 x 以及和它配对的数 x+1 先放到同一个集合中;
- 偶数下标 A[i],需要与 A[i+1] 进行 Union,完成放到同一个锁链的操作。
虽然最后我们可以通过去数锁链中环的个数,再通过结论 2 得到答案。但是如果你能想到拆环的次数,实际上就是不同集合 Union 的次数。那么求解的时候,只需要在并查集模板的基础上对 Union 稍做更改就可以了。
4. 边界
注意处理空数组,注意结对的时候,要满足结论 1。
【画图】接下来我们画图演示一下使用并查集的过程。这里我们以数组 A = [6, 4, 5, 2, 3, 7, 0, 1] 为例。
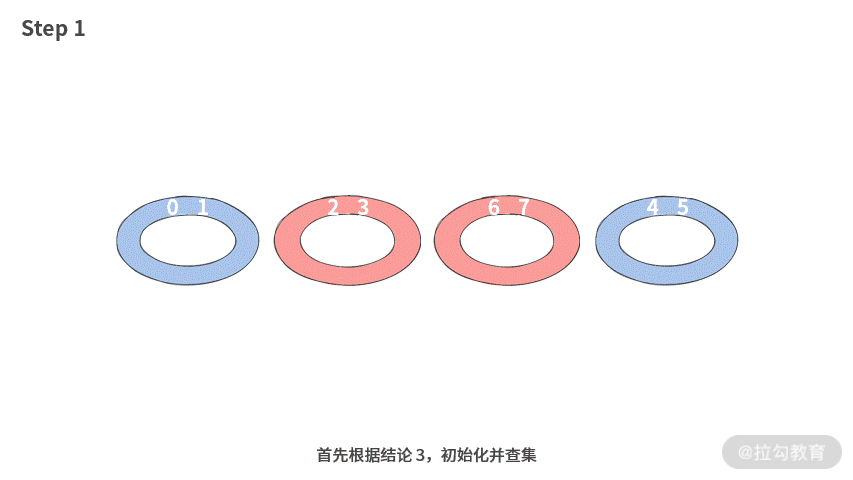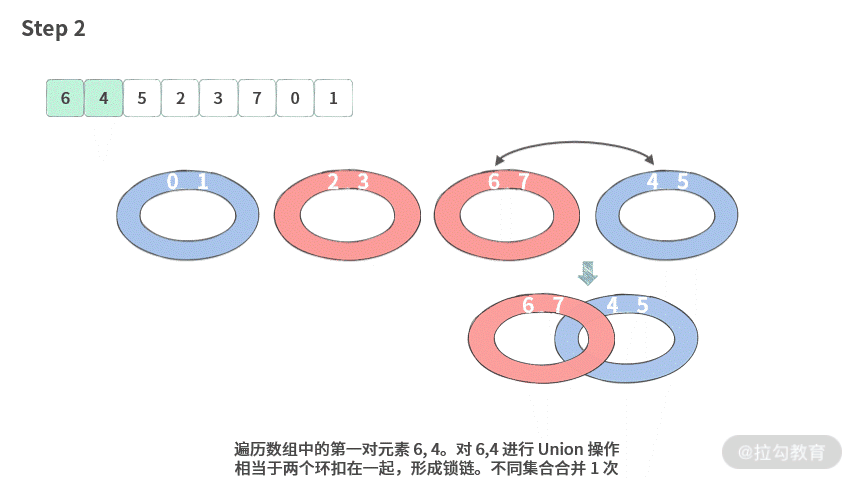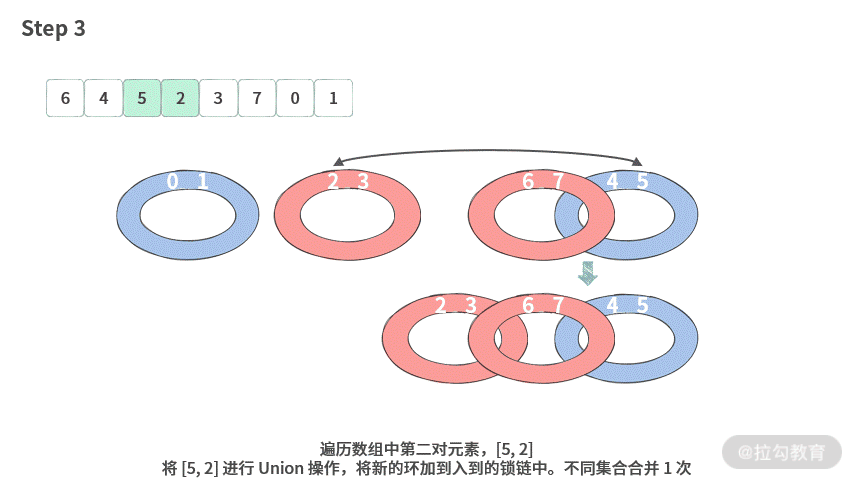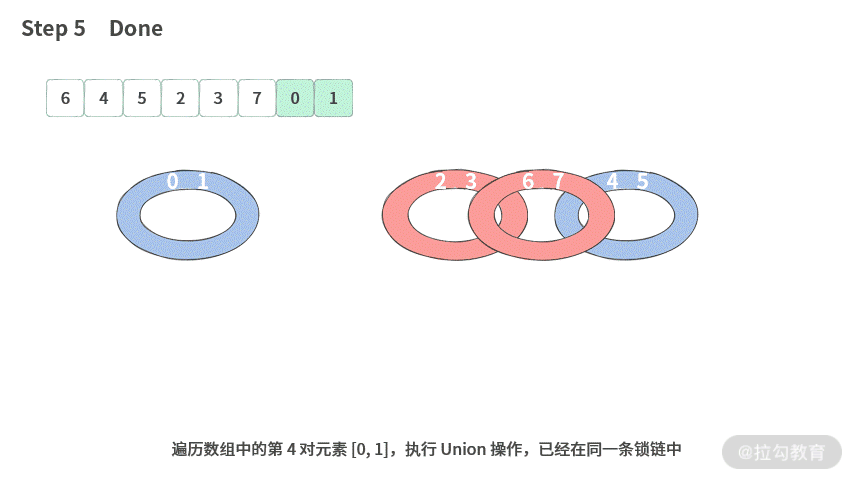
我们发现,不同集合的合并次数一共为 2 次,所以只需要 2 次操作就可以完成结对编程的要求。
【代码】接下来我们可以写一下代码了(解析在注释里):
int[] F = null;int unionCount = 0;void Init(int n) {F = new int[n];for (int i = 0; i < n; i++) {F[i] = i - (i & 0x01);}}int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}void Union(int x, int y) {if (Find(x) != Find(y)) {unionCount++;}F[Find(x)] = Find(y);}int minSwapsCouples(int[] A) {final int N = A == null ? 0 : A.length;Init(N);for (int i = 0; i < N; i += 2) {Union(A[i], A[i + 1]);}return unionCount;}
复杂度分析:一共有 N/2 对元素要合并,每次合并的时间复杂度为 O(lgN)。所以时间复杂度为 O(NlgN)。
【小结】在这里,我们学习了将锁链处理成一个连通域,并且巧妙地通过求解合并次数解决了最小操作次数。
我认为这道题目最核心的考点是分析出结论 2:有 2x 个元素,也就是 x 个环的锁链,就需要 x-1 次操作。
一旦得到了每条锁链中的操作次数,然后利用并查集的模板,这道题目就解决了。我再给你留道练习题,希望你可以尝试做一下。
练习题 4:给定一个单词数组,如果两个单词相等,或者说其中一个单词 A 经过一次字符交换,可以得到单词 B,那么我们说单词 {A, B} 是同构的。请问单词数组中,一共有多少组这样的同构集合?
输入:{“AB”, “BA”, “AB”, “BC”, “CD”}
输出:3
解释:一共有三组同构集合,{“AB”, “BA”, “AB”}, {“BC”}, {“CD”}
接下来我们讲解并查集的进一步运用。
虚拟点与虚拟边
在求解连通域的过程中,我们经常利用现有的点与现有的边进行并查集的初始化与合并。
但是在有些题目中,需要加入一些虚拟的边和虚拟的点到并查集的点集与边集中。通过这种方式可以极大地方便我们使用并查集。
例 4: 替换字母
【题目】给你一个矩阵 A,里面只包含字母 ‘O’ 和’X’,如果一个’O’ 上下左右四周都被’X’ 包围,那么这个’O’ 会被替换成’X’。请你写程序处理一下这个过程。

解释:由于中心的’O’ 四周都被包围,所以需要被换成’X’,而第 A[0][0] = ‘O’ 靠着边,所以不能被替换。
【分析】这道题目曾经在微软的面试中出现过。看起来就是一个连通域的问题,所以可以使用并查集来处理。思路如下:
- 首先用并查集标记所有’O’ 的连通域;
- 将所有在边上的’O’ 的 “帮主” 放到 set 集合中;
- 遍历每个’O’ 的 “帮主”,看看是不是在 set 集合中,如果在,那么这个’O’ 不能替换。
可以发现,有一步操作可以优化:将所有在边上的’O’ 的 “帮主” 放到 set 集合中,有两种办法:
- 随便选择边上的一个点,作为所有边上点的 “帮主”;
- 选一个虚拟的点,作为所有边上的点的 “帮主”。
你可以根据自己的喜好任选其一,这里我用第 2 种 “虚拟点” 的办法。下面就可以直接套用模板了。
【代码】采用虚拟点的并查集的代码实现如下(解析在注释里):
int[][] dir = {{0, 1}, {1, 0}};int[] F = null;void Init(int n) {F = new int[n];for (int i = 0; i < n; i++) {F[i] = i;}}int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}void Union(int x, int y) { F[Find(x)] = Find(y); }void solve(char[][] A) {if (A == null || A[0] == null) {return;}final int R = A.length;final int C = A[0].length;Init(R * C + 1);final int vNode = R * C;for (int r = 0; r < R; r++) {for (int c = 0; c < C; c++) {if (A[r][c] == 'O') {if (r == 0 || r == R - 1 || c == 0 || c == C - 1) {Union(r * C + c, vNode);}for (int d = 0; d < 2; d++) {final int nr = r + dir[d][0];final int nc = c + dir[d][1];if (!(nr < 0 || nr >= R || nc < 0 || nc >= C)) {if (A[nr][nc] == 'O') {Union(r * C + c, nr * C + nc);}}}}}}for (int r = 0; r < R; r++) {for (int c = 0; c < C; c++) {if (A[r][c] == 'O') {if (Find(r * C + c) != Find(vNode)) {A[r][c] = 'X';}}}}}
复杂度分析:由于每个点只遍历两遍。所有点的数目为 N,所以时间复杂度为 O(NlgN),此外,每个点都记录了所在集合,所以空间复杂度为 O(N)。
【小结】在这里我们学习了一种新的处理技巧,那就是利用并查集 + 虚拟结点,将原本不在一起的结点,统一放到了一个虚拟集合中。
所以解决这道题目的考点我们可以总结如下:
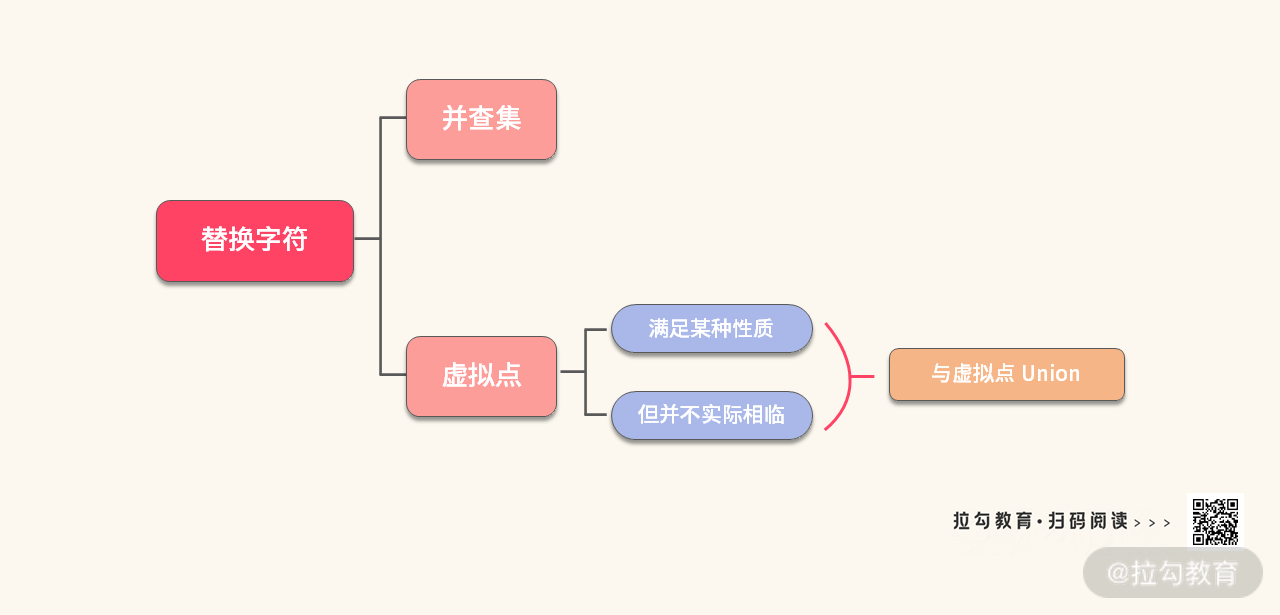
在面试中,如果你有了并查集的模板,再加上虚拟点的思路,那么快速解决这类问题就轻而易举了。
例 5:上网的最小费用
【题目】园区里面有很多大楼,编号从 1~N。第 i 大楼可以自己花钱买路由器上网,费用为 cost[i-1],也可以从别的大楼拉一根网线来上网,比如大楼 a 和大楼 b 之间拉网线的费用为 c,表示为一条边 [a, b, c]。输入为每个大楼自己买路由器和拉网线的费用,请问,让所有大楼都能够上网的最小费用是多少?上网具有联通性,只要与能够上网的大楼连通,即可上网。
输入:cost = [1, 2, 3], edges = [[1,2,100], [2,3,3]]
输出:6
解释:最优方案是 1 号大楼买路由器 cost[0] = 1,2 号楼买路由器 cost[1] = 2,然后和 3 号楼之间可拉一根网线,费用为 3,所以一共花费 6 元。如图(红色部分标记为费用 ):
【分析】这是一道头条面试中出现过的题目。首先如果不考虑自己买路由器的情况,只依赖给定的边集构建这个图,且要求最小费用,这道题目就和最小生成树一模一样了。可是,这里与最小生成树不一样的地方在于:第 i 大楼可以自己花钱买路由器上网,费用为 cost[i-1]。
在最小生成树里面,可是没有说 “自己买路由” 这个操作。那怎么办?我们有什么方法可以转化一下吗?
可以采用加入虚拟点的方法。首先假设有一个结点 0 已经自己买了路由器,花费为 0 元。而其他结点要自己买路由器,本质等价于与结点 0 进行联通。只不过这个网线的费用,就是你自己买路由器的费用。
比如,给定 3 个点,分别自己买路由器的费用为 [1, 2, 3]。那么我们可以把图变成下图这样子:
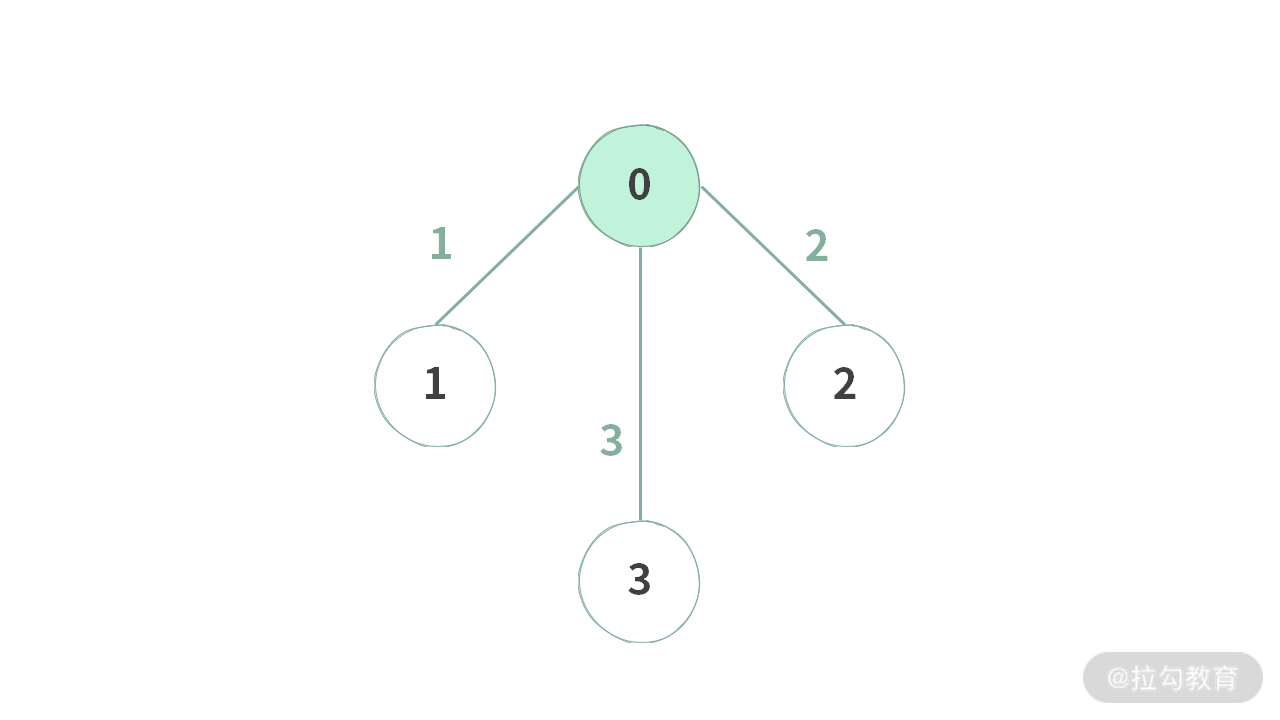
也就是说,我们添加了一个虚拟结点 0,然后也添加了 3 条虚拟边。这里虚拟的元素我们都用绿色表示。
如果最后生成的连通图里面把 0~3 这四个点都包含进去,那么所有的大楼肯定都是可以上网的。此时最小代价问题就可以用最小生成树的方法来解决了。
【代码】到这里,相信你已经知道可以怎么写代码了(解析在注释里):
class Solution {private int[] F = null;private int totalCost = 0;private void Init(int n) {F = new int[n + 1];for (int i = 0; i <= n; i++) {F[i] = i;}totalCost = 0;}private int Find(int x) {if (x == F[x]) {return x;}F[x] = Find(F[x]);return F[x];}private void Union(int x, int y, int pay) {if (Find(x) != Find(y)) {totalCost += pay;}F[Find(x)] = Find(y);}public int minCostToSupplyWater(int N, int[] cost, int[][] es) {Init(N);int[][] conn = new int[es.length + N][3];for (int i = 0; i < es.length; i++) {conn[i][0] = es[i][0];conn[i][1] = es[i][1];conn[i][2] = es[i][2];}int to = es.length;for (int i = 1; i <= N; i++) {conn[to][0] = 0;conn[to][1] = i;conn[to][2] = cost[i - 1];to++;}Arrays.sort(conn, new Comparator<int[]>() {public int compare(int[] a, int[] b) {return a[2] - b[2];}});for (int i = 0; i < conn.length; i++) {Union(conn[i][0], conn[i][1], conn[i][2]);}return totalCost;}}
复杂度分析: 一共有 N 个点,M 条边,N 个点进行 Find/Union 的时间复杂度为 O(lgN),所以总的时间复杂度为 M(lgN)。
【小结】接下来我们从面试官的角度看一下,这道题的考点是什么:
- 将特殊条件转化为一般的条件,通过引入一些虚拟点,虚拟边来实现
- 并查集的模板代码
- 最小生成树的 Kruskal 算法
如果在面试中抓住了这 3 个点,就很容易击破这道算法题。接下来我们看一下并查集的另外一个的考点。
路径压缩
并查集除了前面提到了考点之外,还有一个比较不容易出现的考点。那就是关于路径压缩的考点。
处理这种题时,需要利用路径压缩同时将节点之间的信息进行层层压缩和汇总。求解过程还是很有趣的。下面让我们通过一个例题学习一下这个知识点。
例 6: 倍数关系

【分析】那么首先我们进行一下模拟。
1. 模拟
变量之间的除法关系,我们需要记录一个链式信息。如果将除法当成一个有向边,然后变量与变量之间的除法就可以看成图结构。比如:
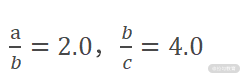
可以表示为下图:
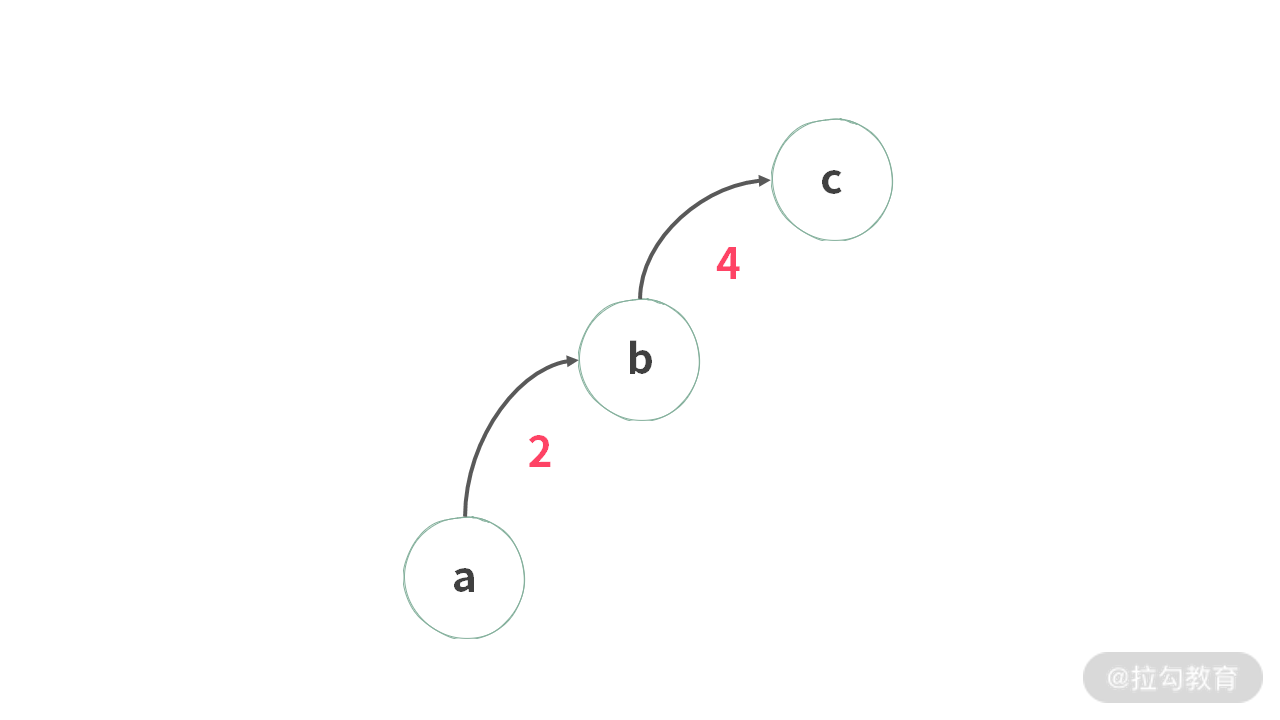
如果我们将上图进行压缩,那么可以得到下图:
经过压缩之后,可以发现这几个元素之间的关系就变成了下面这个样子:
- a = 8 * c
- c = 1 * c
- b = 4 * c
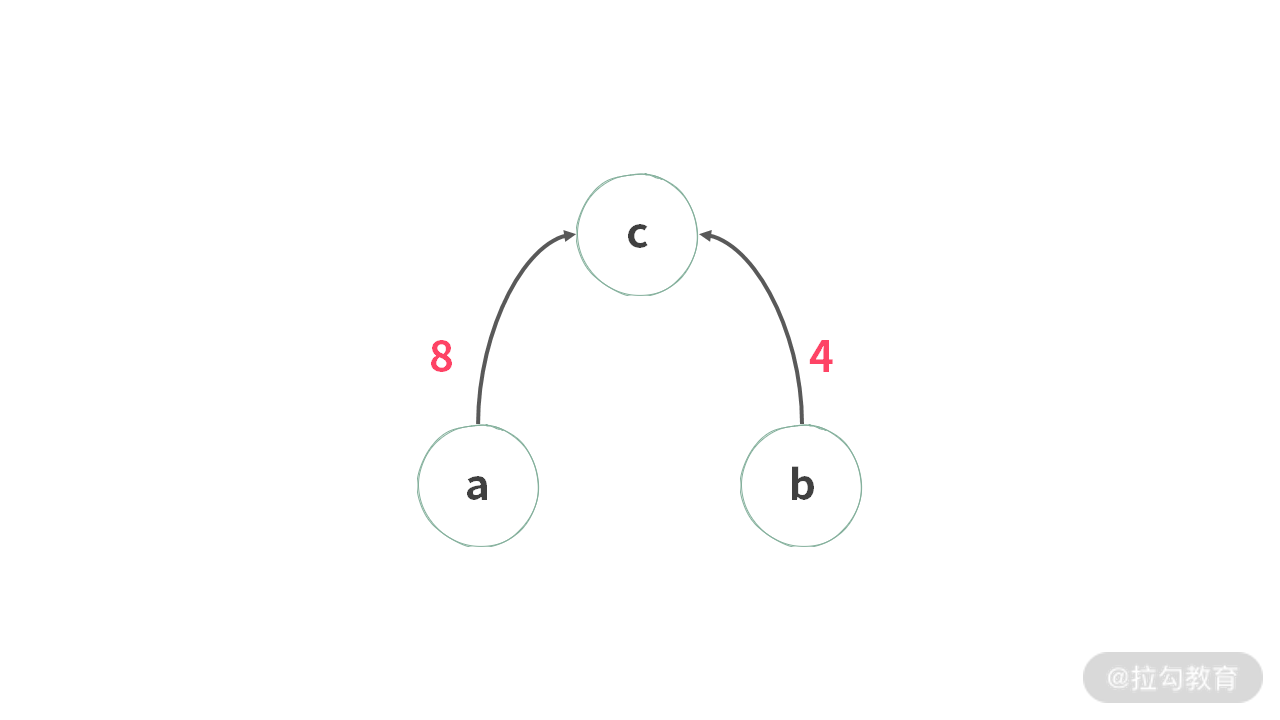
此时,可以得到任意两个变量之间的比值。实际上,这几个数也可以以 a 元素为根,如下图所示:
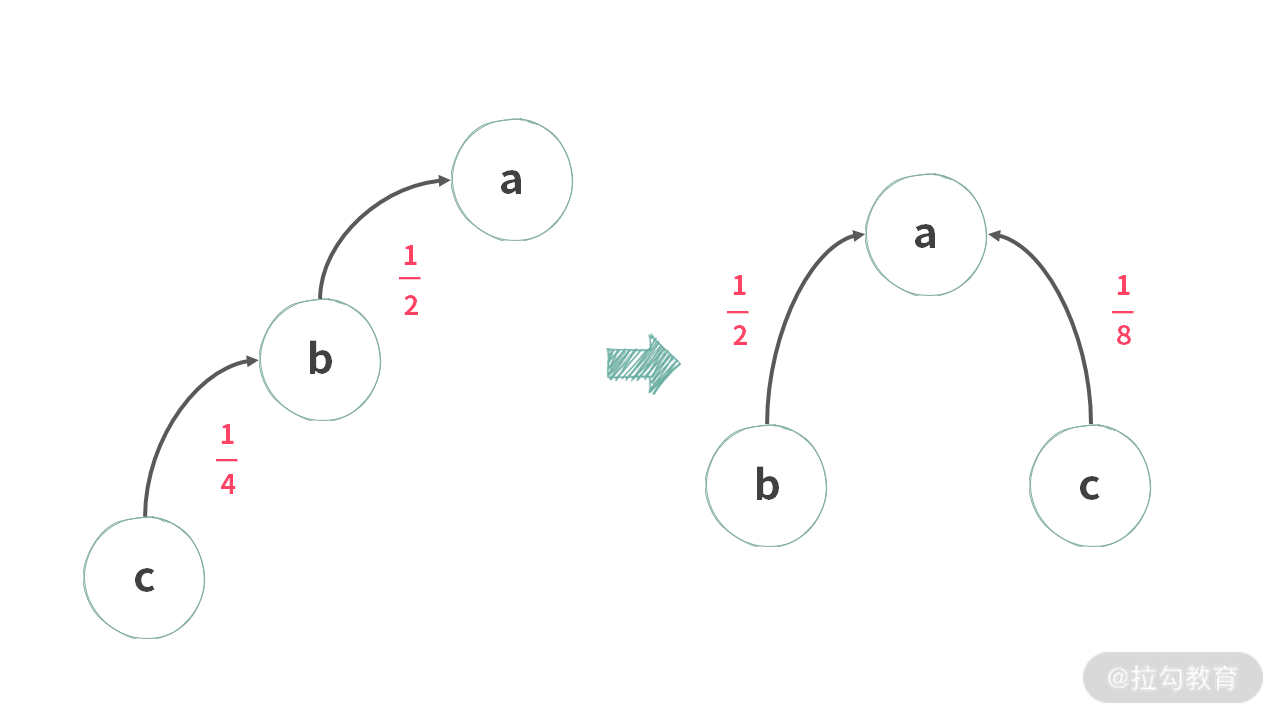
几个元素之间的关系就是这样:
- b = 0.5 * a
- a = 1 * a
- c = 0.125 * a
此时,我们可以得到任意两个变量之间的比值。
2. 规律
在这里,可以通过模拟找到一个规律:只要是相连通的几个元素,可以选择任意一个结点做根结点。连通性好办,重点是:需要记录元素与根元素的比例。
并且我们发现其实哪个点做根结点都一样。但是比例关系怎么办?再回看一下模拟的过程,可以发现:比例关系就是顺着图中,有向边的方向乘过去即可。
这里我们画图表示如下:
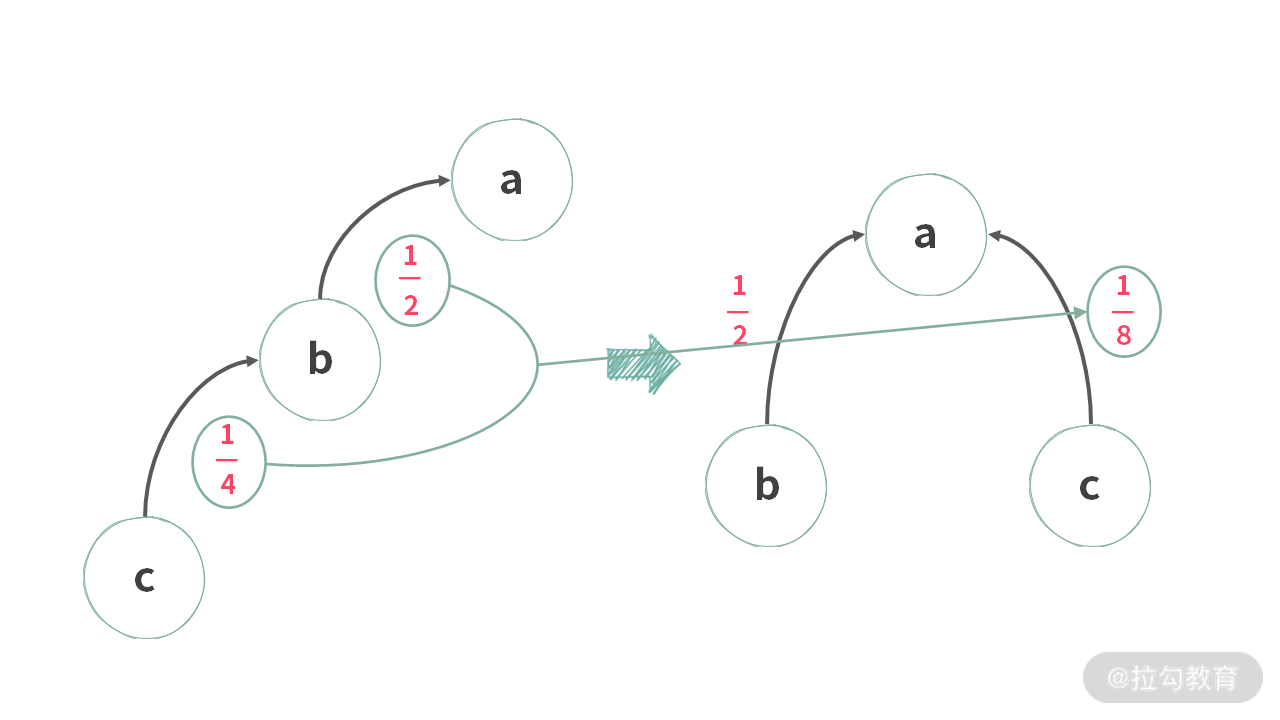
也就是说,在压缩的时候,需要把路径上边的权重依次乘起来。
3. 匹配
通过前面的一番分析,可以发现题目具有两个特点:
- 连通性
- 路径压缩性
能匹配到这两个特点的算法刚好是今天所讲的并查集。
4. 边界
面试官提醒:由于涉及除法,在面试中,你一定要主动提出是否可能存在除 0 的情况。如果给定的输入里面可能有,那么一定要记得处理。
【代码】我们已经有了并查集的代码,那么处理路径压缩,应该也不是什么问题,代码如下(解析在注释里):
void addToMap(String key, Map<String, Integer> H) {final int id = H.size();if (!H.containsKey(key)) {H.put(key, id);}}int[] F = null;double[] C = null;void Init(int n) {F = new int[n];C = new double[n];for (int i = 0; i < n; i++) {F[i] = i;C[i] = 1;}}int Find(int x) {int b = x;double base = 1;while (x != F[x]) {base *= C[x];x = F[x];}int root = x;while (F[b] != root) {double next = base / C[b];C[b] = base;base = next;int par = F[b];F[b] = root;b = par;}return root;}void Union(int T, int D, double v) {int tpar = Find(T);int dpar = Find(D);F[tpar] = dpar;C[tpar] = v * C[D] / C[T];}double[] calcEquation(List<List<String>> equations,double[] values,List<List<String>> queries) {Map<String, Integer> H = new HashMap<>();for (List<String> l : equations) {String t = l.get(0), d = l.get(1);addToMap(t, H);addToMap(d, H);}Init(H.size());for (int i = 0; i < equations.size(); i++) {List<String> l = equations.get(i);Union(H.get(l.get(0)), H.get(l.get(1)), values[i]);}for (int i = 0; i < H.size(); i++) {Find(i);}double[] ans = new double[queries.size()];for (int i = 0; i < queries.size(); i++) {List<String> l = queries.get(i);int tidx = H.containsKey(l.get(0)) ? H.get(l.get(0)) : -1;int didx = H.containsKey(l.get(1)) ? H.get(l.get(1)) : -1;if (tidx == -1 || didx == -1) {ans[i] = -1;} else {int troot = Find(tidx);int droot = Find(didx);if (troot != droot) {ans[i] = -1;} else {ans[i] = C[tidx] / C[didx];}}}return ans;}
复杂度分析:假设有 N 个变量,构建并查集的时间复杂度为 O (NlgN),如果有 M 个 Query,每次在询问为 O(1),所以总的时间复杂度为 max(O(NlgN),M)。
【小结】如果要解决这道题,那么需要注意掌握以下三点。
- 连通域里面的所有变量都统一用一个变量表示倍数关系,那么任意的两个变量就可以直接询问倍数关系。
- 倍数关系具有传递性,即:

这是我们进行路径压缩的关键。 - Union 操作时,注意变量倍数关系的调整。
如果想到了这些,再加上我介绍的并查集的代码模板,那么解决这道面试题也就没什么难度了。以后在面试中,你如果发现题目具有传递性的特点,就可以使用并查集进行求解。
总结
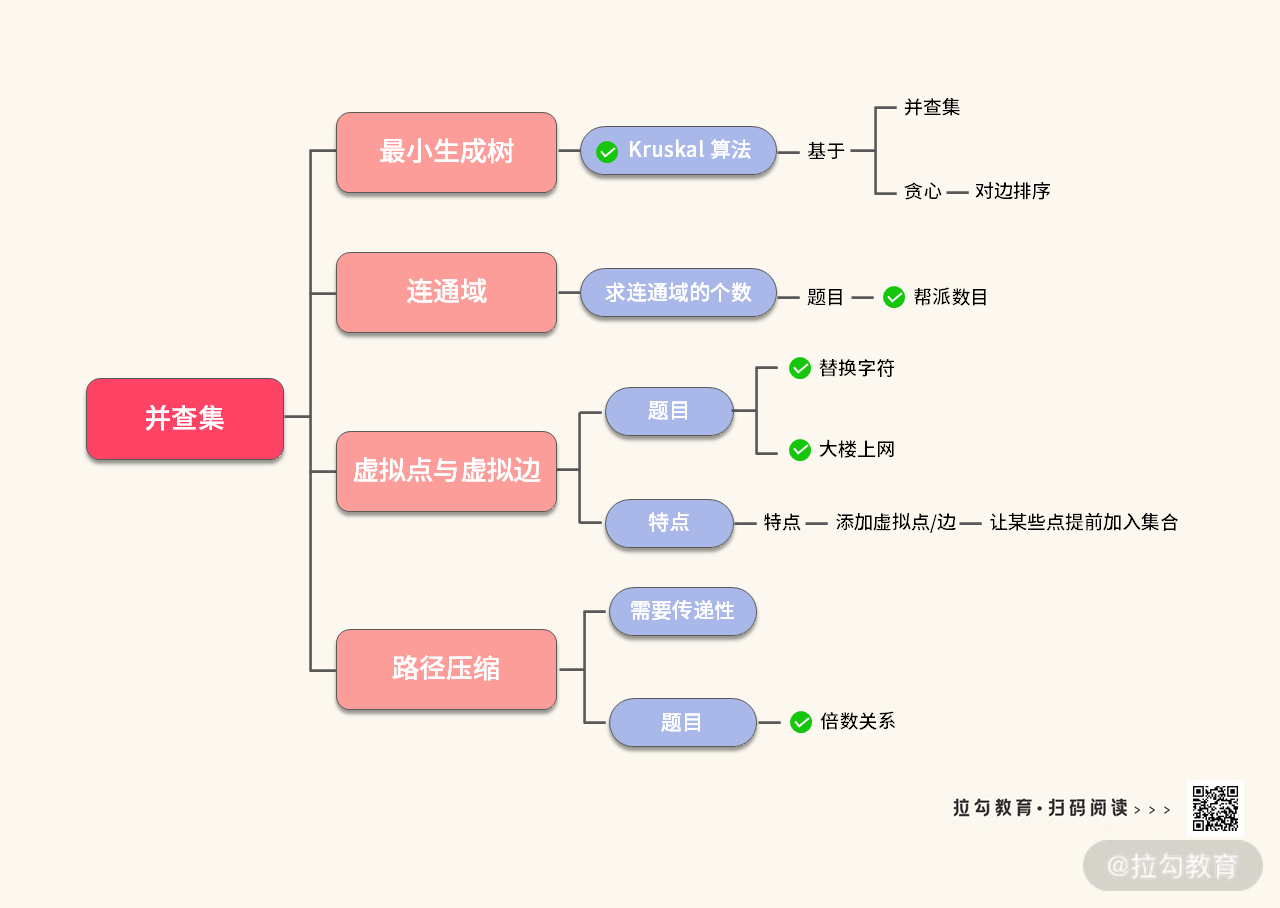
在本讲中,我介绍了并查集面试时常见的考察点,并且给出了并查集的代码模板。最后我还给你准备了并查集的知识树,面试中并查集相关的问题基本上逃不出这个圈。希望你可以尝试自己对本讲的内容进行梳理,然后再对照下图查缺补漏。
思考题
如果我们把例 5 的变量看成图上的点,变量与变量之间的关系看成是边。一旦构建好了并查集,在 Query 的时候,就可以 O(1) 的时间查询到两个变量之间的代价。那么为什么在图算法中,我们需要用 Floyd 算法求解图中两个点之间的最短路径?
希望你可以把思考写在留言区,我们一起讨论,如果看到有趣的想法,我也会做成加餐和大家分享。:)
到这里,我们就要与并查集说再见了,接下来我们一起学习 08|排序:如何利用合并与快排的小技巧,解决算法难题。记得按时来探险。

若有收获,就点个赞吧
0 人点赞
