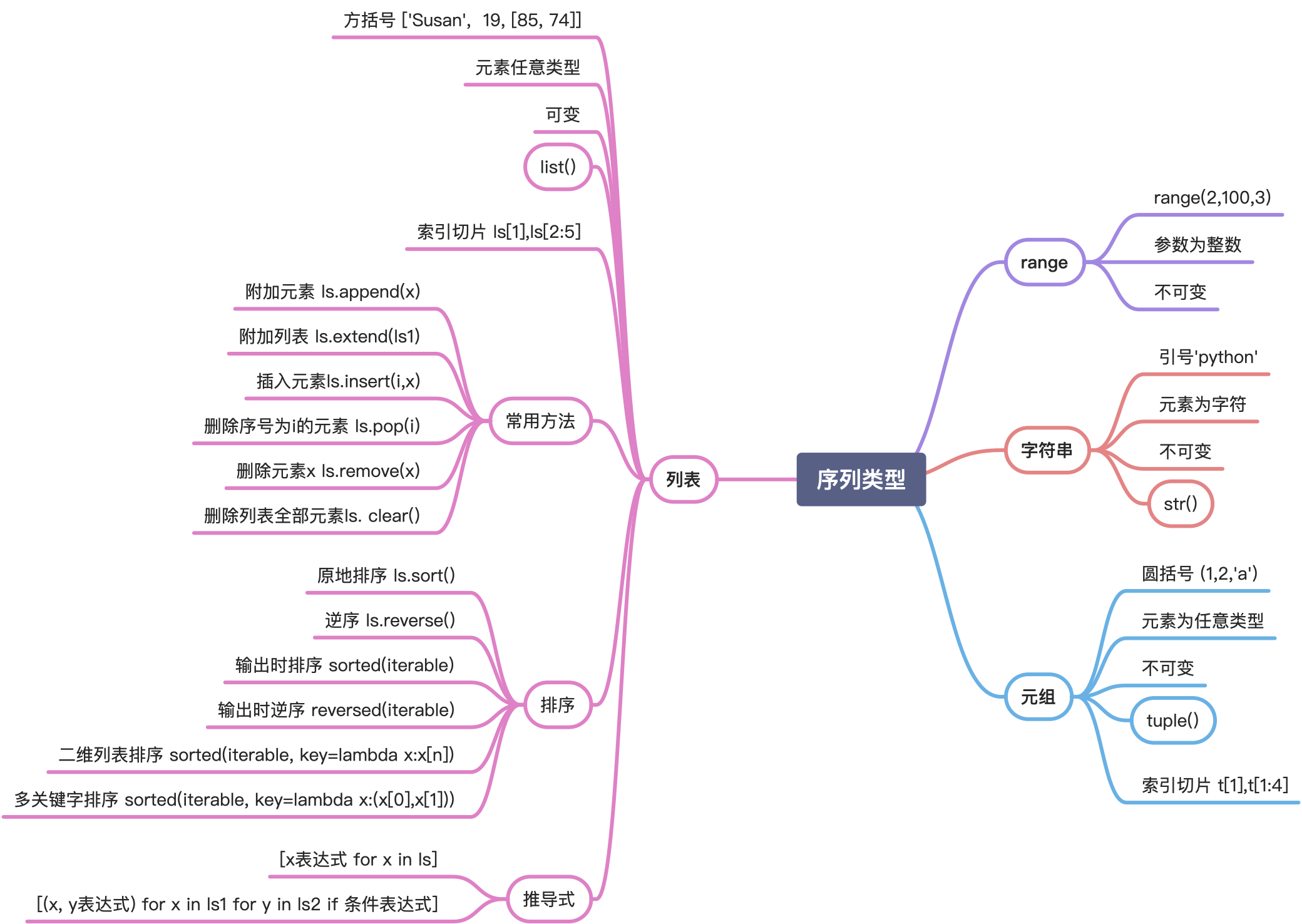
多变量赋值
在确定序列长度的情况下,可以应用Python多变量赋值语句把元组、列表和字符串等序列解包,将其中的多个元素分别赋值给多个独立的变量。
x,y = (5,10) # 元组元素按顺序赋值给多个变量m,n = 3,4 # 3,4为元组,元组元素按顺序赋值给多个变量a,b,c = 'xyz' # 字符串中字符按顺序赋值给多个变量i,j = [3,6] # 列表元素按顺序赋值给多个变量
多变量赋值时,序列长度必须与变量数量一致,否则将引发ValueError:
能力点1:列表创建与操作
列表的创建
直接用方括号 []
ls = [] # 空的中括号创建空列表ls = [1, 2, 3] # 中括号中用逗号分隔的0个或多个元素
列表推导式
[x for x in iterable] # 用把可迭代对象中的元素取出转为列表
ls = [x for x in '371'] # ['3', '7', '1']ls = [int(x) for x in '371'] # [3, 7, 1]ls = [int(x) ** 3 for x in '371'] # [27, 343, 1]print(sum(ls)) # 371
水仙花数
水仙花数是指一个 3 位数,它的每个位上的数字的 3 次幂之和等于它本身(例如:13 + 53+ 33 = 153),输出所有3位的水仙花数。
for num in range(100, 1000): # 遍历所有3位数
if num == sum([int(x) ** 3 for x in str(num)]): # 若当前数与该数各位上的数的3次方加和相等
print(num)
# 153 370 371 407
自幂数
n为3时,自幂数称为水仙花数,有4个
n为4时,自幂数称为四叶玫瑰数,共有3个
n为5时,自幂数称为五角星数,共有3个
n为6时,自幂数称为六合数, 只有1个
n为7时,自幂数称为北斗七星数, 共有4个
n为8时,自幂数称为八仙数, 共有3个
n为9时,自幂数称为九九重阳数,共有4个
n为10时,自幂数称为十全十美数,只有1个
n = int(input())
for num in range(10 ** (n - 1), 10 ** n): # 遍历n位数
if num == sum([int(x) ** n for x in str(num)]):
print(num, end=' ')
# 5
# 54748 92727 93084
5位数:10000-99999,共89999个,每个数有5位,那么int(x)*n要计算589999近45万次
table = [x ** m for x in range(10)] # 得到0-9各数的n次方的列表
print(table) # n = 3时[0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
n = int(input())
table = [x ** n for x in range(10)] # 得到0-9各数的n次方的列表
for num in range(10 ** (n - 1), 10 ** n): # 遍历n位数
if num == sum([table[int(i)] for i in str(num)]):
print(num, end=' ')
def armstrong_number(n):
"""接受一个大于2的正整数为参数,输出n位自幂数"""
for num in range(10 ** (n - 1), 10 ** n): # 遍历n位数
if num == sum([table[int(i)] for i in str(num)]):
print(num)
if __name__ == '__main__':
m = int(input())
table = [x ** m for x in range(10)] # 得到0-9各数的n次方的列表
armstrong_number(m)
- list()函数将其他类型转列表
```python
ls = list() # 空列表
ls = list(range(1, 5)) # [0, 1, 2, 3, 4]
ls = list(‘武汉理工大学’) # [‘武’, ‘汉’, ‘理’, ‘工’, ‘大’, ‘学’]
ls = list({1, 2, 3, 4}) # [1, 2, 3, 4]
ls = list({‘name’: ‘Tom’, ‘age’: 18, ‘gender’: ‘Male’}) # 字典的键转列表元素
[‘name’, ‘age’, ‘gender’]
4. split()函数将字符串切分为列表
```python
title = '姓名,C,Java,Python,C#'
print(title.split(',')) # ['姓名', 'C', 'Java', 'Python', 'C#']
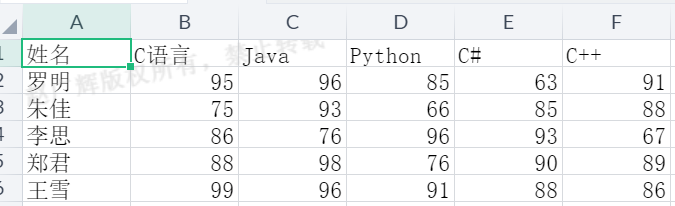
with open('../data/csv/5.7 score.csv','r',encoding='utf-8') as data:
score = [x.strip().split(',') for x in data] # 列表推导式
print(score) # 得到二维列表
[[‘姓名’, ‘C语言’, ‘Java’, ‘Python’, ‘C#’, ‘C++’],
[‘罗明’, ‘95’, ‘96’, ‘85’, ‘63’, ‘91’],
[‘朱佳’, ‘75’, ‘93’, ‘66’, ‘85’, ‘88’],
[‘李思’, ‘86’, ‘76’, ‘96’, ‘93’, ‘67’],
[‘郑君’, ‘88’, ‘98’, ‘76’, ‘90’, ‘89’],
[‘王雪’, ‘99’, ‘96’, ‘91’, ‘88’, ‘86’]]
列表的更新
可变数据类型的一些操作无返回值
list[i] = a # 赋值操作,改变序号为i的元素的值
list.append(x) # 无返回值,向列表末尾增加一个元素x
list.extend(iterable) # 无返回值,将参数转为列表,拼接在原列表末尾
list.insert(i, x) # 无返回值,在序号为i的位置插入一个元素x
需要注意的是,list.extend(iterable) 可接受可迭代对象为参数,将可迭代对象转为列表后拼接到原列表末尾。
ls = [1, 2] # [1, 2]
ls.extend('Tom') # [1, 2, 'T', 'o', 'm']
ls.extend(range(3)) # [1, 2, 'T', 'o', 'm', 0, 1, 2]
ls.extend({'a', 'b'}) # [1, 2, 'T', 'o', 'm', 0, 1, 2, 'a', 'b']
print(ls) # [1, 2, 'T', 'o', 'm', 0, 1, 2, 'a', 'b']
参数为可迭代对象时,二者不同。
ls = [1, 2] # [1, 2]
ls.append([3, 4]) # [1, 2, [3, 4]],对象整体加入,一个对象
ls.extend([5, 6]) # [1, 2, [3, 4], 5, 6],加入对象中的元素,相同对象的拼接
print(ls) # [1, 2, [3, 4], 5, 6]
列表的删除
x = list.pop(i) # 移除列表中序号为“i”的一个元素,唯一有返回值的删除方法,返回值为被移除的元素
list.remove(x) # 删除列表中第一个与参数“x”值相同的元素,无返回值
list.clear() # 删除列表中全部元素,无返回值
- list.pop(i):用于移除列表中序号为“i”的一个元素
缺省移除列表的最后一个元素
唯一能删除列表元素又能返回值的列表方法,其返回值为被移除的元素。
2.list.remove(x):删除列表中第一个与参数“x”值相同的元素ls = list('08974') # 将字符串转为列表['0', '8', '9', '7', '4'] ls.pop() # 移除列表中最后一个元素'4' print(ls) # ['0', '8', '9', '7'] s = ls.pop() # 移除列表最后一个元素'7',并将其赋值给s print(ls, s) # 输出列表元素和移除的元素['0', '8', '9'] 7 ls.pop(2) # 移除列表中序号为2的元素'9' print(ls) # ['0', '8'] s = ls.pop(-2) # 移除列表中序号为-2的元素,并将其赋值给s print(ls, s) # 输出列表元素和移除的元素['8'] 0
元素“x”不存在时,抛出错误“ValueError: list.remove(x): x not in list”
不确定要删除的元素在列表中是否存在时,要先做成员测试:ls = list('08984') # 将字符串转为列表 ['0', '8', '9', '8', '4'] ls.remove('8') # 删除列表中字符串元素'8',只移除第一个'8' print(ls) # ['0', '9', '8', '4']ls = ['0', '8', '9', '8', '4'] ls.remove(9) # 删除列表中整数元素9,存在字符串'9',不存在数字9 # 删除对象不在列表中存在,ValueError: list.remove(x): x not in list if 9 in ls: # 若欲删除元素在列表中存在 ls.remove(9) # 删除元素 - list.clear():删除列表中全部元素,即清空列表
ls.clear()作用与del ls [:]相同
del 列表名 删除列表对象ls = list('08984') # 将字符串转为列表 ['0', '8', '9', '8', '4'] ls.clear() # 删除列表中全部元素 print(ls) # 输出没有元素的空列表[] ls = list('08984') # 将字符串转为列表 ['0', '8', '9', '8', '4'] del ls[:] # 删除列表中全部元素 print(ls) # 输出没有元素的空列表[]
del 列表切片 删除列表中的元素ls = list(range(1, 10, 2)) # range转列表[1, 3, 5, 7, 9] del ls[1] # 删除列表ls中序号为1的元素3 print(ls) # [1, 5, 7, 9] del ls[:] # 删除列表中全部元素 print(ls) # 输出没有元素的空列表[] del ls # 删除列表对象ls,列表ls不存在了 print(ls) # NameError: name 'ls' is not defined。示例8.1 读文件到列表
8.5 score.csv
读文件到列表,元素为字符串 ```python with open(‘../data/csv/8.5 score.csv’, ‘r’, encoding=’utf-8’) as fr: score_lst = [line.strip().split(‘,’) for line in fr] print(score_lst)姓名,学号,C语言,Java,Python,VB,C++,总分 朱佳,0121701100511,75.2,93,66,85,88,407 李思,0121701100513,86,76,96,93,67,418 郑君,0121701100514, ,98,76, ,89,263 王雪,0121701100515,99,96,91,88,86,460 罗明,0121701100510,95,96,85,63,91,430
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],<br />['朱佳', '0121701100511', '75.2', '93', '66', '85', '88', '407'],<br />['李思', '0121701100513', '86', '76', '96', '93', '67', '418'],<br />['郑君', '0121701100514', ' ', '98', '76', ' ', '89', '263'],<br />['王雪', '0121701100515', '99', '96', '91', '88', '86', '460'],<br />['罗明', '0121701100510', '95', '96', '85', '63', '91', '430']]
```python
def read_file(file):
"""参数file是文件名变量,读文件中的数据到列表中,每行数据根据逗号切分为列表,返回二维列表"""
with open(file, 'r', encoding='utf-8') as fr:
score_lst = [line.strip().split(',') for line in fr]
return score_lst
读文件到二维列表,将分数数据转为数值类型,保持学号为字符串类型不变,缺失数据用0替换。
def is_number(value):
"""当参数可转为数值型时,返回True"""
return value.strip().lstrip('-+').replace('.', '', 1).isdigit()
def clean_data(data):
"""当参数中的字符串元素可转为数值型时,将其转为数值型
当值为整数时转为整数,值为浮点数时转为浮点数
列表原地操作,无返回值
"""
for lst in data: # 遍历列表中的元素
for i in range(len(lst)):
if lst[i][0] == '0': # 保留学号数据仍为字符串类型
continue
elif lst[i] == ' ': # 缺失数据用0填充
lst[i] = 0
elif is_number(lst[i]): # 如果是数值型字符串
lst[i] = eval(lst[i]) # 转为数值类型
def read_file(file):
"""读文件中的数据到列表中,每行数据根据逗号切分为列表,返回二维列表"""
with open(file, 'r', encoding='utf-8') as fr:
score_lst = [line.strip().split(',') for line in fr]
clean_data(score_lst) # 调用函数处理缺失数据并转数据类型
return score_lst
if __name__ == '__main__':
filename = '../data/csv/8.5 score.csv'
score = read_file(filename)
print(score)
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['朱佳', '0121701100511', 75.2, 93, 66, 85, 88, 407],
['李思', '0121701100513', 86, 76, 96, 93, 67, 418],
['郑君', '0121701100514', 0, 98, 76, 0, 89, 263],
['王雪', '0121701100515', 99, 96, 91, 88, 86, 460],
['罗明', '0121701100510', 95, 96, 85, 63, 91, 430]]
能力点2:排序
列表的排序
list.sort() # 列表排序,无返回值,原地排序
list.reverse() # 列表逆序,无返回值,原地排序
sorted() # 序列排序,返回值为排序列表
reversed(seq) # 序列逆序,返回迭代器
list.sort(*, key=None, reverse=False) # 排序,接收2个参数,这两个参数只能通过关键字传递
list.reverse()
reversed(seq) # 返回一个迭代器对象iterator,需用list转列表
sorted(iterable, *, key=None, reverse=False) # 返回排序列表
ls.sort()方法可以对列表ls中的数据在原地进行排序
默认规则是直接比较元素大小
(注意字符串的比较是逐位比较每个字符的大小,如,字符串’13’<’5’)。
缺省时参数reverse=False,为升序排序;
当设置参数reverse=True时,为降序排序。
参数key可以指定排序时应用到每个参与排序元素上的规则,不影响列表中元素的值。例如:
ls = ['app', 'Apple', 'at', 'AM'] # 元素为字符串的列表ls
ls.sort(key=str.lower) # 字符串中的字符按小写比较排序
print(ls) # ['AM', 'app', 'Apple', 'at']
ls.sort(key=len) # 按各元素字符串长度排序
print(ls) # ['AM', 'at', 'app', 'Apple']
ls = ['73', '13', '9', '5', '04'] # 元素为字符串的列表ls
ls.sort(key=int) # 按各元素转整型结果排序
print(ls) # ['04', '5', '9', '13', '73']
区别
ls = [56,4,89,23]
ls.sort() # 无返回值,不能直接print(ls.sort())
print(ls) # 输出列表名
ls.reverse() # 无返回值,不能直接print(ls.reverse())
print(ls)
lst = sorted(ls) # 返回排序列表,可以print(sorted(ls))
print(lst)
# print(reversed(ls)) # 返回一个迭代器对象iterator
print(list(reversed(lst))) # 用list()将迭代器对象转列表查看
二维列表的排序
list.sort(*, key=lambda x: x[i], reverse=False) # x是子列表,x[i]是子列表中的元素
list.sort(*, key=lambda x: (x[i],x[j],x[k]), reverse=False) # 多排序关键字时用元组
sorted(iterable, *, key=lambda x: x[i], reverse=False)
score = [['Angle', '0121701100106',99],
['Jack', '0121701100107',86],
['Tom', '0121701100109',65],
['Smith', '0121701100111', 100],
['Bob', '0121701100115',77],
['Lily', '0121701100117', 59]]
每个列表元素的三个数据分别代表姓名、学号和成绩
请分别按姓名、学号和成绩排序输出。
匿名函数中的x为子列表,如[‘Angle’, ‘0121701100106’, 99]
score = [['Angle', '0121701100106', 99],
['Jack', '0121701100107', 86],
['Tom', '0121701100109', 77],
['Smith', '0121701100111', 100],
['Bob', '0121701100115', 77],
['Lily', '0121701100117', 59]]
print('按姓名排序')
print(sorted(score, key=lambda x: x[0])) # 按序号0元素“姓名”排序
print('按学号排序')
print(sorted(score, key=lambda x: x[1])) # 按序号1元素“学号”排序
print('优先按成绩排序再按姓名排序')
# 按成绩升序排序,成绩相同时再按学号升序排序
print(sorted(score, key=lambda x: (x[2], x[0]))) # 多关键字逗号分隔
按姓名排序
[[‘Angle‘, ‘0121701100106’, 99],
[‘Bob‘, ‘0121701100115’, 77],
[‘Jack‘, ‘0121701100107’, 86],
[‘Lily‘, ‘0121701100117’, 59],
[‘Smith‘, ‘0121701100111’, 100],
[‘Tom‘, ‘0121701100109’, 77]]
按学号排序
[[‘Angle’, ‘0121701100106‘, 99],
[‘Jack’, ‘0121701100107‘, 86],
[‘Tom’, ‘0121701100109‘, 77],
[‘Smith’, ‘0121701100111‘, 100],
[‘Bob’, ‘0121701100115‘, 77],
[‘Lily’, ‘0121701100117‘, 59]]
优先按成绩排序再按姓名排序
[[‘Lily’, ‘0121701100117’, 59],
[‘Bob‘, ‘0121701100115’, 77],
[‘Tom‘, ‘0121701100109’, 77],
[‘Jack’, ‘0121701100107’, 86],
[‘Angle’, ‘0121701100106’, 99],
[‘Smith’, ‘0121701100111’, 100]]
实例 8.2 元素为字符串的二维列表排序
对列表[(‘hubei’, ‘wuhan’), (‘hubei’, ‘huangshi’), (‘hubei’, ‘huanggang’), (‘hunan’, ‘shangsha’)]进行排序,先输出默认排序结果;再先按城市名升序排序,城市名相同时按省名升序排序;再先按省名降序排序,省名相同时按城市名升序排序;
对于多个排序关键字都是字符串类型的,排序一个升序一个降序时,可以将字符依次转为unicode编码做排序依据,以值的正负表示降序或升序。
city = [('hubei', 'wuhan'), ('hubei', 'huangshi'), ('hubei', 'huanggang'), ('hunan', 'shangsha')]
print(sorted(city))
print(sorted(city, key=lambda x: (x[1], x[0])))
print(sorted(city, key=lambda x: ([-ord(i) for i in x[0]], [ord(i) for i in x[1]])))
输出:
[(‘hubei’, ‘huanggang’), (‘hubei’, ‘huangshi’), (‘hubei’, ‘wuhan’), (‘hunan’, ‘shangsha’)]
[(‘hubei’, ‘huanggang’), (‘hubei’, ‘huangshi’), (‘hunan’, ‘shangsha’), (‘hubei’, ‘wuhan’)]
[(‘hunan’, ‘shangsha’), (‘hubei’, ‘huanggang’), (‘hubei’, ‘huangshi’), (‘hubei’, ‘wuhan’)]
示例8.3 读文件到列表并排序
# 定义符号常量,方便索引和切片,避免数错列序号
NAME = 0
TOTAL = -1
JAVA = 3
PYTHON = 4
# 其他函数略
def sort_score(score_lst):
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: x[-1], reverse=True)) # 根据总分降序排序
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: (x[JAVA], x[TOTAL]),reverse=True))
# 根据java降序排序,分数相同时按总分降序
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: (x[JAVA], -x[TOTAL]),reverse=True))
# 根据java降序排序,分数相同时按总分升序
if __name__ == '__main__':
filename = '../data/csv/8.5 score.csv'
score = read_file(filename)
sort_score(score)
# 根据Python成绩升序排序66,76,85,91,96
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['朱佳', '0121701100511', 75.2, 93, 66, 85, 88, 407],
['郑君', '0121701100514', 0, 98, 76, 0, 89, 263],
['罗明', '0121701100510', 95, 96, 85, 63, 91, 430],
['王雪', '0121701100515', 99, 96, 91, 88, 86, 460],
['李思', '0121701100513', 86, 76, 96, 93, 67, 418]]
# 根据总分降序排序
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['王雪', '0121701100515', 99, 96, 91, 88, 86, 460],
['罗明', '0121701100510', 95, 96, 85, 63, 91, 430],
['李思', '0121701100513', 86, 76, 96, 93, 67, 418],
['朱佳', '0121701100511', 75.2, 93, 66, 85, 88, 407],
['郑君', '0121701100514', 0, 98, 76, 0, 89, 263]]
# 根据java降序排序98,96,96,93,76
# 分数相同时按总分升序263,460,430,407,418
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['郑君', '0121701100514', 0, 98, 76, 0, 89, 263],
['王雪', '0121701100515', 99, 96, 91, 88, 86, 460],
['罗明', '0121701100510', 95, 96, 85, 63, 91, 430],
['朱佳', '0121701100511', 75.2, 93, 66, 85, 88, 407],
['李思', '0121701100513', 86, 76, 96, 93, 67, 418]]
# 根据java降序排序98,96,96,93,76
# 分数相同时按总分升序263,430,460,407,418
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['郑君', '0121701100514', 0, 98, 76, 0, 89, 263],
['罗明', '0121701100510', 95, 96, 85, 63, 91, 430],
['王雪', '0121701100515', 99, 96, 91, 88, 86, 460],
['朱佳', '0121701100511', 75.2, 93, 66, 85, 88, 407],
['李思', '0121701100513', 86, 76, 96, 93, 67, 418]]
能力点3:应用推导式实现函数式编程
列表推导式
推导式又称解析式,可以从一个数据序列构建另一个新的数据序列的结构体
本质上可以将其理解成一种集成了变换和筛选功能的函数
列表推导式[x表达式 for x in 列表 if 条件表达式]
字典推导式{x表达式 for x in 集合 if 条件表达式}
集合推导式{x: y表达式 for x,y in 字典 if 条件表达式}
列表推导式由1个表达式跟一个或多个for 从句、0个或多个if从句构成。
[x表达式 for x in 列表 if 条件表达式]
[(x, y表达式) for x in 列表1 for y in 列表2 if 条件表达式]
for前面是一个表达式,in 后面是列表或能生成列表的对象。
将in后面列表中的每一个数据作为for前面表达式的参数,再将计算得到的序列转成列表。
if是一个条件从句,可以根据条件返回新列表。
例如,计算0-9中每个数的平方,存储于列表中输出,可以用以下方法实现:
squares = [] # 创建空列表squares
for x in range(10): # x依次取0-10中的数字
squares.append(x**2) # 向列表中增加x的平方
print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 用列表推导式实现
squares = [x**2 for x in range(10)] # 用range()推导新列表
print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
用列表推导式实现的代码更简洁。
in 后面也可以直接是一个列表,推导式中可以包含条件运算,只根据满足条件的元素推导新列表。例如:
ls = list(range(6)) # [0, 1, 2, 3, 4, 5]
squares = [x ** 2 for x in ls] # 根据列表推导新列表
print(squares) # [0, 1, 4, 9, 16, 25]
squares = [x ** 2 for x in ls if x % 2 == 1] # 根据奇数推导
print(squares) # 奇数平方的列表 [1, 9, 25]
ls = [-4, -2, 0, 4]
print([x * 2 for x in ls]) # 列表元素乘2 [-8, -4, 0, 8]
print([x ** 2 for x in ls if x < 0]) # 正数元素平方[16, 4]
print([abs(x) for x in ls]) # 用abs()函数推导[4, 2, 0, 4]
示例8.3 读文件分析成绩
姓名,学号,C语言,Java,Python,VB,C++,总分
朱佳,0121701100511,75.2,93,66,85,88,407
李思,0121701100513,86,76,96,93,67,418
郑君,0121701100514, ,98,76, ,89,263
王雪,0121701100515,99,96,91,88,86,460
罗明,0121701100510,95,96,85,63,91,430
统计python课程成绩
def analysis_score(score_lst):
python_score = [x[PYTHON] for x in score_lst]
# 用推导式获取python课程数据的列表
print(python_score) # ['Python', 66, 96, 76, 91, 85]
avg = sum(python_score[1:])/len(python_score[1:])
print(f'{python_score[0]}课程平均成绩为{avg:.2f}')
# Python课程平均成绩为82.80
def analysis_score(score_lst):
score_all = sum(score_lst, []) # 用sum()转一维列表
python_score = score_all[4::8] # 用步长8切片取得Python数据
print(python_score) # ['Python', 66, 96, 76, 91, 85]
avg = sum(python_score[1:])/len(python_score[1:])
print(f'{python_score[0]}课程平均成绩为{avg:.2f}')
# Python课程平均成绩为82.80
完整程序如下:
# 定义符号常量,方便索引和切片
NAME = 0
TOTAL = -1
JAVA = 3
PYTHON = 4
def is_number(value):
"""当参数可转为数值型时,返回True"""
return value.strip().lstrip('-+').replace('.', '', 1).isnumeric()
def clean_data(data):
"""当参数中的字符串元素可转为数值型时,将其转为数值型
当值为整数时转为整数,值为浮点数时转为浮点数"""
for lst in data: # 遍历列表中的元素
for i in range(len(lst)):
if lst[i][0] == '0':
continue
elif lst[i] == ' ':
lst[i] = 0
elif is_number(lst[i]): # 如果是数值型字符串
lst[i] = eval(lst[i]) # 转为数值
def read_file(file):
"""读文件中的数据到列表中,每行数据根据逗号切分为列表"""
with open(file, 'r', encoding='utf-8') as fr:
score_lst = [line.strip().split(',') for line in fr]
clean_data(score_lst)
return score_lst
def sort_score(score_lst):
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: x[PYTHON])) # 根据总分降序排序
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: x[-1], reverse=True)) # 根据总分降序排序
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: (x[JAVA], x[TOTAL]),reverse=True))
print([score_lst[0]]+sorted(score_lst[1:], key=lambda x: (x[JAVA], -x[TOTAL]),reverse=True))
# 根据java降序排序,分数相同时按总分升序
def analysis_score(score_lst):
score_all = sum(score_lst, []) # 用sum()转一维列表
python_score = score_all[4::8] # 用步长8切片取得Python数据
print(python_score) # ['Python', 66, 96, 76, 91, 85]
avg = sum(python_score[1:])/len(python_score[1:])
print(f'{python_score[0]}课程平均成绩为{avg:.2f}')
# Python课程平均成绩为82.80
if __name__ == '__main__':
filename = '../data/csv/8.5 score.csv'
score = read_file(filename)
# print(score)
sort_score(score)
analysis_score(score)
文件中的数据如下:
王龙 94
张龙 89
梁龙 96
杨林 88
刘雪 92
魏琴 86
杜鑫 69
刘君 95
王娜 78
周华 85
with open('6.1 score.txt', 'r', encoding='utf-8') as data:
score = [int(line.strip().split()[1]) for line in data]
print(scores) # 输出列表# [94, 89, 96, 88, 92, 86, 69, 95, 78, 85]
用列表推导式可以方便的读取文件中数据到列表。文件内容如下:
姓名,C,Java,Python,C#
罗明,95,96,85,63
朱佳,75,93,66,85
李思,86,76,96,93
郑君,88,98,76,90
王雪,99,96,91,88
李立,82,66,100,77
scores = [] # 创建空列表
with open('score.csv', 'r', encoding='utf-8') as data:
for line in data: # 遍历文件对象
scores.append(line.strip().split(',')) # 字符串切分为列表
print(scores) # 输出二维列表
列表推导式实现
with open('score.csv', 'r', encoding='utf-8') as data:
scores = [line.strip().split(',') for line in data] # 列表推导式
print(scores) # 输出列表
文件中的数据转为列表的输出格式为:(为方便阅读,排版中加入回车)
[[‘姓名’, ‘C’, ‘Java’, ‘Python’, ‘C#’],
[‘罗明’, ‘95’, ‘96’, ‘85’, ‘63’],
[‘朱佳’, ‘75’, ‘93’, ‘66’, ‘85’],
[‘李思’, ‘86’, ‘76’, ‘96’, ‘93’],
[‘郑君’, ‘88’, ‘98’, ‘76’, ‘90’],
[‘王雪’, ‘99’, ‘96’, ‘91’, ‘88’],
[‘李立’, ‘82’, ‘66’, ‘100’, ‘77’]]
能力点4:生成器的创建与应用
reversed(seq)
zip(*iterables)
map(function, iterable, ...)
filter(function, iterable)
iter(object[, sentinel])
enumerate(iterable, start=0)
这些函数的返回值都是生成器对象
<*** object at 0x0000022777B67A00>
可以用next() 一个一个的取出里面的数据,也可以转列表查看,也可以解包裹查看,但只能使用一次,再使用需要重新创建生成器
city = zip(range(1, 4), ['北京', '上海', '天津', '重庆'])
print(city) # <zip object at 0x0000022777B67A00>
print(*city) # (1, '北京') (2, '上海') (3, '天津')
print(*city) # 空,无输出,生成器对象中的数据只能用一次
city = zip(range(1, 4), ['北京', '上海', '天津', '重庆'])
city_ls = list(city) # 生成器对象转列表后可以反复使用其中的的数据
print(city_ls) # [(1, '北京'), (2, '上海'), (3, '天津')]
print(*city_ls) # (1, '北京') (2, '上海') (3, '天津')
print(*city_ls) # (1, '北京') (2, '上海') (3, '天津')
6.3 列表综合应用
列表类型经常被用于数据处理,而数据的存在形式主要有两种,一种是文件形式,一种是数据库形式。对于文本文件中数据,可以用遍历的方法简单的读取,对于其他格式的数据文件或存储在数据库中的数据,可以借助Pandas库来读取。
Pandas是基于Numpy的一个开源库,提供了高性能和高可用性的数据结构用于解决数据分析问题,他纳入了大量的库和一些标准的数据模型,提供了可用于高效操作大型数据集的工具,是使Python成为强大而高效的数据分析工具的重要因素之一。Pandas兼容所有Python的数据类型,除此外,还支持两种数据结构:一维数组Series 和二维表格型数据结构DataFrame。本章,我们只介绍利用Pandas读取数据的相关知识。
Pandas是第三方库,使用之前需要通过 pip install pandas 安装。通常,Pandas的引用方式为:
import pandas as pd
Pandas输入输出API提供了对文本、二进制和结构化查询语言(SQL)等不同格式类型文件的读写函数,可以方便快速的读取本地文件,如csv、txt、json和html等文本文件、Excel文件以及关系型数据库中的数据。其主要方法如表6.2所示。
表 6.2 Pandas常用输入输出API
| 格式类型 | 数据描述 | 读 | 写 |
|---|---|---|---|
| 文本 | CSV | read_csv() | to_csv() |
| 文本 | JSON | read_json() | to_json() |
| 文本 | HTML | read_html() | to_html() |
| 二进制 | MS Excel | read_excel() | to_excel() |
| 二进制 | Python Pickle Format | read_pickle() | to_pickle() |
| SQL | SQL | read_sql() | to_sql() |
这些API可以方便的把各种类型的数据读取为Dataframe格式的数据,再用利用tolist()函数便可将其转为列表类型,这样就可以利用本章学习的方法进行数据分析和处理了。
6.3.1 读Excel文件中数据
用Pandas可以读取Excel文件中的数据为Dataframe类型,Excel文件的读取主要应用read_excel()方法,使用时可能需要先用“pip install xlrd”安装xlrd模块。read_excel()方法大部分参数都有默认值,只需要设置少量的参数便可以完成大部分的数据读取工作。其主要参数及其意义如下:
pd.read_excel(io, sheet_name=0, header=0, names=None, usecols=None, squeeze=False, converters=None, skiprows=None, nrows=None, skipfooter=0)
- io:Excel的存储路径
2. sheet_name:要读取的工作表名称,默认读取第一个工作表。可以是整型数字、列表名或SheetN。整型数字:目标sheet所在的位置,以0为起始,比如sheet_name = 1代表第2个工作表。列表名:目标sheet的名称,中英文皆可。SheetN:代表第N个sheet,S要大写,注意与整型数字的区别。
3. header:用哪一行作列名。默认为0 ,如果设置为[0,1],则表示将前两行作为多重索引。
4. names:自定义最终的列名。一般适用于Excel缺少列名,或者需要重新定义列名的情况。names的长度必须和Excel列长度一致,否则会报错。
5. index_col:用作索引的列
6. usecols:需要读取哪些列。可以使用整型,从0开始,如[0,2,3];也可以使用Excel传统的列名A、B等字母,如”A:C, E” = “A, B, C, E”,注意两边都包括。usecols 可避免读取全量数据,而是以分析需求为导向选择特定数据,提高效率。
7. squeeze:当数据仅包含一列。squeeze为True时,返回Series,反之返回DataFrame。
8. converters:强制规定列数据类型,主要用途是保留以文本形式存储的数字。
pandas默认将文本类的数据读取为整型,converters 参数可以指定各列数据的类型,如converters = {‘出货量’:float, ‘月份’:str }, 将“出货量”列数据类型规定为浮点数,“月份”列规定为字符串类型。
9. skiprows:跳过特定行。skiprows= n 跳过前n行; skiprows = [a, b, c] 跳过第a+1,b+1,c+1行(索引从0开始)。
10. nrows:需要读取的行数,nrows = n 读取前n行。
11. skipfooter: 跳过末尾行数,skipfooter = n 跳过末尾的n行。实例 6.6读取Excel文件中的证券数据
```python import pandas as pd
data = pd.read_excel(‘6.6 stock.xlsx’) # 读取数据为dataframe类型 print(data) ls = data.values.tolist() # dataframe数据转为列表类型 print(‘输出列表类型的数据\n’,ls) # 输出列表类型数据
<br />输出:<br /> 时间 ETF 华夏 博时 广发 券商 创业板<br />0 2018-01-15 4.265 4.560 1.650 1.736 0.920 1.634<br />1 2018-01-16 4.308 4.595 1.700 1.750 0.941 1.631<br />2 2018-01-17 4.295 4.590 1.699 1.740 0.973 1.639<br />3 2018-01-18 4.323 4.621 1.675 1.744 0.980 1.636<br />4 2018-01-19 4.335 4.632 1.683 1.740 1.002 1.630<br />输出列表类型的数据:<br />[[Timestamp('2018-01-15 00:00:00'),4.265, 4.56, 1.65, 1.736, 0.92, 1.634], <br /> [Timestamp('2018-01-16 00:00:00'), 4.308, 4.595, 1.7, 1.75, 0.941, 1.631], <br /> [Timestamp('2018-01-17 00:00:00'), 4.295, 4.59, 1.699, 1.74, 0.973, 1.639], <br /> [Timestamp('2018-01-18 00:00:00'), 4.323, 4.621, 1.675, 1.744, 0.98, 1.636], <br /> [Timestamp('2018-01-19 00:00:00'), 4.335, 4.632, 1.683, 1.74, 1.002, 1.63]]<br />值得注意的是,与遍历方法读取文件不同,用缺省参数读取的数据中,数值类型的数据直接被转为数值型,可以直接参与数值运算和统计分析。
```python
for lst in ls:
lst[0] = lst[0].strftime("%Y-%m-%d") # 日期时间格式化
print('输出列表类型的数据\n', ls) # 输出列表类型数据
[['2018-01-15', 4.265, 4.56, 1.65, 1.736, 0.92, 1.634],
['2018-01-16', 4.308, 4.595, 1.7, 1.75, 0.941, 1.631],
['2018-01-17', 4.295, 4.59, 1.699, 1.74, 0.973, 1.639],
['2018-01-18', 4.323, 4.621, 1.675, 1.744, 0.98, 1.636],
['2018-01-19', 4.335, 4.632, 1.683, 1.74, 1.002, 1.63]]
6.3.2 读文本文件中数据
读文本文件和csv文件进列表,对列表中的数据进行统计分析。将用常规分隔符分隔的文本文件读取到DataFrame可以使用read_csv()方法,其主要参数及意义如下:
pandas.read_csv(filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None, engine=None,encoding=None)
- filepath_or_buffer:带路径文件名或URL,字符串类型。
2. sep:分隔符,缺省值为’\t’,当文本中的分隔符不是制表符时,可用sep=’分隔符’来指定。Python可自动检测分隔符。
3. delimiter:参数sep的替代参数,缺省值为None。
4. header:整型或整型列表,用作列名的行号和数据的开头。
5. names:要使用的列名的列表,如果文件不包含标题行,则应显式传递header = None。
6. engine:使用解析器引擎,其值可为’c’或’python’。c引擎速度更快,而Python引擎目前功能更加完善。
7. encoding:默认None,编码在读/写时用UTF(例如’utf-8’)实例 6.7读取csv文件中的数据
```python import pandas as pd
score = pd.read_csv(‘6.7 score.csv’,encoding=’utf-8’) # dataframe print(score) # 查看数据格式 ls = score.values.tolist() # 转为列表类型 print(‘输出列表类型的数据\n’,ls) # 输出列表数据
输出:<br /> 姓名 C语言 Java Python C#<br />0 罗明 95 96 85 63<br />1 朱佳 75 93 66 85<br />2 李思 86 76 96 93<br />3 郑君 88 98 76 90<br />4 王雪 99 96 91 88<br />5 李立 82 66 100 77<br /> <br /> <br />输出列表类型的数据<br />[['罗明', 95, 96, 85, 63, 91], <br /> ['朱佳', 75, 93, 66, 85, 88], <br /> ['李思', 86, 76, 96, 93, 67], <br /> ['郑君', 88, 98, 76, 90, 89], <br /> ['王雪', 99, 96, 91, 88, 86]]
<a name="dC17B"></a>
### 6.3.3 读数据库中数据
在实际应用中,使用文本文件或Excel存储数据并不是最好的方式,我们能够对这些类型的文件中的数据能的操作非常有限,数据处理效率也不高,更常用的方式是将数据存储到数据库中,通过连接数据库进行相关操作。<br />目前应用最多的是关系型数据库,关系型数据库的主要构成是二维表。二维表包含多行多列,把一个表中的数据用Python表现出来,可以用一个列表表示多行,列表的每一个元素用一个元组表示二维表中的一行记录。比如一个二维表包含ID、姓名、年龄、籍贯、薪水,可以用以下形式表示:<br />[(1, '李明', 23, '吉林', 20000.00), <br /> (2, '韩雷', 26, '湖北', 25000.00), <br /> (3, '肖红', 30, '江西', 30000.00)]<br />这种表示方法无法直观的展示关系数据库的表结构,可以使用对象-关系映射 (ORM:Object-Relational Mapping)技术把关系数据库的表结构映射到对象上。在Python中,广泛应用的一个对象-关系映射框架是SQLAlchemy,这个框架可以为开发者提供高效的数据库访问设计和高性能的数据访问方法,实现了完整的企业级持久模型。<br />SQLAlchemy支持大部分主流数据库,如SQLite、MySQL、Postgres、Oracle、MS SQLServer 和 Firebird等。在使用之前,需要通过pip install sqlalchemy安装这个库。<br />SQLite是Python 内置的一个轻量级数据库,可以直接使用。使用其他数据库时,需要pip安装与数据库匹配的驱动,例如mysqlclient、 pymssql、 psycopg2、 cx-Oracle或 fdb等。只有安装数据库的驱动之后,才可以连接数据库对数据进行操作。本书以SQLite数据库作为范例进行讲解。<br />sqlalchemy.create_engine(*args, **kwargs)函数可被用于创建数据库引擎,数据库位置可用本地路径,也可用网络URL。
```python
from sqlalchemy import *
import pandas as pd
# 定义元信息,绑定到引擎,test.db为数据库名,./表示当前路径。
engine = create_engine('sqlite:///./test.db', echo=True)
metadata = MetaData(engine) # 绑定元信息
Pandas中的read_sql()方法可以查询数据库中的数据并直接返回DateFrame,在方法的参数中可以传入SQL语句。read_sql()方法的主要参数及意义如下:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
- sql : 表名或查询语句
2. con : 连接数据库的引擎,一般可以用SQLAlchemy之类的模块创建
3. columns : 需要从表中查询的列名的列表实例 6.8 读取SQLite数据库中的数据
SQLite数据库中文件“6.7 test.db”的score表中存储了学生的成绩数据,请将数据库中的数据读入到列表中。 ```python from sqlalchemy import * import pandas as pd
定义引擎,6.8 test.db为数据库名,./表示当前路径
engine = create_engine(‘sqlite:///./6.8 test.db’, echo=True) fromSql = pd.read_sql(‘score’, engine) # 从score表读数据dataframe print(fromSql) # 查看输出dataframe格式数据 ls = fromSql.values.tolist() # dataframe数据转为列表类型 print(‘输出列表类型的数据:\n’, ls) # 输出转为列表的数据
<br /> <br />输出列表类型的数据:<br /> 姓名 C语言 Java Python C# C++<br />0 罗明 95 96 85 63 91<br />1 朱佳 75 93 66 85 88<br />2 李思 86 76 96 93 67<br />3 郑君 88 98 76 90 89<br />4 王雪 99 96 91 88 86<br />转为列表类型后的输出为:<br />[['罗明', 95, 96, 85, 63, 91], <br /> ['朱佳', 75, 93, 66, 85, 88], <br /> ['李思', 86, 76, 96, 93, 67], <br /> ['郑君', 88, 98, 76, 90, 89], <br /> ['王雪', 99, 96, 91, 88, 86]]<br />类似的方法,也可以从json格式的文件中读取数据到列表:
```python
import pandas as pd
score = pd.read_json('6.8 scoreTest.json', encoding='utf-8')
print(score.values.tolist()) # dataframe数据转列表
常用内置函数
map(function, iterable, ...)
zip(iter1[, iter2 […]])
reversed(seq)
zip(*iterables)
filter(function, iterable)
iter(object[, sentinel])
enumerate(iterable, start=0)
any(iterable)
map(function, iterable, …)
返回一个将函数 function 应用于迭代器 iterable 中每一项并输出其结果的迭代器,可迭代输出其中数据或用 list 转为列表。
zip(*iterables)
创建一个聚合了来自每个可迭代对象中的元素的迭代器。
返回一个元组的迭代器,其中的第 i 个元组包含来自每个参数序列或可迭代对象的第 i 个元素。
用zip实现二维列表转置
with open('../data/csv/8.5 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
print(score_ls)
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['朱佳', '0121701100511', '75.2', '93', '66', '85', '88', '407'],
['李思', '0121701100513', '86', '76', '96', '93', '67', '418'],
['郑君', '0121701100514', ' ', '98', '76', ' ', '89', '263'],
['王雪', '0121701100515', '99', '96', '91', '88', '86', '460'],
['罗明', '0121701100510', '95', '96', '85', '63', '91', '430']]
with open('../data/csv/8.5 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
score_trans = list(zip(*score_ls))
print(score_trans)
[('姓名', '朱佳', '李思', '郑君', '王雪', '罗明'),
('学号', '0121701100511', '0121701100513', '0121701100514', '0121701100515', '0121701100510'),
('C语言', '75.2', '86', ' ', '99', '95'),
('Java', '93', '76', '98', '96', '96'),
('Python', '66', '96', '76', '91', '85'),
('VB', '85', '93', ' ', '88', '63'),
('C++', '88', '67', '89', '86', '91'),
('总分', '407', '418', '263', '460', '430')]
reversed(seq)
返回一个逆序排列的迭代器, seq 是要转换的序列,可以是str,tuple,list,range等。
iter(object)
返回一个迭代对象,可用list转为列表输出,也可以用 * 解包输出。object 必须是支持迭代(或序列)协议的集合对象。
enumerate(iterable, start=0)
返回一个枚举对象。iterable 必须是一个序列、迭代器或其他支持迭代的对象。
enumerate() 函数返回一个元组,里面包含一个计数值(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
print(enumerate(['北京', '上海', '天津', '重庆'], start=1))
# <enumerate object at 0x000001B25185F6C0>
print(list(enumerate(['北京', '上海', '天津', '重庆'], start=1)))
# [(1, '北京'), (2, '上海'), (3, '天津'), (4, '重庆')]
print(list(zip(range(1, 5), ['北京', '上海', '天津', '重庆'])))
# [(1, '北京'), (2, '上海'), (3, '天津'), (4, '重庆')]
all(iterable)
如果可迭代对象 iterable 的所有元素为真或迭代器为空,返回 True,否则返回False 。
print(all([])) # 空的迭代器的值为 True
print(all([1,2,0,4])) # 包含值为 0 的元素时值为False
print(all([1,2,'',4])) # 包含空字符串的元素时值为False
print(all([1,2,'Yes',4])) # 全部元素值都是True时结果为True
pwd=input()
user=input()
if all([pwd=='123456', user=='root']):
print('登录成功')
else:
print('登录失败')
any(iterable)
如果可迭代对象 iterable 的任一元素为真则返回 True。 如果迭代器为空,返回 False。
print(any([])) # 空的迭代器的值为 False
print(any([1,2,0,4])) # 包含值不为 0 的元素时结果为True
print(any([0.0,0,'',[]])) # 全部元素值都是False时结果为False
filter(function, iterable)
用 函数 function 返回可迭代对象 iterable 中所有值为 True 的元素,构建一个新的迭代器。
请注意, filter(function, iterable) 相当于一个生成器表达式,当 function 不是 None 的时候为 (item for item in iterable if function(item));function 是 None 的时候为 (item for item in iterable if item) 。
score = {'xiaobai':50,'xiaohei':30,'xiaolan':80,'xiaojun':100,'xiaoming':60}
result=filter(lambda score:score>60,score.values())
print(list(result)) # [80, 100] 返回及格的成绩
name = ["vasp", "castep", "turing"]
filter_name = list(filter(lambda x: len(x) < 5, name))
print(filter_name) # ['vasp'] 返回长度小于5的字符串
result=filter(lambda x:x % 7 ==0 and x % 13 ==0,range(1,1000))
print(list(result))
# [91, 182, 273, 364, 455, 546, 637, 728, 819, 910] 返回1000以内能被7和13同时整除的数
计算每个同学4 门课程成绩的平均成绩,将平均成绩置于课程成绩后一列,按照平均分升序排序后输出。
根据以下输入要求,输出相应的数据:
1.输出平均分最高的同学名字与平均成绩,名字与分数间用一个空格分隔;
2.输出平均分最低的同学名字与平均成绩,名字与分数间用一个空格分隔
3.输出按平均分从低到高的排序数据,要求每个数据之间以空格间隔,每行结尾无空格。
4.输入一个学生的名字,输出该名同学所在行的的全部数据,各数据项间用一个空格分隔,结尾无空格,
5.如输入的姓名在文件中不存在,输出 “姓名不存在”
0121801101266,刘雯,92,73,72,64
0121801101077,张佳喜,81,97,61,98
0121801101249,张红发,88,66,71,85
0121813570483,王昊煜,93,73,71,90
0121801101092,曹洋,85,62,71,76
0121801101271,徐肖剑,83,73,97,96
0121801101565,王雅楠,94,82,96,98
0121801101864,胡天旭,63,99,78,89
0121801101930,苏琪琦,67,61,68,74
0121813570392,项子烜,64,72,85,96
0121813570159,黄碧君,94,64,92,64
0121801101664,李欣,62,63,92,87
0121801101825,何乐,67,97,74,70
0121801101707,兰贵能,70,89,77,85
0121801101950,周淼,91,72,72,87
0121801101345,苏鹏,100,67,83,81
0121813570765,张周钊,90,80,100,74
0121713590987,张孜翰,61,85,60,74
0121801101753,张旭,87,100,69,65
0121801101531,佘玉龙,73,89,81,93
score.txt
1.读取文件到二维列表(列表创建)
2.计算每位同学的平均成绩并附加到课程后一列(插入)
3.根据平均分对二维列表进行升序排序
4.按平均分从低到高的输出数据(切片)
5.根据姓名查询学生的数据(遍历)
1.读取文件到二维列表(列表创建)
def read_txt_lst(filename):
"""接收文件名为参数,读文件中的数据到二维列表,返回二维列表"""
with open(filename, 'r', encoding='utf-8') as fr:
score_lst = [i.strip().split(',') for i in fr]
return score_lst
2.计算每位同学的平均成绩并附加到课程后一列(插入)
def score_add_avg(score_lst):
"""接收包含成绩的二维列表,为每个子列表中增加平均成绩的元素
返回包含平均成绩的三维列表"""
score_avg_lst = []
for x in score_lst:
avg = sum(map(int, x[2:])) / len(x[2:])
x.append(avg)
score_avg_lst.append(x)
return score_avg_lst
用列表推导式时,可以用列表拼接
因append()无返回值,此处不可用
def score_add_avg(score_lst):
"""接收包含成绩的二维列表,为每个子列表中增加数值型的平均成绩的元素
返回包含平均成绩的二维列表"""
score_avg_lst = [x+[sum(map(int, x[2:])) / len(x[2:])] for x in score_lst]
return score_avg_lst
3.根据平均分对二维列表进行升序排序
def sort_score(sort_lst):
"""接收包含成绩的二维列表,根据平均成绩对二维列表进行排序。
返回升序排序后的二维列表"""
sort_lst.sort(key=lambda x: x[6])
return sort_lst
4.按平均分从低到高的输出数据(切片)
def output_all(sort_lst):
"""按平均分从低到高输出数据"""
for score_ls in sort_lst:
print(*score_ls)
5.根据姓名查询学生的数据(遍历)
def query_student(sort_lst, stu_name):
"""接收二维列表和一个学生名参数,若学生名存在,
输出该生所在行的全部数据,否则输出姓名不存在"""
for line in sort_lst:
if stu_name in line:
return line
else:
return None
def read_txt_lst(filename):
"""接收文件名为参数,读文件中的数据到二维列表,返回二维列表"""
with open(filename, 'r', encoding='utf-8') as fr:
score_lst = [i.strip().split(',') for i in fr]
return score_lst
def score_add_avg(score_lst):
"""接收包含成绩的二维列表,为每个子列表中增加平均成绩的元素
返回包含平均成绩的三维列表"""
score_avg_lst = []
for x in score_lst:
avg = sum(map(int, x[2:])) / len(x[2:])
x.append(avg)
score_avg_lst.append(x)
return score_avg_lst
def sort_score(sort_lst):
"""接收包含成绩的二维列表,根据平均成绩对二维列表进行排序。
返回升序排序后的二维列表"""
sort_lst.sort(key=lambda x: x[6])
return sort_lst
def output_all(sort_lst):
"""按平均分从低到高输出数据"""
for score_ls in sort_lst:
print(*score_ls)
def query_student(sort_lst, stu_name):
"""接收二维列表和一个学生名参数,若学生名存在,
输出该生所在行的全部数据,否则输出姓名不存在"""
for line in sort_lst:
if stu_name in line:
return line
else:
return None
if __name__ == '__main__':
file = '6.5 score.txt'
score = read_txt_lst(file)
score_with_avg = score_add_avg(score)
sorted_score = sort_score(score_with_avg)
print(sorted_score)
print(sorted_score[-1][1], sorted_score[-1][-1])
print(sorted_score[0][1], sorted_score[0][-1])
output_all(sorted_score)
student_name = input()
info = query_student(sorted_score, student_name)
if info:
print(*info)
else:
print('姓名不存在')

若有收获,就点个赞吧
0 人点赞
