《谁动了我的奶酪?》是美国作家斯宾塞·约翰逊创作的一个寓言故事,该书首次出版于1998年。书中主要讲述4个“人物”—两只小老鼠“嗅嗅(Sniff)”、“匆匆(Scurry)”和两个小矮人“哼哼(Hem)”、“唧唧(Haw)”找寻奶酪的故事。
文件“Who Moved My Cheese.txt”中包含这个故事的中英文,格式如下:
请按照函数的注释,补充程序中缺失部分语句,按要求实现如下程序功能:
read_file()函数将文件中的内容读为字符串,过滤掉中文,只保留文件中的英文字母和西文符号(只保留ASCII码字符)。所有字符转为小写,将其中所有标点、符号替换为空格。
count_of_words()函数统计read_file()函数返回的字符串中的单词数量和不重复的单词数量。
top_ten_words()函数分行依次输出出现次数最多的n个单词及其出现次数。
word_frequency()函数统计并以字典类型返回每个单词出现的次数。
top_ten_words_no_excludes()函数统计并输出去除常见的冠词、代词、系动词和连接词后,出现次数最多的 cnt个单词及其出现次数。
根据用户输入的指令和任务完成程序:
- 若输入指令为“1”,则在下一行中输入一个非负整数n,并输出read_file()函数返回值的前n个字符。
- 若输入指令为“2”,并调用count_of_words()函数统计输出read_file()函数返回的字符串中的单词数量和不重复的单词数量,格式参考下面的输入输出示例,其中的XXXX需用统计出的实际数值替换。
- 若输入指令为“3”,则在下一行中输入一个正整数n,并调用top_ten_words()函数分行依次输出出现次数最多的n个单词及其出现次数,单词和次数之间以空格间隔。
- 若输入指令为“4”,则在下一行中输入一个非负整数n,并调用top_ten_words_no_excludes()函数从词频统计结果中去除常见的冠词、代词、系动词和连接词后统计词频,再输出出现次数最多的n个单词及其出现次数,单词和次数之间以空格间隔。需排除的单词包括:[‘a’, ‘an’, ‘the’, ‘i’, ‘he’, ‘she’, ‘his’, ‘my’, ‘we’,’or’, ‘is’, ‘was’, ‘do’, and’, ‘at’, ‘to’, ‘of’, ‘it’, ‘on’, ‘that’, ‘her’, ‘c’,’in’, ‘you’, ‘had’, ‘s’, ‘with’, ‘for’, ‘t’, ‘but’, ‘as’, ‘not’, ‘they’, ‘be’, ‘were’, ‘so’, ‘our’, ‘all’, ‘would’, ‘if’, ‘him’, ‘from’, ‘no’, ‘me’, ‘could’, ‘when’, ‘there’, ‘them’, ‘about’, ‘this’, ‘their’, ‘up’, ‘been’, ‘by’, ‘out’, ‘did’, ‘have’]
参考资料:
【ASCII 码表】
0000-007F(0-127):C0控制符及基本拉丁文 (C0 Control and Basic Latin)
0080-00FF(128-255):C1控制符及拉丁文补充-1 (C1 Control and Latin 1 Supplement) 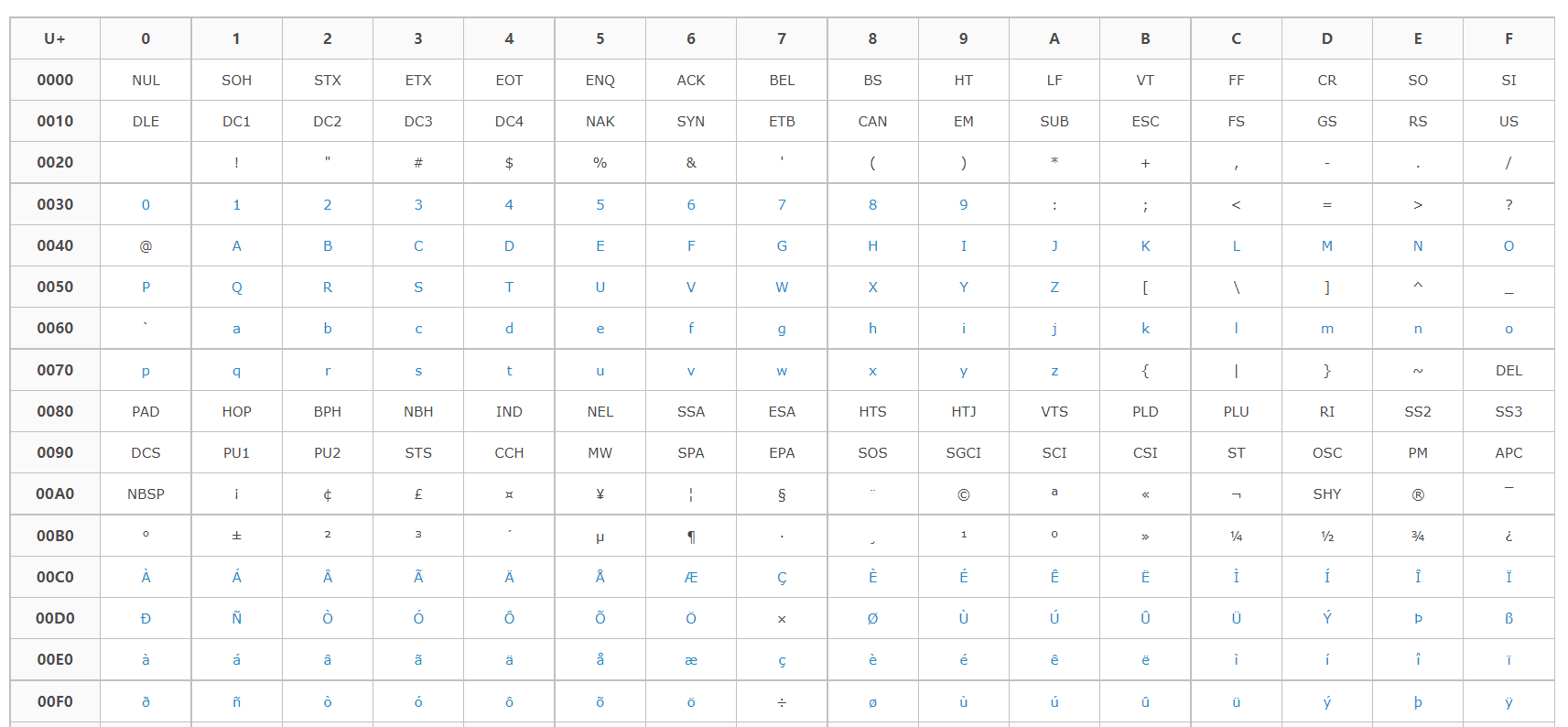
import stringdef read_file(file):"""接收文件名为参数,将文件中的内容读为字符串,只保留文件中的英文字母和西文符号,过滤掉中文(中文字符及全角符号Unicode编码都大于256)将所有字符转为小写,将其中所有标点、符号替换为空格,返回字符串"""with open(file, 'r', encoding='utf-8') as novel:txt = novel.read()english_only_txt = ''.join(x for x in txt if ord(x) < 256)english_only_txt = english_only_txt.lower()for character in string.punctuation:english_only_txt = english_only_txt.replace(character, ' ')return english_only_txtdef count_of_words(txt):"""接收去除标点、符号的字符串,统计并返回其中单词数量和不重复的单词数量"""words_list = txt.split()amount_of_words = len(txt.split())amount_of_words_no_repeat = len(set(words_list))return amount_of_words, amount_of_words_no_repeatdef word_frequency(txt):"""接收去除标点、符号的字符串,统计并返回每个单词出现的次数返回值为字典类型,单词为键,对应出现的次数为值"""frequency = dict()words_list = txt.split()for word in words_list:frequency[word] = frequency.get(word, 0) + 1return frequencydef top_ten_words(frequency, cnt):"""接收词频字典,输出出现次数最多的cnt个单词及其出现次数"""frequency_items = sorted(frequency.items(), key=lambda x: x[1], reverse=True)for word, counts in frequency_items[:cnt]:print(word, counts)def top_ten_words_no_excludes(frequency, cnt):"""接收词频字典,去除常见的冠词、代词、系动词和连接词后,输出出现次数最多的cnt个单词及其出现次数,需排除的单词如下:excludes_words = ['a', 'an', 'the', 'i', 'he', 'she', 'his', 'my', 'we','or', 'is', 'was', 'do', 'and', 'at', 'to', 'of', 'it', 'on', 'that', 'her','c','in', 'you', 'had','s', 'with', 'for', 't', 'but', 'as', 'not', 'they','be', 'were', 'so', 'our','all', 'would', 'if', 'him', 'from', 'no', 'me','could', 'when', 'there','them', 'about', 'this', 'their', 'up', 'been','by', 'out', 'did', 'have']"""excludes_words = ['a', 'an', 'the', 'i', 'he', 'she', 'his', 'my', 'we','or', 'is', 'was', 'do', 'and', 'at', 'to', 'of', 'it','on', 'that', 'her', 'c','in', 'you', 'had','s', 'with','for', 't', 'but', 'as', 'not', 'they', 'be', 'were','so', 'our','all', 'would', 'if', 'him', 'from', 'no','me', 'could', 'when', 'there','them', 'about', 'this','their', 'up', 'been', 'by', 'out', 'did', 'have']for word in excludes_words:frequency.pop(word)frequency_items = sorted(frequency.items(), key=lambda x: x[1], reverse=True)for word, counts in frequency_items[:cnt]:print(word, counts)# 取消这段和代码最后二行注释可以绘制词云,仅供参考def draw_cloud(frequency):"""绘制词云,传入参数为词频,设定图片的宽度600,高度400,背景白色、字体最大值150、图片边缘为5。"""wc = WordCloud(max_words=80, # 设置显示高频单词数量width=600, # 设置图片的宽度height=400, # 设置图片的高度background_color='White', # 设置背景颜色max_font_size=150, # 设置字体最大值margin=5, # 设置图片的边缘scale=1.5) # 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。wc.generate_from_frequencies(frequency) # 根据文本内容直接生成词云plt.imshow(wc) # 负责对图像进行处理,并显示其格式,但是不能显示。plt.axis("off") # 不显示坐标轴wc.to_file('My Cheese.png') # 词云保存为图片plt.show() # 显示图像if __name__ == '__main__':filename = 'Who Moved My Cheese.txt' # 文件名content = read_file(filename) # 调用函数返回字典类型的数据frequency_result = word_frequency(content) # 统计词频cmd = input()if cmd == '1':n = int(input())print(content[:n])elif cmd == '2':amount_results = count_of_words(content)print('文章共有单词{}个,其中不重复单词{}个'.format(*amount_results))elif cmd == '3':n = int(input())top_ten_words(frequency_result, n)elif cmd == '4':n = int(input())top_ten_words_no_excludes(frequency_result, n)# frequency_no_excludes = top_ten_words_no_excludes(frequency_result)# draw_cloud(frequency_no_excludes)

若有收获,就点个赞吧
0 人点赞
