第7章 集合与映射类型.pptx
点击查看【bilibili】
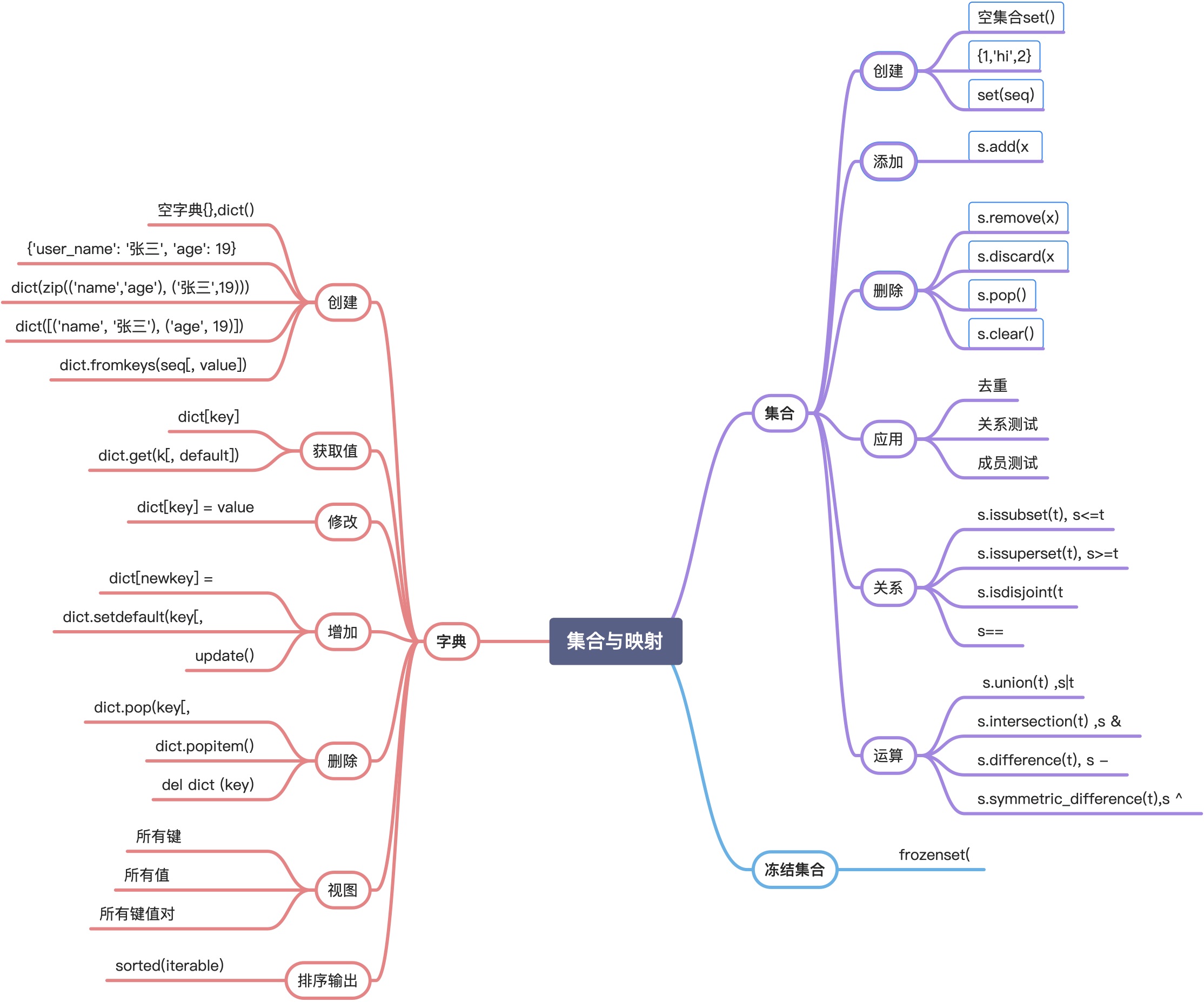
集合
可遍历结构,元素为不可变数据(数值、字符串、range、元组等)
无固定顺序:不支持索引和切片
不重复:可利用集合去除重复数据
set(){'张三', '小明','张明'}{[1, 2, 3], 1, 2, 3.14, 'hello'} # 元素必须为不可变数据类型,TypeError: unhashable type: 'list'
能力点1: 集合的创建
非空集合通过将一系列用逗号分隔的数据放在一对大括号中的方法创建,将集合类型数据赋值给变量即可创建并使用一个集合变量。
city_set = {'吉林', '武汉', '北京'} # 将集合数据赋值给变量,直接创建集合print(city_set) # {'北京', '吉林', '武汉'}
空集合使用 set() 函数创建和表示,集合出现晚于字典,所以不能直接使用“{}”来创建和表示空集合。
empty_set = set() # set()函数创建一个空集合,不能使用{}创建和表示print(empty_set) # 输出 set(),表示一个空集合
将字符串、列表、元组、推导式、迭代器或字典等支持迭代的对象做为set()函数的参数,可以得到一个集合。
print(set([78, 78, 78, 94, 65])) # 将列表转为集合并去除重复元素 {65, 94, 78}print(set('cheeseshop')) # 字符串转集合{'e', 'h', 's', 'p', 'o', 'c'}
与列表推导式类似,集合也可以通过集合推导式创建。
gold_medal = [['第1金', '射击'], ['第2金', '举重'], ['第3金', '击剑'], ['第4金', '跳水'], ['第5金', '举重'], ['第6金', '举重'], ['第7金', '射击'], ['第8金', '跳水'], ['第9金', '射击'], ['第10金', '赛艇']]sports_set = {x[1] for x in gold_medal} # 集合推导式print(sports_set) # {'跳水', '赛艇', '击剑', '射击', '举重'}, 获奖的项目
集合是一种可遍历结构,可以用在for循环中用于数据的遍历。
集合具有无序且不重复的特点,基本功能包括关系测试和消除重复元素。
能力点2:利用集合去除重复数据
实例 7.1 计算不同高度植株平均高度
Tom教授是研究植物的专家,一天,他让他的助手李华计算他的实验田中种植的不同高度的向日葵的高度平均值。植株的数量大于0 小于等于100,在一行中输入用空格分隔的若干个向日葵高度数据,输出其不同高度的平均值,结果保留2位小数。
height_ls = input().split() # 多个用空格分隔的输入切分为列表height_set = {float(x) for x in height_ls} # 集合推导式,元素转浮点数,去掉重复数据avg_height = sum(height_set) / len(height_set) # 高度总和除不同高度的数量print(round(avg_height, 2)) # 输出平均高度# 156 188 161 154 178 175 161 175 174 188# 169.43
也可以用split()将输入切分为列表后,用map()直接将列表元素一一映射为浮点数,再置于set()函数中转为集合类型,去掉重复元素。
height_set = set(map(float, input().split())) # 输入切分为列表后映射元素为浮点数,转集合去掉重复元素avg_height = sum(height_set) / len(height_set) # 高度总和除不同高度的数量print(round(avg_height, 2)) # 输出平均高度
实例 7.2 奥运获奖统计
奥运奖牌.txt
文件奥运奖牌.txt中记录了2021年奥运会中国代表队获奖情况,包括奖牌种类、获奖日期、运动员、项目,中间用制表符“\t”分隔。请统计一共有哪些项目获得奖牌?
顺序 日期 运动员/运动队 项目第1金 2021/7/24 杨倩 射击第2金 2021/7/24 侯志慧 举重第3金 2021/7/24 孙一文 击剑第4金 2021/7/25 施廷懋/王涵 跳水......第16铜 2021/8/2 周倩 摔跤第17铜 2021/8/6 刘虹 竞走第18铜 2021/8/7 龚莉 空手道
with open('../data/txt/奥运奖牌.txt', 'r', encoding='utf-8') as medals:sports_ls = [x.strip().split()[-1] for x in medals] # 遍历文件对象,取每行最后一个数据推导出列表print(sports_ls[1:]) # 略过标题行,['射击', '举重', '击剑', ... '空手道']print(len(sports_ls) - 1) # 所有项目获奖总数
with open('../data/txt/奥运奖牌.txt', 'r', encoding='utf-8') as medals:sports_set = {x.strip().split()[-1] for x in medals} # 遍历文件对象,取每行最后一个数据推导出集合print(sports_set) # {'空手道', '田径女子链球', '蹦床', '竞走'...}print(len(sports_set)-1) # 获奖的项目数量,同一项目获多个奖只计一次,去掉标题
可以用内置函数 len(s) 获取集合s中数据元素的个数,可以根据对象进入集合前后长度是否发生变化判定其中是否存在重复的元素。
实例 7.3 奇特的四位数
一个四位数,各位数字互不相同,所有数字之和等于6,并且这个数是11的倍数。 满足这种要求的四位数有多少个?各是什么?
想知道一个数字 num 中是否有重复数字,可用 str(num) 将这个数转为字符串类型,用 map(int, str(num))将字符串中的每个数字字符映射为整数类型,再用set()函数将其转为集合。
num_set = set(map(int, str(num))) # 以当前数上每位数字为元素构建集合num_set
若各位上有相同数字存在,重复数字会被去掉,则生成的集合长度必小于4,所以用len()测试集合元素数量,当结果为4时,当前数中不存在重复数字。
if len(num_set) == 4: # num 中无重复数字
因超过3210的数中各位数字之和必大于6,并不需要从0000遍历到9999,只需要遍历到3210即可,减少搜索空间,提高效率。若该数对 11 取模的值等于 0,集合元素求和结果为6,且集合长度为4,则是满足要求的数。
sum(num_set) == 6 # 各位数加和为6
完整参考代码如下:
num_ls = []for num in range(1000, 3211): # 超3210的数各位数字和必大于6,减小搜索空间num_set = set(map(int, str(num))) # 以当前数上每位数字为元素构建集合num_setif num % 11 == 0 and sum(num_set) == 6 and len(num_set) == 4:num_ls.append(num) # 符合条件的数字加到列表num_ls里print(len(num_ls)) # 列表长度就是符合条件的数字的个数 6print(num_ls) # [1023, 1320, 2013, 2310, 3102, 3201]
能力点3 可变集合类型的操作
可变集合提供了一些关于元素更新、删除等相关操作的方法,常用操作及其方法描述如表7.1所示。
表 7.1 集合常用操作方法
| 方法 | 描述 |
|---|---|
| s.add(x) | 向集合 s 中添加一个元素 x |
| s.remove(x) | 从集合 s 中删除对象 x;如果 x 不是集合 s 中的元素(x not in s),将引发 KeyError 异常。使用s.remove(x) 删除元素时,建议先做存在性测试 |
| s.discard(x) | 如果 x 是集合 s 中的元素,从集合 s 中删除对象 x,如果s中不存在x也不会报错。 |
| s.pop() | 无参数,从集合中移除任意一个元素,返回值为被移除的元素,如果集合为空则会引发 KeyError异常。 |
| s.clear() | 删除集合 s 中的所有元素。 |
- 添加元素 s.add(x)
向集合 s 中添加一个元素x 的方法只有一个 s.add(x)
- 删除元素 s.remove(x) 、s.discard(x)、s.pop()、s.clear()
删除集合s 中的一个指定元素x 的方法是s.remove(x) 或s.discard(x)
二者的区别是当元素x 在集合s 中不存在时,s.remove(x) 会触发KeyError异常,而s.discard(x) 不会触发异常。
2.1 s.remove(x)
s = set('python')s.discard('Z') # 集合不存在元素'Z',不报错s.remove('A') # 集合不存在元素'A',返回 KeyError: 'A'
s.remove(‘A’) # 集合不存在元素’A’,返回 KeyError: ‘A’
s = set('python')if 'A' in s:s.remove('A') # 若集合中存在元素A,删除'A',避免异常
2.2 s.discard(x)
使用s.remove(x) 删除元素时,建议先做存在性测试,以避免触发异常导致程序无法正常结束。
2.3 s.pop()
s.pop() 方法可以从集合s 中随机移除一个元素,其返回值是被移除的元素。
用s.pop() 方法时,如果集合为空则会触发KeyError。
s = set() # s是空集合s.pop()
s.pop()<br />KeyError: 'pop from an empty set'
2.4 s.clear()
s.clear() 方法可用于删除集合的所有元素,清空集合,只保留空集合对象;
- del 命令
del 命令可用于删除集合对象
实例 7.2 也可以先创建空集合,遍历文件对象,每行切分为列表后取最后一个元素(获奖项目)加入到集合中,若加入元素在集合中已经存在了,自动忽略,只保留一份。因为遍历时包含了标题行,所以用discard()方法删除集合中元素“项目”,集合中仅保留获奖体育项目名。
sports_set = set() # 创建空集合,不可用{},{}表示空字典
with open('../data/txt/奥运奖牌.txt', 'r', encoding='utf-8') as medals:
for x in medals:
sports_set.add(x.strip().split()[-1]) # 遍历文件对象,取每行最后一个数据加入到集合
sports_set.discard('项目') # 删除标题行中最后一个数据'项目'
print(sports_set) # {'射击', '跳水', '举重', '羽毛球'...}
print(len(sports_set)) # 获奖的项目数量24,同一项目获多个奖只计一次
能力点4 集合成员运算
集合支持成员运算,可用 x in s 和 x not in s操作判断数据x是否是集合s的成员。
实例 7.4 查询奥运项目是否获奖
在实例7.2的基础上,增加查询功能,用户输入一个项目名,查询是否是奥运获奖项目。
def medals_game():
"""无参数,读取文件奥运奖牌.txt,将获奖项目名加入到集合中,返回集合"""
with open('../data/txt/奥运奖牌.txt', 'r', encoding='utf-8') as medals:
sports_set = {x.strip().split()[-1] for x in medals} # 构建获奖项目名集合
sports_set.discard('项目') # 删除标题行中最后一个数据'项目'
return sports_set # 返回获奖项目的集合
def query(sports_name):
"""接受一个项目名为参数,查询是否是获奖项目,返回字符串"""
if sports_name in medals_set: # 查询项目名在集合中是否存在
return f'{sports_name}是获奖项目'
else:
return f'{sports_name}项目未获奖'
if __name__ == '__main__':
medals_set = medals_game() # 调用函数获取获奖项目名集合
sports = input() # 输入一个体育项目名
print(query(sports)) # 查询是否是获奖项目并输出
能力点5 集合关系
当一个集合s中的元素包含另一个集合t中的所有元素时,称集合s是集合t的超集(s >= t),或反过来称t是s的子集(s <= t)。当两个集合中元素相同时,两个集合等价(s == t)。集合的关系运算方法和含义如表7.2所示。
表 7.2 集合的关系运算
| 方法 | 符号 | 含义 |
|---|---|---|
| s.issubset(t) | s <= t | s是否是t的子集,是返回True,否则返回False |
| s < t | s是否是t的真子集,是返回True,否则返回False | |
| s.issuperset(t) | s >= t | s是否是t的超集,是返回True,否则返回False |
| s > t | s是否是真包含t,是返回True,否则返回False | |
| s.isdisjoint(t) | s和t是否无共同元素,是返回True,否则返回False | |
| s == t | s是否和t相等,是返回True,否则返回False |
- s.issubset(t) 子集
s <= t :集合 s 是否是集合 t 的子集,是返回True,否则返回False
s < t : 集合 s 是否是集合 t 的真子集,是返回True,否则返回False
ip 地址是32位二进制数,若其中字符都是’0’ 或 ‘1’,且长度为32,则合法
ip_bin = input()
if len(ip_bin) == 32 and {'0', '1'} >= set(ip_bin):
print('输入的ip地址合法')
- s.issuperset(t) 超集
s >= t :集合 s是否是集合 t的超集,是返回True,否则返回False
s > t : 集合 s是否是真包含集合 t,是返回True,否则返回Falseip_bin = input() if len(ip_bin) == 32 and set(ip_bin) <= {'0', '1'}: print('输入的ip地址合法') - s.isdisjoint(t)
s和t是否无共同元素,是返回True,否则返回False
s == t:集合 s 是否和集合 t 相等,是返回True,否则返回Falses = set('python') # {'t', 'n', 'o', 'h', 'p', 'y'} t = {'o', 'y', 'p', 'g'} print(s == t) # False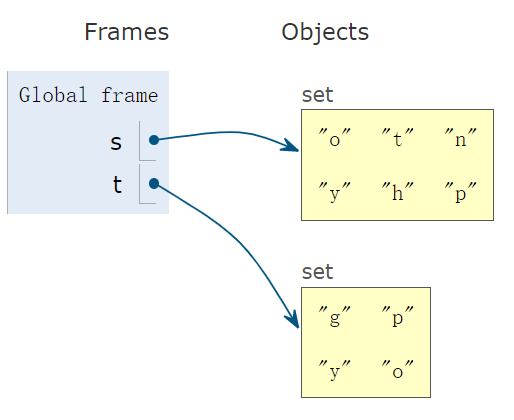
s = set('posh') t = set('shop') print(s == t) # True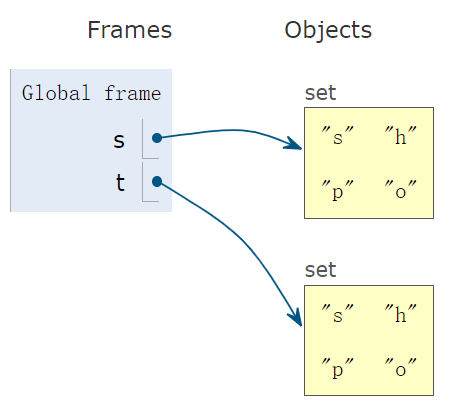
实例 7.5 二进制地址转十进制
一个IP地址是由四个字节(每个字节8个位)的二进制数组成。请将32位二进制数表示的 IP 地址转换为十进制格式表示的 IP 地址输出。十进制格式的IP地址由用“.”分隔开4个十进制数组成。如果输入的数字不足32位或超过32位或输入的数字中有非0和1的数字时输出“data error!”
输入的字符串未必符合法,可能位数不是32,也可能包含其他字符,若把IP地址字符串转为集合,则其中重复的字符会被去掉,若为合法IP地址,集合只能是{‘1’}、{‘0’}和{‘0’,’1’}中的一个,这里可以利用集合关系方便的判定输入中是否包括非 ‘0’、’1’ 的字符。
```python def check_ip(ip_bin): “””接受字符串,判定是否为合法IP,当其合法时返回其对应的十进制IP,否则返回’data error!’””” if len(ip_bin) == 32 and set(ip_bin) <= {‘0’, ‘1’}:if set(ip) <= {'0','1'}: # 合法ip set(ip) 的结果只能是 {'0'},{'1'},{'0','1'}中的一个
else:ip_ls = [] for i in range(4): # 循环取8个二进制字符,转十进制数后转字符串拼接到一起 ip_ls.append(str(int(ip_bin [i * 8:(i + 1) * 8], 2))) ip_dec = '.'.join(ip_ls) return ip_dec # 输入合法时返回其对应的十进制IPreturn 'data error!' # 输入不合法时返回'data error!'
if name == ‘main‘: IP = input() print(check_ip(IP))
<br />输入:11011110111011000010101101110001<br />输出:222.236.43.113<br />输入:11001a00100161000091010101110010<br />输出:data error!
<a name="DRZBG"></a>
# 能力点6 集合运算
Python中的集合和数学中的集合概念基本一致,也支持集合的交、差、并等操作,使用这些运算可以很方便的处理数学中的集合操作。集合运算的方法与含义如表7.3所示。<br />1. union(*others) 或set | other<br />返回一个新的集合,其中包含来自原集合以及 others 指定的所有集合中的元素。<br />2. intersection(*others) 或set & other<br />返回一个新的集合,其中包含原集合以及 others 指定的所有集合中共有的元素。<br />3. difference(*others) 或set - other<br />返回一个新的集合,其中包含原集合中在 others 指定的其他集合中不存在的元素。<br />4. symmetric_difference(other) 或set ^ other<br />返回一个新的集合,其中的元素或属于原集合或属于 other 指定的其他集合,但不能同时属于两者。<br />表 7.3 集合运算的方法与含义
| 操作方法 | 符号 | 含义 |
| --- | --- | --- |
| s.union(t) | s | t | 返回新集合,集合元素为 s 和 t 的并集 |
| s.intersection(t) | s & t | 返回新集合,集合元素为 s 和 t 的交集 |
| s.difference(t) | s - t | 返回新集合,集合元素为 s 和 t 的差集 |
| s.symmetric_difference(t) | s ^ t | 返回新集合,集合元素为 s 和 t 的对称差,即存在于 s 和 t 中的非交集数据 |
需要注意的是,union()、 intersection()、 difference()以及 、 和 issuperset() 方法可以接受任意可迭代对象作为参数。但使用他们所对应的运算符方式进行运算时,则要求运算符两侧的操作数都是集合。这种规定排除了容易出错的构造形式,如 set('abc') & 'cbs',推荐可读性更强的函数方法,如: set('abc').intersection('cbs')。<br />集合运算示例如下:
```python
s = set('bookshop') # {'o', 'k', 'h', 's', 'b', 'p'}
t = set('cheeseshop') # {'o', 'e', 'c', 'h', 's', 'p'}
print(s.union(t)) # s | t,{'p','b','o','s','e','c','h','k'}
print(s.intersection(t)) # s & t,集合共有的元素{'o', 'h', 's', 'p'}
print(s.difference(t)) # s - t,s中存在t中不存在的元素{'b', 'k'}
print(s.symmetric_difference(t))
# s ^ t,只属于s或t的元素{'b', 'e', 'c', 'k'}
如果左右两个操作数的类型相同,即都是可变集合或不可变集合,则所产生的结果类型是相同的,但如果左右两个操作数的类型不相同(左操作数是 set,右操作数是 frozenset,或相反情况),则所产生的结果类型与左操作数的类型相同。
实际上Python中也提供了一些集合的操作方法,这些操作方法无返回值,直接作用于集合对象,相当于运算同步赋值。集合标准操作方法及运算符如表7.4所示。
表 7.4 集合标准操作方法及符号运算
| 方法 | 符号 | 描述 |
|---|---|---|
| s.update(t) | s = s | t | s中的元素更新为属于 s 或 t 的成员,即 s与 t的并集。 |
| s.intersection_update(t) | s = s & t | s中的元素更新为共同属于 s和t的元素,即 s与 t的交集。 |
| s.difference_update(t) | s = s - t | s中的元素更新为属于 s 但不包含在 t 中的元素,即 s与 t的差集。 |
| s.symmetric_difference_update(t) | s = s ^ t | s中的元素更新为那些包含在 s 或 t 中,但不 是 s和 t 共有的元素。 |
使用集合操作方法时,参数可以是集合或可迭代数据对象;用符号操作时,参与运算的两个对象必须都是集合。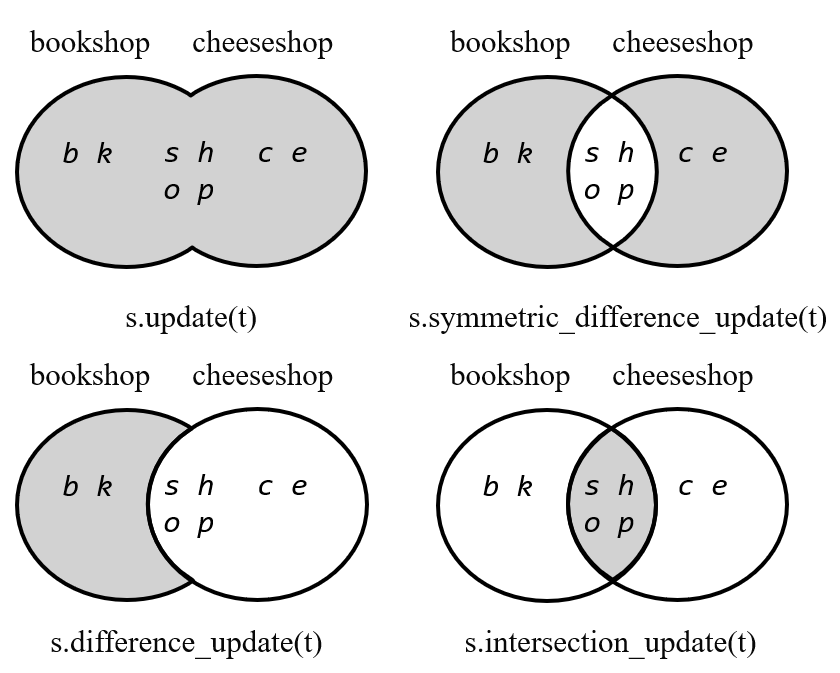
图 7.3 集合操作
实例 7.6 手机销售分析
6.3 手机销售分析.xlsx
文件中包含有2018和2019手机销售榜单数据(市场份额百分数)
输出两年都上榜的品牌、两年上榜的所有品牌、2019年新上榜品牌、2019年新上榜与落榜品牌。
利用集合的并、交、差补和对称差分可以完成题目要求的分析工作。
利用前面学习的用pandas库读取Excel文件中数据、用tolist()方法转为列表的方法可以获取其中的手机品牌列表,将其转为集合。excel 是要读取数据的文件名,sheet_name 是要读取的工作薄序号,1表示读取第2个工作薄,值缺省时读取第1个工作薄。values.tolist()可将dataframe类型数据转为列表类型。
sale2018 = pd.read_excel(excel, sheet_name=1) # 读数据进dataframe
sale2018 = sale2018.values.tolist() # dataframe类型转列表
这两行语句也可以合并为一行,读取后直接将值转为列表:
sale2019 = pd.read_excel(excel).values.tolist() # 读数据转列表
可以使用集合推导式根据列表中的数据创建集合:
set2019 = {x[0] for x in sale2019} # 集合推导式,2019年榜单集合
利用集合的并、交、差补和对称差分可以完成题目要求的分析工作。
两年都上榜的手机品牌,交集s & t 或 s.intersection(t)
s2019 & s2018 # 两年都上榜的手机,交集s.intersection(t)
两年上榜的所有手机品牌,并集s | t 或s.union(t)
s2019 | s2018 # 两年上榜的所有品牌,并集s.union(t)
新上榜手机品牌,差补s – t 或 s.difference(t)
s2019 - s2018 # 新上榜品牌,差补s.difference(t)
新上榜与落榜手机品牌,对称差分, s ^ t 或 s.symmetric_difference(t)
s2019 ^ s2018 # 新上榜与落榜品牌,对称差分,s.symmetric_difference(t)
phone_2018 = {'华为', 'OPPO', 'Samsung', 'Apple', '魅族', '小米', 'vivo'}
phone_2021 = {'荣耀', '华为', 'OPPO', 'Apple', 'realme', '小米', 'vivo'}
print(f'两年都上榜的品牌:{phone_2021 & phone_2018}')
# 两年都上榜的品牌:{'vivo', 'Apple', 'OPPO', '小米', '华为'}
print(f'两年上榜的所有品牌:{phone_2021 | phone_2018}')
# 两年上榜的所有品牌:{'vivo', 'Apple', '荣耀', 'OPPO', 'Samsung', '小米', 'realme', '魅族', '华为'}
print(f'2021年新上榜品牌:{phone_2021 - phone_2018}')
# 2021年新上榜品牌:{'realme', '荣耀'}
print(f'新上榜与落榜品牌:{phone_2021 ^ phone_2018}')
# 新上榜与落榜品牌:{'Samsung', '魅族', '荣耀', 'realme'}
完整参考程序:
# -------- ------- --------
# @File : 手机销售分析.py
# @Author : 赵广辉
# @Contact: vasp@qq.com
# @Company: 武汉理工大学
# @Version: 1.0
# @Modify : 2022/05/28 10:39
# Python程序设计基础,高等教育出版社
# -------- ------- --------
import pandas as pd
def rank(s2019, s2018):
"""接收两个集合为参数,做集合运算,输出两年都上榜的手机品牌、两年上榜的所有品牌、2019年新上榜品牌、新上榜与落榜品牌。"""
print(f'两年都上榜的手机品牌:{s2019 & s2018}')
print(f'两年上榜的所有品牌:{s2019 | s2018}')
print(f'2019年新上榜品牌:{s2019 - s2018}')
print(f'新上榜与落榜品牌:{s2019 ^ s2018}')
def data(excel):
"""接收Excel文件名,读excel文件中两个工作表,分别将数据放入两个集合并返回。"""
sale2018_df = pd.read_excel(excel, sheet_name=1) # 读数据进dataframe
sale2018_ls = sale2018_df.values.tolist() # dataframe类型转列表
sale2019_ls = pd.read_excel(excel, sheet_name=0).values.tolist() # 读数据转列表
sale2019_set = {x[0] for x in sale2019_ls} # 集合推导式,2019年榜单集合
sale2018_set = {x[0] for x in sale2018_ls} # 集合推导式,2018年榜单集合
return sale2019_set, sale2018_set
if __name__ == '__main__':
excelName = '../data/xlsx/6.3 手机销售分析.xlsx' # 定义文件名,方便修改
sale_2019_set, sale_2018_set = data(excelName) # 调用函数读数据转格式
rank(sale_2019_set, sale_2018_set) # 调用函数运算和输出
输出:
两年都上榜的手机品牌: {'小米', 'Apple', 'vivo', 'OPPO', '魅族', '三星', '华为'}
两年上榜的所有品牌: {'小米', 'Apple', '金立', 'vivo', 'OPPO', '魅族', '中兴', '联想', '三星', '华为'}
2019年新上榜品牌: {'中兴', '联想'}
新上榜与落榜品牌: {'金立', '中兴', '联想'}
映射类型
能力点7 字典的创建
创建一个不包含任何值的空字典,使用以下方法中的一种:
一是将用大括号界定的0个或多个包含键值对的元素赋值给一个对象;
dic = {} # 一对不包含任何数据的“{}”创建一个空字典数据
dic_user = {'user_name': '张三', 'age': 19, 'gender': 'M'} # 将一个字典数据赋值给一个变量
二是用字典构造器 dict() 函数创建字典
没有参数时创建空字典,参数为赋值表达式时,变量名和值被转为字典的键和值;参数是zip()函数时,zip()函数的两个参数序列将分别组合成字典的键值对。
dic = dict() # 使用字典构造器创建一个空字典数据
# 赋值表达式转键值对,变量名转键名,不加引号
dic_user1 = dict(user_name='张三', age=19, gender='M')
# 通过包含两个元素(键和值)的序列,创建字典
dic_user2 = dict([('user_name', '张三'), ('age', 19), ('gender', 'M')])
# 用zip()函数,产生包含两个元素的序列,分别组合为键值对,创建字典
dic_user3 = dict(zip(('user_name', 'age', 'gender'), ('张三', 19, 'M')))
# 上述三种方法都得到以下字典
{'user_name': '张三', 'age': 19, 'gender': 'M'}
字典自有方法 fromkeys() 可以根据已有键序列,快速创建一个包含相同值的字典,当value缺省时,值为None。参数seq 是字典键的列表,value是可选参数,设置键序列(seq)的值。这里的 value 只能是一个值,可以是数值、字符串、列表或字典等。fromkeys() 方法语法如下:
dict.fromkeys(seq[, value])
例如下:
course = ['Python', 'Java', 'C']
score = dict.fromkeys(course, 60) # 值均为60
print(score) # {'Python': 60, 'Java': 60, 'C': 60}
和其他序列和集合类数据一样,字典也可以使用推导式快速的生成字典数据序列。示例如下:
name_lst = [('user_name', '张三'), ('age', 19), ('gender', 'M')]
name_dic = {x[0]: x[1] for x in name_lst} # 用推导式从列表生成字典x = ('user_name', '张三')...
print(name_dic) # {'user_name': '张三', 'age': 19, 'gender': 'M'}
name_dic = {k: v for k, v in name_lst} # 用推导式从列表生成字典: k, v=('user_name', '张三')...
print(name_dic) # {'user_name': '张三', 'age': 19, 'gender': 'M'}
字典中的键必须具有唯一性,不允许重复的键存在。创建一个字典时,当字典内部出现了键相同的两个及以上键值对时,后加入的元素值将覆盖前面的同键元素值,保留最后一个键值对作为字典中的数据元素。
name_dic = {'user_name': '张三', 'age': 19, 'gender': 'M', 'user_name': '钱五'}
print(name_dic) # {'user_name': '钱五', 'age': 19, 'gender': 'M'}
实例 7.7 读文件创建字典
文件”国家与首都”中每行由逗号分隔的国家名和首都名组成,读取文件的内容,构建以国家名为键,首都名为值的字典。
中国,北京
日本,东京
英国,伦敦
......
country_dic = {} # 创建空字典
with open('../data/csv/6.5 国家与首都.csv', 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象,x依次取值为文件的一行的字符串
ls = x.strip().split(',') # 将字符串根据逗号切分为包含2个元素的列表
country_dic[ls[0]] = ls[1] # 第一个元素为值,第二个元素为键,加入到字典中
print(country_dic) # {'中国': '北京', '日本': '东京', '英国': '伦敦'...}
函数代码放到二维码里
def read_to_dic(file):
"""读文件,每行根据空格切分一次,分别作为字典的键和值添加到字典中。返回一个字典对象。"""
country_dic = {}
with open(file, 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象,x依次取值为文件的一行的字符串
k, v = x.strip().split(',') # 将字符串根据逗号切分为包含2个元素的列表
country_dic[k] = v # 第一个元素为值,第二个元素为键,加入到字典中
return country_dic # 返回字典
if __name__ == '__main__':
file_name = '../data/csv/6.5 国家与首都.csv'
print(read_to_dic(file_name)) # 调用函数输出结果
# {'中国': '北京', '日本': '东京', '英国': '伦敦', '法国': '巴黎'...}
能力点8 获取字典值,利用字典实现高效查询
字典是一种无序数据类型,不能使用序号索引的方式获取其值。字典内部的数据具有“键:值”的映射关系,可以通过“键”来访问其“值”,语法为:
dict[key]
通过键“key”返回字典“dict”中与该键对应的值,采用 dict[key] 方法获取键对应的值时,本质是把“键”当作字典的索引值来使用的,不存在该索引值,则会提示错误。为了避免在字典中取数据时出现访问不存在的键值导致的异常,使程序运行意外中止,可以先判断键是否存在,或使用异常处理。
dict[key] # 本质是把“键”当作字典的索引值来使用的,不存在该索引值,则会提示错误
dict.get(k[, default]) 可以避免键不存在时引发的错误
my_dict = {'吉林': '长春', '湖北': '武汉', '湖南': '长沙'}
province = input() # 输入一个省的名称,例如输入:河北
city = my_dict[province] # 查询该省省会
print(city)
不存在该索引值,则会提示错误
city = my_dict[‘河北’]
KeyError: ‘河北’
先做成员测试
my_dict = {'吉林': '长春', '湖北': '武汉', '湖南': '长沙'}
province = input() # 输入一个省的名称,例如输入:湖北
if province in my_dict: # 存在性测试,避免触发异常
print(f'{province}的省会为{my_dict[province]}市') # 以输入为键返回值
else:
print(f'输入错误,查不到{province}省的数据')
dict.get(k[, default]) 可以避免键不存在时引发的错误
def file_to_list(file):
"""接收文件名为参数,读文件,拼接为一个字符串,返回将字符串切分为词的列表"""
txt = '' # 创建空字符串
with open(file, "r", encoding='utf-8') as data: # 创建文件对象
for line in data: # 遍历文件对象
txt = txt + line.strip() # 去掉行末的换行符,拼接成一个字符串
return txt.lower().split() # 返回单词列表
def stop_words():
with open('stopwords.txt') as sw:
return sw.read().split()
def text_analysis(word_list):
"""接受一个包含多个单词的列表为参数,以每个词为键,以该词出现的次数为值构建字典,
按词出现的次数排序,返回降序排序的词频列表"""
word_frequency = {} # 创建一个空字典,word_frequency = dict()
exclude = stop_words() + ['said', 'never', 'one', 'one', 'know']
for word in word_list: # 遍历切分好的词
if len(word) > 1 and word not in exclude: # 跳过一个字(母)的词不统计 and word not in exclude
word_frequency[word] = word_frequency.get(word, 0) + 1 # 以当前词为键,值加1,初值0
items = sorted(word_frequency.items(), key=lambda x: x[1], reverse=True) # 排序
return items[:20] # 返回降序排序的词频列表前20个
if __name__ == '__main__':
# print(stop_words())
filename = '../data/txt/gone with the wind.txt'
word_lst = file_to_list(filename)
print(text_analysis(word_lst))
实例7.8 查询省会
# 构建省名为键,省会为值的字典,用键索引值,避免遍历,提高效率
capitals = {'湖南':'长沙','湖北':'武汉','广东':'广州','广西':'南宁','河北':'石家庄','河南':'郑州','山东':'济南','山西':'太原','江苏':'南京','浙江':'杭州','江西':'南昌','黑龙江':'哈尔滨','新疆':'乌鲁木齐','云南':'昆明','贵州':'贵阳','福建':'福州','吉林':'长春','安徽':'合肥','四川':'成都','西藏':'拉萨','宁夏':'银川','辽宁':'沈阳','青海':'西宁','甘肃':'兰州','陕西':'西安','内蒙古':'呼和浩特','台湾':'台北','北京':'北京','上海':'上海','天津':'天津','重庆':'重庆','香港':'香港','澳门':'澳门'}
while True:
province = input()
if province == '': # 输入回车结束程序
break
else:
print(capitals.get(province,'输入错误'))
# 输出省会,省名不存在时输出'输入错误'
用赋值运算符精简程序:
capitals = {'湖南': '长沙', '湖北': '武汉', '广东': '广州', '广西': '南宁', '河北': '石家庄', '河南': '郑州', '山东': '济南', '山西': '太原', '江苏': '南京', '浙江': '杭州', '江西': '南昌', '黑龙江': '哈尔滨', '新疆': '乌鲁木齐', '云南': '昆明', '贵州': '贵阳', '福建': '福州', '吉林': '长春', '安徽': '合肥', '四川': '成都', '西藏': '拉萨', '宁夏': '银川', '辽宁': '沈阳', '青海': '西宁', '甘肃': '兰州', '陕西': '西安', '内蒙古': '呼和浩特', '台湾': '台北', '北京': '北京', '上海': '上海', '天津': '天津', '重庆': '重庆', '香港': '香港', '澳门': '澳门'}
while province := input(): # 输入回车结束程序
print(capitals.get(province, '输入错误'))
keys()、values()和items()可以获取字典中所有的“键”、“值”和“键:值”对
provinces = my_dict.keys()
citys = my_dict.values()
province_citys = my_dict.items()
print(provinces)
print(citys)
print(province_citys)
dict_keys([‘吉林’, ‘湖北’, ‘湖南’])
dict_values([‘长春’, ‘武汉’, ‘长沙’])
dict_items([(‘吉林’, ‘长春’), (‘湖北’, ‘武汉’), (‘湖南’, ‘长沙’)])
可迭代,可转列表,可排序和逆序
city = {'北京': 1961, '重庆': 2885, '成都': 1405, '上海': 2302}
city_name = list(city.keys()) # ['重庆', '上海', '北京', '成都']
total_population = sum(city.values()) # 可迭代对象可以直接做sum()的参数
print(f'城市列表:{city_name}') # 城市列表:['重庆','上海','北京','成都']
print(f'城市人口{total_population}万人') # 城市人口8553万人
实例 7.9 查询首都
实例7.1将文件中的数据读取到字典中,为其增加功能,用户输入一个国家名,若国家名在字典中存在,输出对应的首都,否则输出“输入错误”。
country_dic = {} # 创建空字典
with open('../data/csv/6.5 国家与首都.csv', 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象,x依次取值为文件的一行的字符串
k, v = x.strip().split(',') # 切分为列表,两个元素分别命名为k,v
country_dic[k] = v # 第一个元素为值,第二个元素为键,加入到字典
# {'中国': '北京', '日本': '东京', '英国': '伦敦', '法国': '巴黎'}
country = input() # 输入要查询的国家名
if country in country_dic: # 判定国家名是否在字典的键中存在
print(country_dic[country]) # 国家名存在时查询并输出对应首都
else: # 二分支保证在任何输入下程序都有响应
print('输入错误') # 国家名不存在时输出提示信息
函数代码放二维码中
def read_to_dic(file):
"""读文件,每行根据空格切分一次,分别作为字典的键和值添加到字典中。返回一个字典对象。"""
country_dic = {}
with open(file, 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象,x依次取值为文件的一行的字符串
k, v = x.strip().split(',') # 切分为列表,两个元素分别命名为k,v
country_dic[k] = v # 第一个元素为值,第二个元素为键,加入到字典
return country_dic # 返回字典
def query(country_name):
"""参数为国家名,查询并返回其首都,国家名不存在时,返回'输入错误' """
if country_name in country_dict:
return country_dict[country_name]
else:
return '输入错误'
if __name__ == '__main__':
file_name = '../data/csv/6.5 国家与首都.csv'
country_dict = read_to_dic(file_name) # 调用函数得到字典
while country := input(): # 赋值表达式运算符,输入国家名非空时
print(f'{country}首都:{query(country)}') # 调用函数查询并输出国家的首都
可以使用字典的内置方法dict.get(k[, default])来获取数据,字典 dict 中存在以“k”为键的元素时,则返回值该键对应的值,否则返回值 default。如果没有提供 default 参数,则返回空值 None。建议在获取字典值时,尽可能使用字典的 get() 方法,可以避免键不存在时引发的错误。
用 get() 方法实现的函数及完整参考程序如下:
country_dic = {} # 创建空字典
with open('../data/csv/6.5 国家与首都.csv', 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象,x依次取值为文件的一行的字符串
k, v = x.strip().split(',') # 将字符串根据逗号切分为包含2个元素的列表
country_dic[k] = v # 第一个元素为值,第二个元素为键,加入到字典中
country = input()
print(country_dic.get(country, '输入错误')) # 国家名不存在时输出'输入错误'
在存在映射关系的数据中,取出指定数据时,采用字典方法比利用列表、元组等序列型数据更加简单和高效。应用列表、元组等数据要遍历全部数据,而字典类型可以直接获取对应的值。
实例 7.10 简明英汉词典
编写python程序,请根据附件文件的内容,编写一段程序,把英语单词译成中文。
dicts.txt
wild 野生的,狂暴的
wilderness 荒原
will aux.将,愿 意志
would 将,愿 意志
willing 乐意的,自愿的
willingly 乐意地,自愿地
willingness 乐意,自愿
willow 柳树
win 赢得,成功
wind 风,风声 绕
winding 弯曲的,蜿蜒的
windmill 风车
dic = {}
with open('../data/txt/dicts.txt', 'r', encoding='utf-8') as data:
for x in data: # 遍历文件对象
k, v = x.strip().split(maxsplit=1) # 切分一次,两个元素分别命名为k,v
dic[k] = v # 以单词为键,以释义为值向字典中增加元素
# print(dic) # 取消注释可查看字典是否构建成功
while word := input(): # 输入要查询的单词,输入非空时循环,直接回车结束循环
print(word, dic.get(word, '单词不存在')) # 单词存在时返回释义,不存在时返回提示信息
# zipcode
# zipcode 邮政编码
# witty
# witty 机智的,风趣的
def read_to_dic(filename):
"""读文件每行根据空格切分一次,作为字典的键和值添加到字典中。
返回一个字典类型。
"""
my_dic = {}
with open(filename, 'r', encoding='utf-8') as data:
for x in data:
k,v = x.strip().split(maxsplit=1)
# my_dic.update({x[0]: x[1]})
my_dic[k] = v
print(my_dic)
return my_dic
实例7.11 绩点计算
描述
平均绩点计算方法:(课程学分1绩点+课程学分2绩点+课程学分n*绩点)/(课程学分1+课程学分2+课程学分n)
用户循环输入五分制成绩和课程学分,输入‘-1’时结束输入,计算学生平均绩点。等级与绩点对应关系如下表:
成绩 等级 绩点
90-100 A 4.0
85-89 A- 3.7
82-84 B+ 3.3
78-81 B 3.0
75-77 B- 2.7
72-74 C+ 2.3
68-71 C 2.0
64-67 C- 1.5
60-63 D 1.3
补考60 D- 1.0
60以下 F 0
输入格式
每组输入包括两行, 第一行是五分制的分数, 第二行是一个代表学分的数字
输出格式
平均绩点,保留两位小数
score = {'A': 4.0, 'A-': 3.7, 'B+': 3.3, 'B': 3.0, 'B-': 2.7, 'C+': 2.3, 'C': 2.0, 'C-': 1.5, 'D': 1.3, 'D-': 1.0,
'F': 0.0}
gpaSum, creditSum, gpaAve = 0, 0, 0
while True:
s = input()
if s == '-1':
break
elif s in score.keys():
credit = float(input())
gpaSum = gpaSum + score[s] * credit
creditSum = creditSum + credit
gpaAve = gpaSum / creditSum
else:
print('data error')
print('{:.2f}'.format(gpaAve))
能力点9 键值获取方法
字典提供了内置方法keys()、values()和items()可以获取字典中所有的“键”、“值”和“键:值”对。返回值是一个可迭代对象,其中的数据顺序与数据加入字典顺序保持一致,获取方法的描述如表7.5所示。
表 7.5 键值获取方法
| 方法 | 描述 |
|---|---|
| dict.keys() | 获取字典dict中的所有键,组成一个可迭代数据对象。 |
| dict.values() | 获取字典dict中的所有值,组成一个可迭代数据对象。 |
| dict.items() | 获取字典dict中的所有键值对,两两组成元组,形成一个可迭代数据对象。 |
可以用这三种方法分别查看通讯录中的全部键、全部值或全部键值对。
country_dic = {'中国': '北京', '韩国': '汉城', '日本': '东京'}
print(country_dic.keys()) # dict_keys(['中国', '韩国', '日本'])
print(country_dic.values()) # dict_values(['北京', '汉城', '东京'])
print(country_dic.items()) # dict_items([('中国', '北京'), ('韩国', '汉城'), ('日本', '东京')])
这3种方法返回值都是可迭代数据对象,可对其进行解包、遍历或用list()将其转为列表,再查看其中的数据。
print(*country_dic.keys()) # 解包输出:中国 韩国 日本
print(list(country_dic.keys())) # 键转列表['中国', '韩国', '日本']
for country, capital in country_dic.items(): # 遍历可迭代对象dict.items()
print(f'{country}首都是{capital}')
# 中国首都是北京
# 韩国首都是汉城
# 日本首都是东京
字典的keys()、values()和items()方法生成的可迭代数据是一种特殊的“视图”类数据,他们的值关联至原始字典,当原始字典中的数据发生改变后,视图中的值会随之发生变化。
country_dic = {'中国': '北京', '韩国': '汉城', '日本': '东京'}
vs = country_dic.values() # 获取字典所有值的视图
print(vs) # dict_values(['北京', '汉城', '东京'])
country_dic['韩国'] = '首尔' # 韩国首都更名为首尔'
print(vs) # dict_values(['北京', '首尔', '东京'])
在 3.7 版以后,字典顺序会确保为插入顺序。所以可以用以下2种方法创建键值对。
country_dic = {'中国': '北京', '韩国': '首尔', '日本': '东京'}
pairs = list(zip(country_dic.keys(), country_dic.values()))
print(pairs) # [('中国', '北京'), ('韩国', '首尔'), ('日本', '东京')]
pairs = [(k, v) for (k, v) in country_dic.items()]
print(pairs) # [('中国', '北京'), ('韩国', '首尔'), ('日本', '东京')]
能力点10 字典的修改
字典是一种可变的数据类型,支持数据元素的增加、删除和修改操作。仍以国家首都的字典为例,在使用的过程中,可能需要向数据里插入新的国家数据、更新原有的国家名或首都名、删除其中的数据等。
1. dict[key] = value
当键名key在字典中存在时,使用dict[key] = value方法,将修改字典dict中键key的值为新值value。当键名key在字典中不存在时,将为字典增加以key为键,以value为值的新元素。
country_dic = {'中国': '北京', '韩国': '汉城'}
country_dic['韩国'] = '首尔' # 韩国首都更名为首尔'
country_dic['日本'] = '东京' # 增加元素 '日本': '东京'
print(country_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京'}
- dict.update(k1=v1[, k2=v2,…]) 方法
可以用dict.update(k1=v1[, k2=v2,…])方法同时更新字典中的多个值。当字典dict中存在k1、k2…时,将对应的值修改为v1、v2…,当不存在相应的键值时,会将对应的k1:v1、k2:v2…键值对加入字典。
country_dic = {'中国': '北京', '韩国': '汉城', '日本': '东京'}
country_dic.update(韩国='首尔') # 韩国首都更名为首尔'
country_dic.update(朝鲜='平壤') # 朝鲜不存在,以键值对加入字典
print(country_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京', '朝鲜': '平壤'}
可以将另一个字典作为update()的参数,一次性把另一个字典中的键值对一次性全部加到当前字典中。下面例子中,新加入的字典中的元素“ ‘韩国’: ‘首尔’” 与原字典中元素“ ‘韩国’: ‘汉城’”键相同,后加入的元素值会替换原来的值。
country_dic = {'中国': '北京', '韩国': '汉城'}
new_dic = {'韩国': '首尔', '日本': '东京'}
country_dic.update(new_dic)
print(country_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京'}
- dict.setdefault(key[, value])方法
使用dict.setdefault(key[, value])方法增加元素,当字典dict 中存在键key时,返回key对应的值;键key不存在时,在字典中增加 key: value 键值对,值value缺省时,默认设其值为None。
country_dic = {'中国': '北京', '韩国': '首尔'}
country_dic.setdefault('日本', '东京')
print(country_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京'}
- “|”和 “|=”
Python 3.9 以后版本支持字典合并运算符“|”和字典更新运算符 “|=”,上述功能可用以下代码实现:
old_dic = {'中国': '北京', '韩国': '汉城'}
new_dic = {'韩国': '首尔', '日本': '东京'}
old_dic |= new_dic # 将new_dic中的元素更新到old_dic中
print(old_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京'}
country_dic = old_dic | new_dic # 将old_dic和new_dic的元素合并到字典country_dic中
print(country_dic) # {'中国': '北京', '韩国': '首尔', '日本': '东京'}
能力点11 字典元素的删除
删除字典内的值可以使用内置pop()、popitem()和clear()方法。
- dict.pop() 方法
dict.pop(key[, default]) 方法将键为 key 的键值对元素删除,返回值为键 key 对应的值;如果提供了default 值,dict 中不存在 key 键时返回 default,否则将会触发“KeyValue”异常。
country_dic = {'中国': '北京', '韩国': '首尔', '南斯拉夫': '贝尔格莱德'}
country_dic.pop('南斯拉夫')
print(country_dic) # {'中国': '北京', '韩国': '首尔'}
- dict.popitem()方法
dict.popitem()方法删除位于字典末尾的一个元素,并以元组形式返回。
country_dic = {'中国': '北京', '韩国': '首尔', '南斯拉夫': '贝尔格莱德'}
del_country = country_dic.popitem()
print(country_dic) # {'中国': '北京', '韩国': '首尔'}
print('删除的元素是:', del_country) # 删除的元素是: ('南斯拉夫', '贝尔格莱德')
dict.clear()方法会清空字典dict中所有数据,dict成为空字典。
country_dic = {'中国': '北京', '韩国': '首尔', '南斯拉夫': '贝尔格莱德'}
country_dic.clear() # 清空字典中的所有数据
print(country_dic) # {}
能力点12 字典排序
3.7以前的版本中,字典本身是无序的,需要排序时,可以将字典的元素、键或值转为列表再排序输出。3.7以后的版本字典顺序确保为插入顺序。字典视图dict.keys()、dict.values()和dict.items()都是可逆的,同时可以作为排序函数sorted()的参数,排序返回结果为列表:
sorted(iterable, *, key=None, reverse=False)
info = {'Tom': 21, 'Bob': 18, 'Jack': 23, 'Ana': 20}
sort_info = sorted(info)
sort_key = sorted(info.keys())
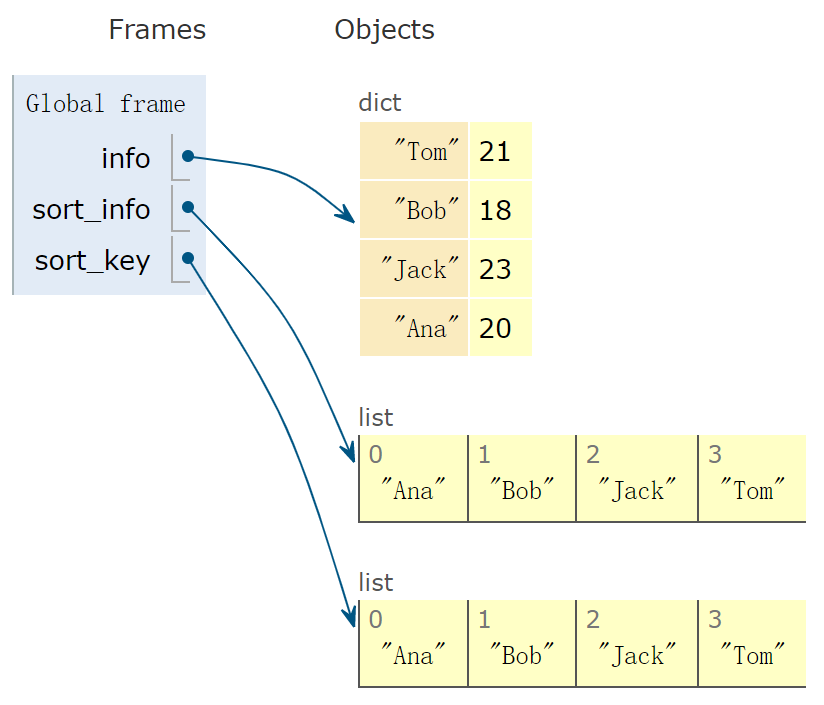
info = {'Tom': 21, 'Bob': 18, 'Jack': 23, 'Ana': 20}
sort_value = sorted(info.items())
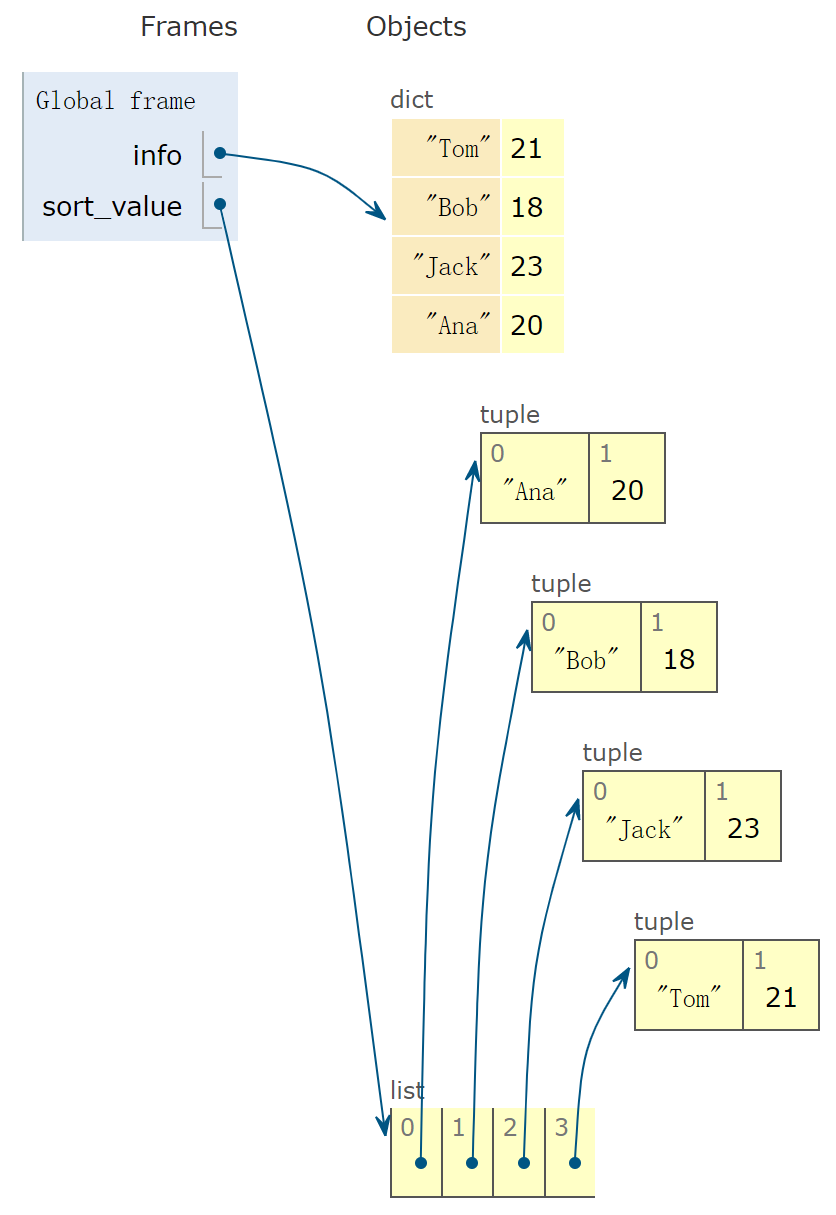
对字典的值(value)排序可以用key 参数结合lambda 表达式的方法完成
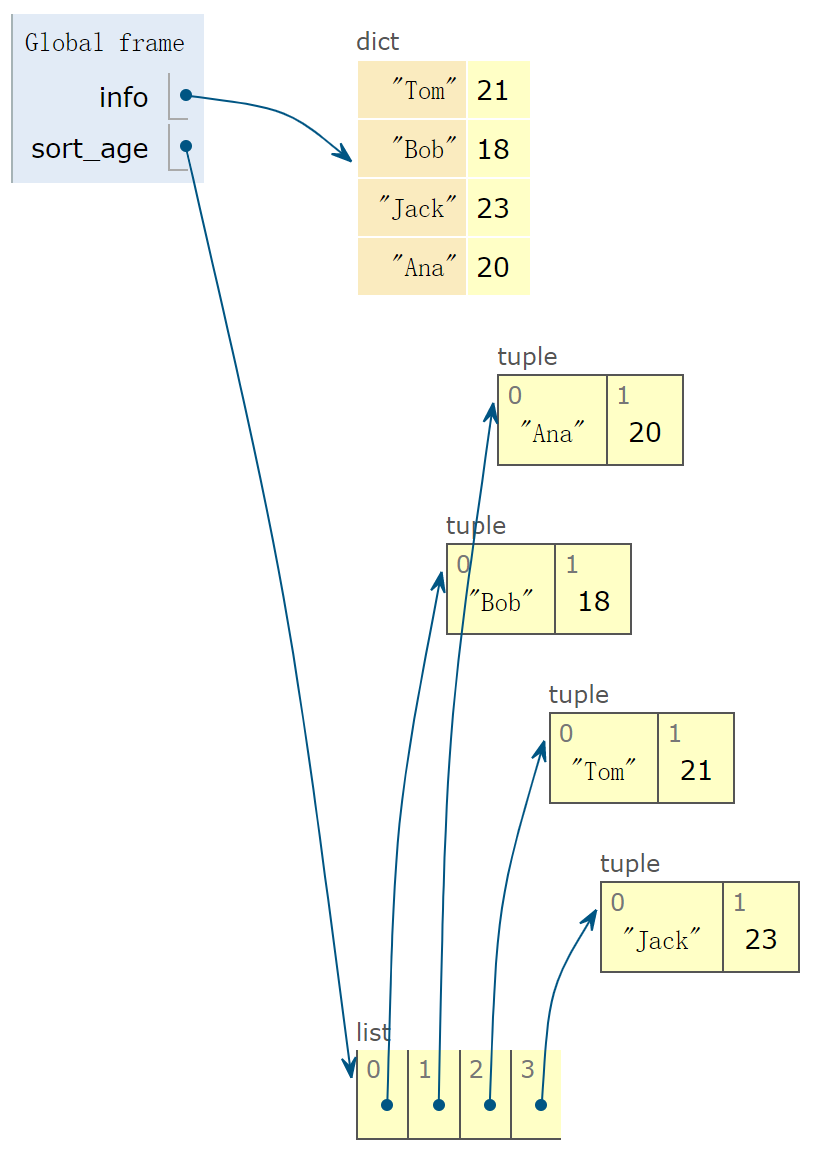
info = {'Tom': 21, 'Bob': 18, 'Jack': 23, 'Ana': 20}
sort_age = sorted(info.items(), key=lambda item: item[1])
字典本身是无序的,字典没有自己的排序方法和函数。但字典是可迭代对象,所以可以用内置函数sorted()对其进行排序,返回值为列表。参数为字典名或字典的键的视图时,结果相同,都返回键的排序列表。
info_dic = {'China': 14.47, 'India': 14.03, 'USA': 3.34, 'Japan': 1.25}
print(sorted(info_dic)) # ['China', 'India', 'Japan', 'USA']
print(sorted(info_dic.keys())) # ['China', 'India', 'Japan', 'USA']
使用sorted(dict.items()) 就能获得字典所有键值对并按键升序排序;如果想按照逆序排序的话,则只要设 reverse = True 即可。对字典的值(value)排序可以用 key 参数结合lambda 表达式的方法完成,x 表示传入参数,此处传入的键值对的元组,x[1] 表示元组序号为 1 的项,即人口数量。
info_dic = {'China': 14.47, 'India': 14.03, 'USA': 3.34, 'Japan': 1.25}
print(sorted(info_dic.items())) # 根据键升序排序
# [('China', 14.47), ('India', 14.03), ('Japan', 1.25), ('USA', 3.34)]
print(sorted(info_dic.items(), key=lambda x: x[1])) # 根据值升序排序
# [('Japan', 1.25), ('USA', 3.34), ('India', 14.03), ('China', 14.47)]
实例7.12 词频统计
统计“西游记.txt”中出现次数最多的10个词和每个词出现的次数。
词和词出现的次数正好可以用字典中的键值对表示,遍历“西游记.txt”,将文件的每行末的换行符去掉并拼接为一个字符串,再将字符串 txt切分为词的列表。创建一个空字典,遍历词的列表,以每个词为键,以该词出现的次数为值,反复更新词典中的键和值。最后依据词典元素的值进行降序排序,输出前10个元素。
中文的文章与英文不同,英文每个单词间自然以空格进行分隔,可以用split()将英文字符串切分为单词的列表。而中文中以句子为分隔的,各词之间无分隔,将中文字符串切分成多个单词可以利用第三方库jieba 库中 lcut(txt) 函数来完成,参数 txt 为一个中文字符串。在使用第三方库之前,要先安装这个库,方法是:
pip install jieba
先定义一个文件读取函数,打开文件创建文件对象,用遍历方法将文件的内容读出来拼接为一个字符串,返回这个字符串。
定义一个词频分析函数,调用 函数获得读取文件得到的字符串,利用jieba 库中 lcut(txt) 函数分词得到中文词的列表。遍历这个列表,略过没有意义的词和以单字词,以词为键构建字典,将词出现的数量作为键的值反复修改字典,该词出现一次,其值就增加 1,最终得到全部词的词频字典。利用 sorted() 函数根据字典的值进行降序排序,返回排序的结果。
import jieba # jieba是中文分词库,将中文句子切分成词。
def file_string(file):
"""接收文件名为参数,读文件,返回一个字符串"""
txt = '' # 创建空字符串
with open(file, "r", encoding='utf-8') as data: # 创建文件对象
for line in data: # 遍历文件对象
txt = txt + line.strip() # 去掉行末的换行符,拼接成一个字符串
return txt # 返回字符串
def text_analysis(txt):
"""接收一个字符串为参数,字符串切分为词,统计每个词出现的次数,返回以词为键,以数量为值的字典"""
words_ls = jieba.lcut(txt) # 将字符串切分成词的列表
frequency = {} # 创建一个空字典
exclude = ['一个', '那里', '怎么', '我们', '不知', '两个', '什么', '不是']
for word in words_ls: # 遍历切分好的词
if word not in exclude and len(word) > 1: # 跳过一个字的词和exclude中的词
frequency[word] = frequency.get(word, 0) + 1 # 以当前词为键,值加1,初值0
items = sorted(frequency.items(), key=lambda x: x[1], reverse=True)
# 按词频降序排序,返回以键和值组成的元组为元素的列表,元素类似('行者', 4073)
return items # 返回降序排序的词频列表
if __name__ == '__main__':
filename = "../data/txt/西游记.txt" # 文件名
text = file_string(filename) # 调用读文件函数,返回字符串类型
ls = text_analysis(text) # 调用统计分析函数统计词频,得到列表
for i in range(10): # 输出前10 个元素
hot_word, amount = ls[i] # 将元组元素分别赋值给hot_word和amount
print("{0:<4}{1:>4}".format(hot_word, amount))
# 词语左对齐宽度4;数量右对齐宽度4
输出:
行者 4073
八戒 1677
师父 1562
三藏 1265
唐僧 801
大圣 751
沙僧 721
妖精 627
和尚 617
菩萨 598
统计“7.8 宋词三百首.txt”中出现次数最多的10个词和每个词出现的次数。
词和词出现的次数正好可以用字典中的键值对表示,遍历“7.8 宋词三百首.txt”,以每个词为键,以该词出现的次数为值,构成一个词典。对词典进行降序排序,输出前10个元素。
中文的文章与英文不同,英文每个单词间自然以空格进行分隔,而中文中以句子为分隔的,各词之间无分隔,所以要先将一个句子切分成多个单词。
分词这项工作可以利用一个第三方库jieba 库中lcut(txt) 函数来完成,参数txt 为一个中文字符串。在使用第三方库之前,要先安装这个库,方法是:
pip install jieba
先定义一个读文件的函数,将文件内容读取为一个字符串。返回这个字符串,内容读出来拼接为一个字符串
定义一个词频分析函数,调用file_string(file) 函数获得读取文件得到的字符串,利用jieba 库中lcut(txt) 函数分词得到中文词的列表。遍历这个列表,以非单字词(长度大于1)为键构建字典,将词的计数作为键的值反复修改字典,该词出现一次,其值就增加1,最终得到全部词的词频字典。利用sorted() 函数根据字典的值进行降序排序,返回排序的结果。
import jieba # jieba是中文分词库,将中文句子切分成词。
def file_string(file):
"""接受文件名为参数,读取文件中的数据成一个字符串,返回这个字符串"""
txt = '' # 创建空字符串
with open(file, "r", encoding='utf-8') as data: # 创建文件对象
for line in data: # 遍历文件对象
txt = txt + line.strip() # 拼接成字符串
return txt # 返回字符串
def cut_txt(txt):
"""利用jieba对字符串txt进行切分,返回元素为中文词的列表。"""
word_list = jieba.lcut(txt) # 用lcut()将字符串切分成词的列表
return word_list
def text_analysis(word_list, txt):
"""接受一个字符串为参数,利用jieba对字符串进行分词,统计分析这个字符串中每个词出现的次数,
以每个词为键,以该词出现的次数为值构建字典,按词出现的次数排序,返回降序排序的词频列表"""
counts = {} # 创建一个空字典,counts = dict()
for word in word_list: # 遍历切分好的词
if len(word) > 1: # 跳过一个字的词不统计
counts[word] = counts.get(word, 0) + 1 # 以当前词为键,值加1,初值0
items = sorted(counts.items(), key=lambda x: x[1], reverse=True) # 排序
return items # 返回降序排序的词频列表
def print_words(items, n):
for i in range(n): # 输出前10 个元素
word, count = items[i] # 将元组中值赋给word和count
print("{0:<4}{1:>4}".format(word, count))
# 词语左对齐宽度4;数量右对齐宽度4
if __name__ == '__main__':
filename = "7.8 宋词三百首.txt" # 文件名
text = file_string(filename) # 调用读文件函数,返回字符串类型
words_lst = cut_txt(text)
ls = text_analysis(words_lst, text) # 调用统计分析函数统计词频
print_words(ls, 10)
输出:
东风 38
几道 30
斜阳 26
黄昏 26
吴文英 25
何处 24
天涯 24
相思 23
风雨 22
明月 22
从输出的结果中,可以发现宋代词作家喜欢“东风”、“斜阳”、“黄昏”等词语。
dict()
{}
{'name': '张明', 'age': 18, 'gender': 'M'}
my_dict4 = dict(name='张三', age=19, gender='M')
my_dict5 = dict([('name', '张三'), ('age', 19), ('gender', 'M')])
my_dict6 = dict(zip(('name','age','gender'), ('张三',19,'M')))
# 推导式
name_list = [('李明', '13988887777'), ('张宏', '13866668888')]
name_dict = {k: v for k, v in name_list} # 用推导式从列表生成字典
print(name_dict) # {'李明': '13988887777', '张宏': '13866668888'}
name = ['李明', '张宏']
phone = ['13988887777', '13866668888']
name_dict = {k: v for k, v in zip(name, phone)} # 先组合两个列表
print(name_dict) # {'李明': '13988887777', '张宏': '13866668888'}
内置函数与方法
| 函数 | 描述 |
|---|---|
| list(dict) | 返回字典 dict 中使用的所有键的列表 |
| len(dict) | 返回字典的项数 |
| str(dict) | 输出字典可打印的字符串表示。 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| iter(dict) | 返回以字典的键为元素的迭代器。 这是 iter(dict.keys()) 的快捷方式 |
| copy() | 返回原字典的浅拷贝 |
| reversed(dict) | 返回一个逆序获取字典键的迭代器。 这是reversed(dict.keys()) 的快捷方式,3.8 新版功能。 |
| dict | other | 合并 dict 和 other 中的键和值来创建一个新的字典,两者必须都是字典。当 和 other 有相同键时, other 的值优先,3.9 新版功能。 |
| dict |= other | 用 other 的键和值更新字典 ,other 可以是 mapping 或 iterable 的键值对。当 和 other 有相同键时, other 的值优先,3.9 新版功能。 |
应用实例
实例7.13 客服短号查询
# -------- ------- --------
# @File : 客服短号查询.py
# @Author : 赵广辉
# @Contact: vasp@qq.com
# @Company: 武汉理工大学
# @Version: 1.0
# @Modify : 2022/05/19 7:52
# Python程序设计基础,高等教育出版社
# -------- ------- --------
def read_txt(file):
"""
@参数 file:文件名,字符串
读取文件file中国数据,构建包含各公司客服电话的字典,公司名为键,电话号码为值。返回字典。
"""
tel_book = {}
with open(file, 'r', encoding='utf-8') as f:
for line in f:
x = line.strip().split(',')
tel_book[x[0]] = x[1]
print(tel_book)
return tel_book
def query_get(company, tel_book):
"""
@参数 company:公司名,字符串
@参数 tel_book:通讯录,字典
接收公司名为参数,查询该公司的客服电话号码,返回用户名:电话号码。
"""
return company + ":" + tel_book.get(company, f'公司名{company}不存在')
def query_index(company, tel_book):
"""
@参数 company:公司名,字符串
@参数 tel_book:通讯录,字典
接收公司名为参数,查询该公司的客服电话号码,返回用户名:电话号码。
"""
if company in tel_book: # 存在性测试,避免触发异常
return company + ':' + tel_book[company] # company不存在时触发异常
else:
return company + ":" + f'公司名{company}不存在'
def modify_number(company, tel_book):
"""
@参数 company:公司名,字符串
@参数 tel_book:通讯录,字典
接收用户姓名为参数,若姓名在字典的键中存在,输入'Y'后再输入一个新电话号码,将用户的电话号码修改为新值,
返回'成功修改{company}电话为{phone_number}';输入其他字符时返回'放弃修改'并退出。
若姓名在字典的键中不存在,输入'N'后再输入一个新电话号码,向字典中加入新的'姓名:电话号码',
返回'成功插入新记录,{company}:{phone_number}';输入其他字符时返回'放弃修改'并退出。
"""
if company in tel_book:
print('姓名已存在,输入"Y"修改,其他字符退出')
if input() == 'Y': # 接受一个输入,若为字符“Y”
phone_number = input('请输入公司客服电话号码:') # 再输入一个电话号码
tel_book[company] = phone_number # 修改键对应的值
return f'成功修改{company}电话为{phone_number}'
else:
print('姓名不存在,输入"Y"新增一条记录,其他字符退出')
if input() == 'Y': # 接受一个输入,若为字符“Y”
add_number(company, tel_book)
def add_number(company, tel_book):
"""
@参数 company:公司名,字符串
@参数 tel_book:通讯录,字典
增加一条记录
"""
if company not in tel_book:
print('姓名不存在,输入"Y"新增一条记录,其他字符退出')
if input() == 'Y': # 接受一个输入,若为字符“Y”
phone_number = input('请输入公司客服电话号码:') # 再输入一个电话号码
tel_book[company] = phone_number # 新增一个元素
return f'成功插入新记录,{company}:{phone_number}'
else:
print('姓名已存在,输入"Y"修改,其他字符退出')
if input() == 'Y': # 接受一个输入,若为字符“Y”
modify_number(company, tel_book)
def del_number(company, tel_book):
"""
@参数 company:公司名,字符串
@参数 tel_book:通讯录,字典
删除一条记录
"""
if company in tel_book:
del_key = tel_book.pop(company)
return f'{del_key}信息成功删除'
else:
return f'公司名不存在'
def clear_all(tel_book):
"""清空通讯录,清除前先与用户确认。"""
print('此操作会清空通讯录中全部信息,请谨慎操作!输入"Y"清空通讯录。')
if input() == 'Y':
tel_book.clear()
print('通讯录全部信息删除成功!')
def judge(task, tel_book):
"""判断操作类别"""
if task == '查询':
company = input('请输入公司名称:')
print(query_get(company, tel_book))
# print(query_index(company, tel_book))
elif task == '插入':
company = input('请输入公司名称:')
print(add_number(company, tel_book))
elif task == '更新':
company = input('请输入公司名称:')
print(modify_number(company, tel_book))
elif task == '删除':
company = input('请输入公司名称:')
print(del_number(company, tel_book))
elif task == '清空':
clear_all(tel_book)
else:
print('输入错误')
if __name__ == '__main__':
filename = 'customer service number.txt'
phone_book = read_txt(filename)
choice = input()
judge(choice, phone_book)
实例7.14 背单词
# -------- ------- --------
# @File : 背单词.py
# @Author : 赵广辉
# @Contact: vasp@qq.com
# @Company: 武汉理工大学
# @Version: 1.0
# @Modify : 2022/5/06 23:39
# Python程序设计基础,高等教育出版社
# 代码量1.5-2小时
# -------- ------- --------
import random
import string
def read_to_dic(filename):
"""读文件每行根据空格切分一次,作为字典的键和值添加到字典中,返回一个字典类型数据。"""
word_dic = {}
with open(filename, 'r', encoding='utf-8') as data:
for x in data:
k, v = x.strip().split(maxsplit=1)
word_dic[k] = v.split(',')
return word_dic
def translate_word():
"""调用此函数时,先输出提示信息:'请输入查询的单词:'
用户可循环输入欲翻译的单词,若直接输入回车时,输出'查询结束,正在退出...'。
输入非空时输出翻译结果
"""
while True:
word = input('请输入查询的单词:') # 输入查询的单词
if word == '':
print('查询结束,正在退出...')
break
else:
print(*translate(word))
def translate(word):
"""接收两个参数,第一个是读文件创建的字典,第二个参数为要查询的单词,字符串
根据文件创建的字典,从中查询单词word,
如果查询单词存在,元组形式返回词与词的释义;
如果查询不存在,返回'单词不存在'
"""
word = word.lower() # 单词转小写
return word, words_dic.get(word, '单词不存在') # 查询字典,返回单词的意义,单词不存在时,返回'这个词我不明白'
def sentence_to_words():
"""调用此函数时,先输出提示信息'请输入查询的句子:'
用户输入欲翻译的句子
若输入非空时,先将"n't"替换为 ' not'、"'s"替换为 ' is',再将标点符号替换为空格。
根据空格将句子切分为单词的列表,调用translate逐个单词进行翻译。
用户可重复多次输入,每输入一名翻译一句,
若直接输入回车时,输出'查询结束,正在退出...'。然后结束程序。
"""
while True:
sentence = input('请输入查询的句子:') # 输入查询的句子
if sentence == '':
print('查询结束,正在退出...')
break
sentence = sentence.replace("n't", ' not').replace("'s", ' is') # "n't"替换为 ' not',"'s"替换为 ' is'
for x in string.punctuation: # 其他标点符号替换为空格
sentence = sentence.replace(x, ' ')
word_list = sentence.split() # 根据空格切分句子为单词的列表
for word in word_list:
print(*translate(word)) # 调用函数翻译并输出释义
def training():
"""输入一个字母,返回以这个字母开头的词汇的字典,用于单词记忆训练"""
letter = input('输入今天训练单词首字母:').lower()
train_dict = {k: v for k, v in words_dic.items() if k[0].lower() == letter}
return train_dict
def en_to_ch(train_dict):
"""从训练字典中随机抽取以某个字母开头的单词,用户填写词义
回答正确时,输出当前词全部释义,输入错误时,记录该单词信息,
直接输入回车时结束输入,并输出全部出错单词的信息"""
wrong_answer = {}
while True:
word = random.choice(list(train_dict.keys()))
print(f'请输入单词{word}的中文翻译:')
answer = input() # 输入要查询的单词,输入非空时循环,直接回车结束循环
if not answer:
for k, v in wrong_answer.items():
print(f'{k}的释义为:', *v)
break
elif answer in train_dict[word]:
print(f'{word}的释义为:', *train_dict[word])
else:
print('答案错误')
wrong_answer[word] = train_dict[word]
def ch_to_en(train_dict):
"""从训练字典中随机抽取以某个字母开头的单词的释义,用户填写英文单词
回答正确时,输出当前词全部释义,输入错误时,记录该单词信息,
直接输入回车时结束输入,并输出全部出错单词的信息"""
wrong_answer = {}
while True:
word, chinese = random.choice(list(train_dict.items()))
print(f'请输入{chinese}对应的单词:')
answer = input() # 输入单词
if not answer: # 直接输入回车时结束训练
print('今天答错的词汇如下:')
for k, v in wrong_answer.items(): # 遍历错题本,输出错误单词信息
print(f'{v}的释义为:', k)
break # 结束循环
elif answer == word: # 若输入单词与原单词相同
print(f'{answer}的单词为:', *train_dict[answer])
else:
print('答案错误')
wrong_answer[word] = train_dict[word]
def judge(option):
"""根据输入调用不同函数"""
if option == '汉英训练':
today_dict = training() # 构建训练字典
ch_to_en(today_dict)
elif option == '英汉训练':
today_dict = training() # 构建训练字典
en_to_ch(today_dict)
elif option == '翻译单词':
translate_word() # 翻译单词
elif option == '翻译单词':
sentence_to_words() # 翻译单词
else:
print('输入错误,请重新运行程序!')
if __name__ == '__main__':
file = '../data/txt/dicts.txt'
words_dic = read_to_dic(file) # 读文件构建字典
choice = input() # 输入操作选项
judge(choice) # 根据输入调用功能函数
{'a': '一个', 'abandon': '抛弃,放弃', 'abandonment': '放弃', 'abbreviation': '缩写',...
...
'zipcode': '邮政编码', 'zipper': '拉链', 'zone': '地带,区域,区', 'zoo': '动物园', 'zoology': '动物学'}

若有收获,就点个赞吧
0 人点赞
