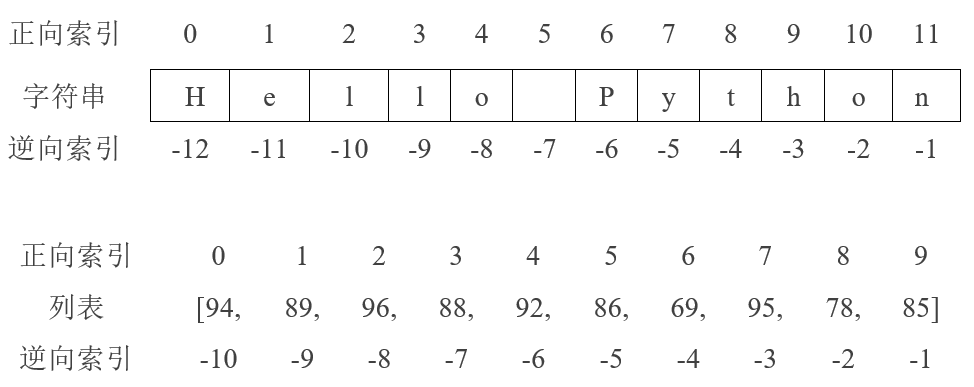
能力点1:获取序列元素及子序列
结果:新对象
索引seq[i]:获得序列元素,类型为元素本身的类型,如元素为整数的列表索引结果为整数
切片seq[m:n:s]:获得子序列,类型仍与序列相同,如列表切片结果为列表,字符串切片结果为字符串
score = [56, 89, 78, 65, 99]print(score[1]) # 89print(score[1:3]) # [89, 78]print([60] * 4) # [60, 60, 60, 60]score = ['56', '89', '78', '65', '99']print(','.join(score)) # 56,89,78,65,99score = [[56, 89], [78, 65], [99]]print(sum(score, [])) # [56, 89, 78, 65, 99]score = ((56, 89), (78, 65), (99,))print(sum(score, ())) # (56, 89, 78, 65, 99)
序列及序列通用操作
文本序列(字符串)、列表、元组、range、同属序列类型,元素有正反序号:
索引:一个序号,结果类型为元素的数据类型
切片:2-3个序号,默认从0开始到结束,结果类型仍为原序列类型
拼接:+ ,字符串和列表可以拼接
重复:* 字符串和列表可以重复整数次
计数、查找、成员测试 in
示例5.1 身份证(索引、切片)
- 传入一个18位身份证号字符串
- 切片6-10获得年份(6,7,8,9位)
- 切片10-12获得月份(10,11位)
- 切片12-14获得日期(12,13位)
- 索引第17位获得性别码(序号16位)
- 如果第17位是奇数
- 性别为男
- 否则
- 性别为女
- 如果第17位是奇数
- 输出指定格式的字符串
```python
def id_check(id_num):
“””接收一个表示身份证号的字符串为参数,
返回其出生年月日和性别。 “””
year = id_num[6:10]
month = id_num[10:12]
date = id_num[12:14]
if id_num[16] in ‘13579’:
else:gender = '男'
return f’出生于{year}年{month}月{date}日,性别{gender}’gender = '女'
if name == ‘main‘: idnum = input() print(id_check(idnum))
```pythondef id_check(id_num):"""接收一个表示身份证号的字符串为参数,返回其出生年月日和性别。>>> id_check('441421196905233209')'出生于1969年05月23日,性别女'>>> id_check('520302195608314870')'出生于1956年08月31日,性别男'"""gender = '男' if id_num[16] in '13579' else '女' # 条件运算表达式return f'出生于{id_num[6:10]}年{id_num[10:12]}月{id_num[12:14]}日,性别{gender}'if __name__ == '__main__':idnum = input()print(id_check(idnum))
示例5.2 回文函数(切片)
def palindromic(num):if str(num) == str(num)[-1::-1]:return Trueelse:return False
def palindromic(num):"""接收一个数字为参数,判定其是否为回文数,返回布尔值。>>> palindromic(123)False>>> palindromic(12321)True"""if str(num) == str(num)[::-1]:return Trueelse:return False
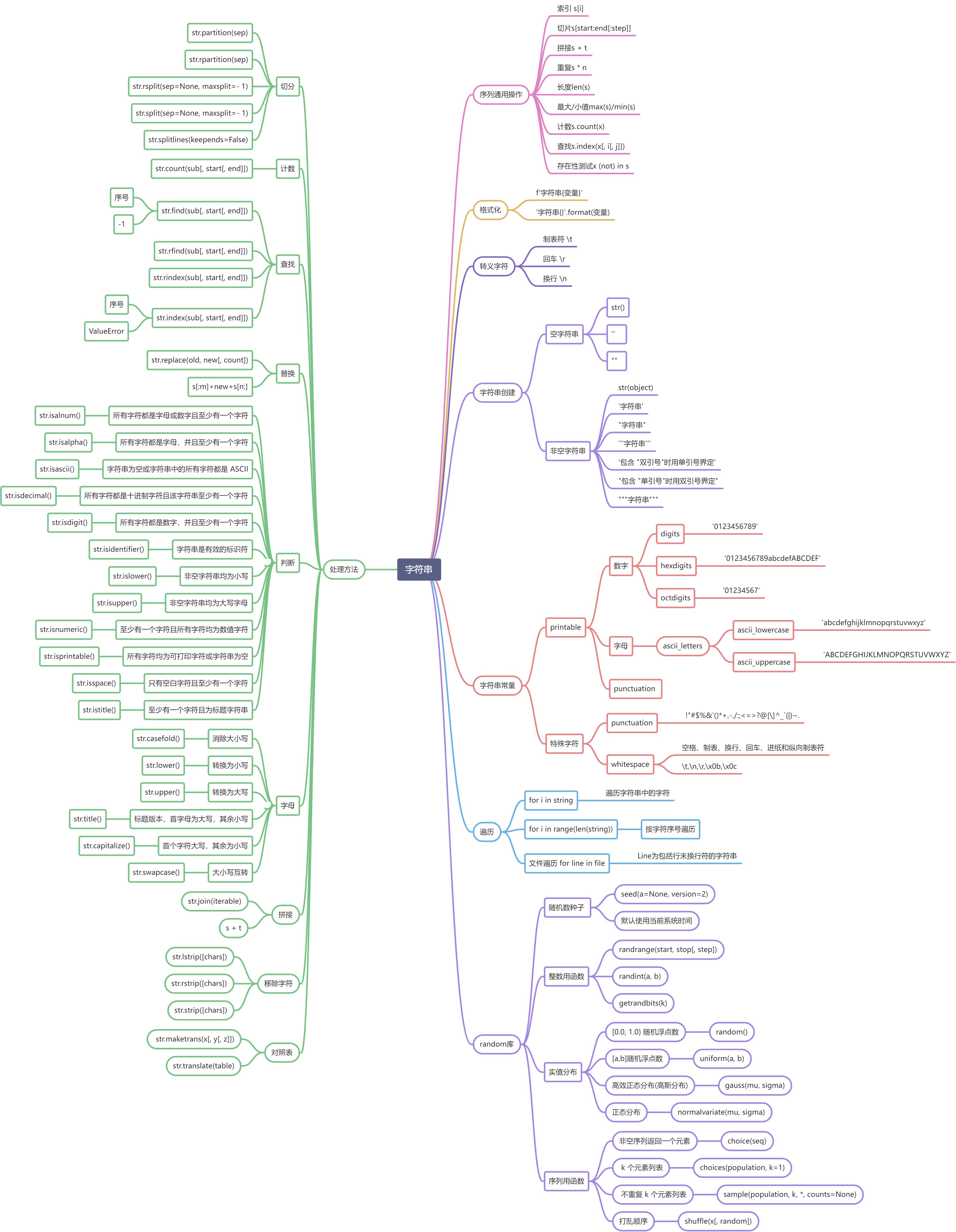
示例5.3 约瑟夫环
有11个人围坐在一张圆桌周围,从第1个人开始报数,数到3的那个人出列,他的下一个人又从1开始报数,数到3的那个人又出列;依此规律重复下去,直到圆桌周围的人数少于3时结束,输出剩下的人的序号。
- 构建一个长度为11的列表(看成环状)
- 若环中剩余元素多于或等于3时
- 删除第3个元素,并把前2个元素拼接到元素3以后的列表末尾
- 输出剩余元素
ring[3:]+ring[0:2][1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]3 [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2]
ring[3:]+ring[0:2][1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]3 [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2]6 [7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2, 4, 5]9 [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2, 4, 5, 7, 8]
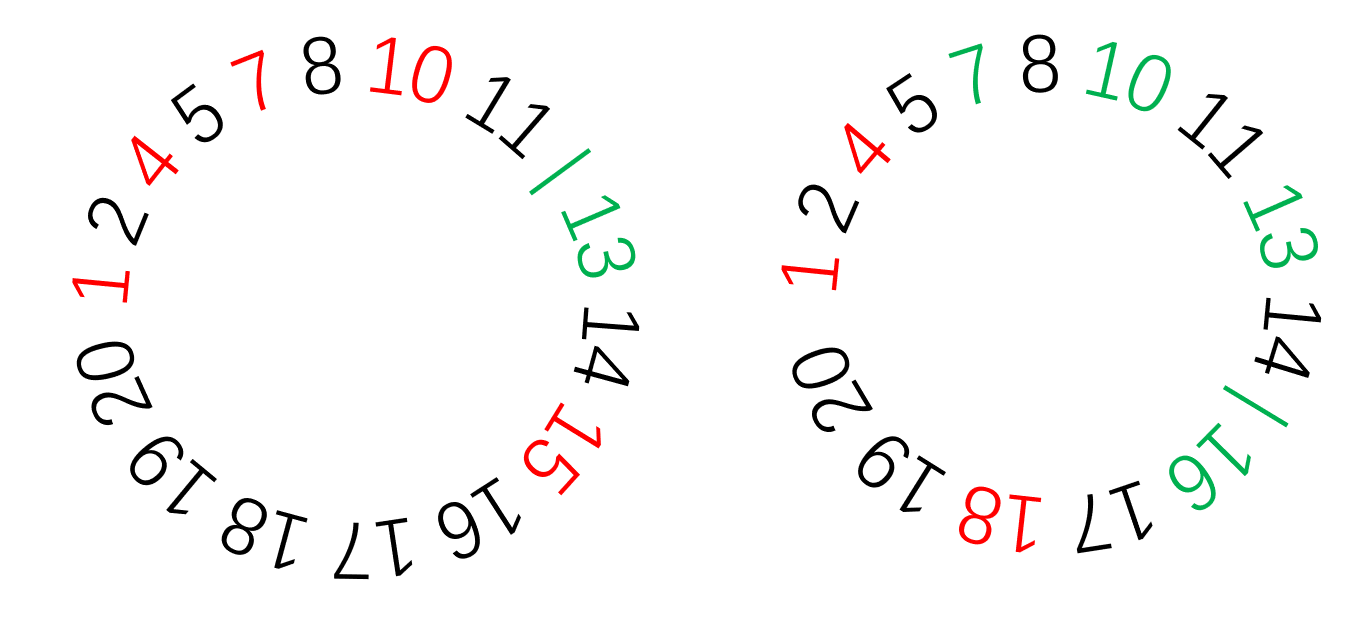
ring[3:]+ring[0:2][1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]3 [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2]6 [7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2, 4, 5]9 [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 1, 2, 4, 5, 7, 8]12 [13, 14, 15, 16, 17, 18, 19, 20, 1, 2, 4, 5, 7, 8, 10, 11]15 [16, 17, 18, 19, 20, 1, 2, 4, 5, 7, 8, 10, 11, 13, 14]
ls = list(range(1, 11 + 1)) # 构造一个元素 1 到 n 的列表
while len(ls) >= 3: # 列表长度大于或等于m时,去掉第m个元素
ls = ls[3:] + ls[:3 - 1] # 前m-1个元素拼接到m以后的列表末尾
print(ls) # 循环结束后,输出列表中剩下的元素
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] # ls = list(range(1,12))
3 [4, 5, 6, 7, 8, 9, 10, 11, 1, 2] # ls = ls[3:] + ls[:3-1]
6 [7, 8, 9, 10, 11, 1, 2, 4, 5] # ls = ls[3:] + ls[:3-1]
9 [10, 11, 1, 2, 4, 5, 7, 8]
1 [2, 4, 5, 7, 8, 10, 11]
5 [7, 8, 10, 11, 2, 4]
10 [11, 2, 4, 7, 8]
4 [7, 8, 11, 2]
11 [2, 7, 8]
8 [2, 7]
[2, 7] # 剩余元素[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
- 输入环长度num与步长step
- 构建一个长度为num的列表(看成环状)
- 若环中剩余元素多于或等于step时
- 删除第step个元素,并把前step-1个元素拼接到step以后的列表末尾
- 输出剩余元素
```python
def josephus_ring(num, step):
长度为num的列表,循环删除元素step,把前step-1个元素拼接到列表末尾
ls = list(range(1, num + 1)) # 构造一个元素 1 到 num 的列表 while len(ls) >= step: # 列表长度大于或等于step时,去掉第step个元素
return ls # 循环结束后,输出列表中剩下的元素ls = ls[step:] + ls[:step - 1] # 前step-1个元素拼接到step以后的列表末尾
if name == ‘main‘: n, m = 11, 3 ls = josephus_ring(n, m) print(*ls)
```python
def josephus_ring(num, step):
# 长度为num的列表,循环删除元素step,把前step-1个元素拼接到列表末尾
ls = list(range(1, num + 1)) # 构造一个元素 1 到 num 的列表
while len(ls) >= step: # 列表长度大于或等于step时,去掉第step个元素
ls = ls[step:] + ls[:step - 1] # 前step-1个元素拼接到step以后的列表末尾
return ls # 循环结束后,输出列表中剩下的元素
if __name__ == '__main__':
n, m = map(int, input().split()) # 输入切分为列表并映射为整数
ls = josephus_ring(n, m)
print(*ls)
示例5.4 判断火车票座位
描述
我国高铁一等座车座席采用2+2方式布置,每排设有“2+2”方式排列四个座位,以“A、C、D、F”代表,字母“A”和“F”的座位靠窗,字母“C”和“D”靠中间走道。 二等座车座席采用2+3布置,每排设有“3+2”方式排列五个座位,以“A、B、C、D、F”代表,字母“A”和“F”的座位靠窗,字母“C”和“D”靠中间走道,“B”代表三人座中间座席。每个车厢座位排数是1-17,字母不区分大小写。
用户输入一个数字和一个字母组成的座位号,根据字母判断位置是窗口、过道还是中间座席,输入不合法座位号时输出’输入错误’。
输入格式
输入一个数字和字母组合成的字符串
输出格式
‘窗口’、’过道’、’中间’ 或’输入错误’
- 输入座位,字母转大写
- 调用判定座位是否合法的函数
- 合法时
- 调用判定座位位置的函数
- 非法时
- 输出“输入错误”
- 合法时
判定座位是否合法的函数
- 判定数字是否为整数:
- 判定数字是否在1-17之间:
- 判定字母是否在ABCDF中:
- 满足三个条件的:
- 返回True
- 否则:
- 返回False
- 满足三个条件的:
- 判定字母是否在ABCDF中:
- 判定数字是否在1-17之间:
数字不是整数时:
- 返回False
判定座位位置的函数def seat_numbers(seat): """接收座位号为参数,判定座位是否合法,返回布尔值""" try: if 1 <= int(seat[:-1]) <= 17 and seat[-1] in 'ABCDF': return True else: return False except ValueError: return False
- 返回False
如果字母在AF中:
- 窗口
- 如果字母在CD中
- 过道
- 如果字母为B(否则)
- 中间
完整代码 ```python def seat_numbers(seat): “””接收座位号为参数,判定座位是否合法,返回布尔值””” try: if 1 <= int(seat[:-1]) <= 17 and seat[-1] in ‘ABCDF’:def window_or_aisle(seat): """接收座位号为参数,判定是窗口、过道还是中间,返回字符串""" if seat[-1] in 'AF': return '窗口' elif seat[-1] in 'CD': return '过道' elif seat[-1] == 'B': return '中间'
else:return True
except ValueError: return Falsereturn False
- 中间
def window_or_aisle(seat): “””接收座位号为参数,判定是窗口、过道还是中间,返回字符串””” if seat[-1] in ‘AF’: return ‘窗口’ elif seat[-1] in ‘CD’: return ‘过道’ elif seat[-1] == ‘B’: return ‘中间’
if name == ‘main‘: Seat = input().upper() if seat_numbers(Seat): print(window_or_aisle(Seat)) else: print(‘输入错误’)
18a 111a -5f 16H F17
<a name="VcGtm"></a>
## 表 5.2 字符串常量表
| 字符串常量 | 字符集 |
| --- | --- |
| string.ascii_letters | 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' |
| string.ascii_lowercase | 'abcdefghijklmnopqrstuvwxyz' |
| string.ascii_uppercase | 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' |
| string.digits | '0123456789' |
| string.hexdigits | '0123456789abcdefABCDEF' |
| string.octdigits | '01234567'. |
| string.punctuation | '!"#$%&\\'()*+,-./:;<=>?@[\\\\]^_`{|}~' |
| string.printable | '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\\'()*+,-./:;<=>?@[\\\\]^_`{|}~\\t\\n\\r\\x0b\\x0c' |
| string.whitespace | ' \\t\\n\\r\\x0b\\x0c' |
<a name="w49Ov"></a>
## 示例5.4 分类统计字符个数
输入一个字符串,以回车结束,统计字符串里英文字母、数字和其他字符的个数(回车符代表结束输入,不计入统计)。
1. 输入一个字符串my_str
1. 设置各类字符数的初值均为0
1. 遍历字符串my_str:
1. 如果当前遍历到的字符是字母:
1. 字母计数加1
2. 否则如果当前遍历到的字符是数字:
1. 数字计数加1
3. 否则:
1. 其他字符加1
4. 输出分类统计结果
```python
import string
my_string = input()
letter, digit, other = 0, 0, 0 # 用于计数的3个变量均设初值为0
for c in my_string: # 遍历,c依次取值为字符串中的字符
if c in string.ascii_letters: # 若c在字母常量中存在,则c是字母
letter = letter + 1 # 字母计数加1个
elif c in string.digits: # 若c在数字常量中存在,则c是数字
digit = digit + 1 # 数字计数加1个
else:
other = other + 1 # 否则其他字符计数加1个
print(f"letter = {letter}, digit = {digit}, other = {other}")
# 123 The operators in and not in test for membership 456.
# letter = 39, digit = 6, other = 11
定义函数:
接收一个字符串
返回其中各类字符的数量
注意
for i in str:是遍历循环
if i in str:是存在性测试(成员测试)
字符串常量可替代
import string
def classification(my_str):
"""接受一个字符串为参数,分类统计其中字符的类型,以元组形式返回"""
letter, digit, other = 0, 0, 0 # 用于计数的3个变量均设初值为0
for c in my_str: # 遍历,c依次取值为字符串中的字符
if c in string.ascii_letters: # 若c在字母常量中存在,则c是字母
letter = letter + 1 # 字母计数加1个
elif c in string.digits: # 若c在数字常量中存在,则c是数字
digit = digit + 1 # 数字计数加1个
else:
other = other + 1 # 否则其他字符计数加1个
answer = (letter, digit, other)
return answer
if __name__ == '__main__':
s = input()
result = classification(s)
print(f'letter = {result[0]}, digit = {result[1]}, other = {result[2]}')
import string
def classification(my_str):
"""接受一个字符串为参数,分类统计其中字符的类型,以元组形式返回"""
letter, digit, other = 0, 0, 0 # 用于计数的3个变量均设初值为0
for c in my_str: # 遍历,c依次取值为字符串中的字符
if c in string.ascii_letters: # 若c在字母常量中存在,则c是字母
letter = letter + 1 # 字母计数加1个
elif c in string.digits: # 若c在数字常量中存在,则c是数字
digit = digit + 1 # 数字计数加1个
else:
other = other + 1 # 否则其他字符计数加1个
return letter, digit, other # 可一次返回多个值,做为一个元组
if __name__ == '__main__':
s = input()
result = classification(s)
print(f'letter = {result[0]}, digit = {result[1]}, other = {result[2]}')
实例 5.5 字符串加密
在一行中输入一个包括大小写字母和数字的字符串,编程将其中的大写字母用该字母后的第4个字母替换,其他字符原样输出,实现字符串加密。
- 明文序列字符串
- 带偏移量字符串
- 输入明文字符串
- 遍历明文字符串
- 获取当前字符在字符串中的位置序号
- 若值不为-1,字符是明文字符串中的字符
- 根据序号值到偏移字符串中索引对应字符拼接到密文字符串上
- 若值为-1,字符不是明文字符串中的字符
- 将原始字符拼接到密文字符串上(不做加密操作)
- 输出密文
p = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' # 原字符序列 s = 'EFGHIJKLMNOPQRSTUVWXYZABCD' # 替换字符序列,s=p[4:]+p[:4] plaincode = input() # 输入的明文字符串 ciphertext = '' # 空字符串,存放加密字符串 for c in plaincode: # 遍历输入的明文字符串 n = p.find(c) # 返回c在p中的位置序号,找不到时返回-1 if n != -1: # 值为-1表示c在p中不存在,不是大写字母 ciphertext = ciphertext + s[n] # 替换的字符拼接到ciphertext else: # c为大写字母,用序列s中对应位置的字母替换 ciphertext = ciphertext + c # 将原字符拼接到ciphertext上 print(ciphertext) # 输出加密后的字符串
输入:LIFE is SHORT, you NEED PYTHON
输出:PMJI is WLSVX, you RIIH TCXLSR ```python def caesar_cipher(text, offset): p = ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’ # 原字符序列 s = p[offset: ] + p[: offset] # 替换字符序列,s=p[4:]+p[:4] ciphertext = ‘’ # 空字符串,存放加密字符串 for c in text: # 遍历输入的明文字符串
return ciphertext # 输出加密后的字符串n = p.find(c) # 返回c在p中的位置序号,找不到时返回-1 if n != -1: # 值为-1表示c在p中不存在,不是大写字母 ciphertext = ciphertext + s[n] # 替换的字符拼接到ciphertext else: # c为大写字母,用序列s中对应位置的字母替换 ciphertext = ciphertext + c # 将原字符拼接到ciphertext上
txt = ‘LIFE is SHORT, you NEED PYTHON’ print(caesar_cipher(txt, 4))
同时加密大小写字符和数字
```python
import string
def caesar_cipher(text, offset):
"""接收一个字符串为参数,采用字母表和数字中后面第offset个字符代替当前字符的方法
对字符串中的字母和数字进行替换,实现加密效果,返回值为加密的字符串。
例如:2019 abc 替换为5342 def """
lower = string.ascii_lowercase # 小写字母
upper = string.ascii_uppercase # 大写字母
digit = string.digits
before = string.ascii_letters + digit
after = lower[offset:] + lower[:offset] + upper[offset:] + upper[:offset] + digit[offset:] + digit[:offset]
table = ''.maketrans(before, after)
ciphertext = text.translate(table)
return ciphertext
if __name__ == '__main__':
plaintext = input()
num = int(input())
print(caesar_cipher(plaintext, num))
输入
LIFE is SHORT, you NEED PYTHON,1942
4
输出
PMJI mw WLSVX, csy RIIH TCXLSR,5386
能力点2:查找与替换
查找:获取序列中元素的序号
str.find(sub[, start[, end]]),找不到该元素时返回-1;
str.index(sub[, start[, end]]),找不到该元素时触发异常
替换:替换后得到新字符串对象
str.replace(old, new[, count]),替换old子串为new子串,替换次数由count指定
s = '13297966288'
print(s.replace(s[3:7],'****')) # 产生新对象
print(s) # 原字符串仍存在
text = """The food's name is "Sweet and sour ribs".It's my favorite meal.This is the steps:"""
for c in """'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'""":
text.replace(c, ' ') # 将符号替换为空格
print(text)
# The food's name is "Sweet and sour ribs".It's my favorite meal.This is the steps:
import string
text = """The food's name is "Sweet and sour ribs".It's my favorite meal.This is the steps:"""
for c in string.punctuation: # 符号常量
text = text.replace(c, ' ')
print(text)
# The food s name is Sweet and sour ribs It s my favorite meal This is the steps
能力点3:字符串切分与拼接
切分:str.split(sep=None, maxsplit = -1),结果为列表
连接:’s’.join(seq): 将可迭代对象seq中的字符串用指定字符s连接起来
拼接:sum(iterable, /, start=0): 将列表或元组中的子序列拼接起来
拼接:seq1+seq1:多个字符串和列表可以拼接为一个新的字符串
重复:seq * n: 将一个序列重复多次得到一个新序列
5.3.6 常用字符串处理方法
Python内置的字符串处理方法非常多,这里只介绍一些特别常用的方法(见表5.3):
表 5.3 常用字符串处理方法
| 方法名 | 描述 |
|---|---|
| str.upper()/str.lower() | 转换字符串str中所有字母为大写/小写 |
| str.strip() | 用于移除字符串开头、结尾指定的字符(缺省时去掉空白字符,包括\t、\n、\r、\x0b、\x0c等) |
| str.join(iterable) | 以字符串str作为分隔符,将可迭代对象 iterable中字符串元素拼接为一个新的字符串。当iterable中存在非字符串元素时,返回一个TypeError 异常。 |
| str.split(sep=None, maxsplit = -1) | 根据分隔符sep将字符串str切分成列表,缺省时根据空格切分,可指定逗号或制表符等。maxsplit值存在且非 -1 时,最多切分maxsplit次。 |
| str.count(sub[, start[, end]]) | 返回 sub 在字符串str 里面出现的次数,如果start 或者 end 指定则返回指定范围内 sub出现的次数。 |
| str.find(sub[, start[, end]]) | 检测 sub 是否包含在字符串 str 中,如果是返回开始的索引值,否则返回-1。如果 start 和 end 指定范围,则检查是否包含在指定范围内。 |
| str.replace(old, new[, count]) | 把字符串str中的 old 替换成 new,如果 count 指定,则替换不超过 count 次,否则有多个old子串时全部替换为new。 |
| str.index(sub[, start[, end]]) | 与find()方法一样,返回子串存在的起始位置,如果sub不在字符串 str中会报一个异常。 |
| for in |
对字符串string进行遍历,依次将字符串string中的字符赋值给前面的变量var |
示例5.6:统计文件中单词数量
import string
with open('../data/txt/gone with the wind.txt', 'r', encoding='utf-8') as novel:
txt = novel.read().lower() # 读文件为字符串并转小写
# symbols = '!"#$%&()*+,-.:;[\'][\"]<=>?@[\\]^_‘{|}~/' # 作用同下条
symbols = string.punctuation # punctuation表示所有符号
for ch in symbols: # 遍历符号,每个循环替换掉文本中一种符号
txt = txt.replace(ch, " ") # 所有符号替换为空格
# 创建新对象,重用名字txt实现在前次替换结果上重复替换
print(txt) # 替换后的文本
word_lst = txt.split() # 切换为列表
print(len(word_lst)) # 列表长度为单词数量
实例 5.7 数据脱敏
手机号属于个人隐私信息,编程将用户输入的手机号的4-7位用“*”替换。输入格式为: 11位数字的手机号码,如:13912345678。
info = input() # 输入13213213211
infoPvt = info[:3] + '*' * 4 + info[-4:] # 字符串切片和拼接
print(infoPvt) # 132****3211
这个问题,也可以考虑用替换的方法解决。info.replace(info[3:7], ‘‘) 可以直接将字符串变量info中的序号第3-6的这4个字符替换为“”。这里需要注意的是,这个替换会创建新的对象,变量info中存储的字符串并没有变化。如果需要改变变量info中存储的字符串,需要用替换过的字符串重新对变量info进行赋值。
info = input() # 输入13943214321
infoPvt1 = info.replace(info[3:7], '****') # 字符串替换
infoPvt2 = info.replace(info[3:7], '****', 1) # 仅替换1次
print(infoPvt1) # 139********
print(infoPvt2) # 139****4321
此类问题一般不建议使用replace()进行替换
输入:13213213211
输出:321
**3213211
示例5.8 获取文件中的数据
with open('../data/csv/score.csv','r',encoding='utf-8') as data:
score_ls = [] # 创建空列表,容纳文件中的数据
for line in data:
score_ls.append(line.strip().split(','))
print(score_ls)
[['姓名', 'C语言', 'Java', 'Python', 'C#', 'C++'],
['罗明', '95', '96', '85', '63', '91'],
['朱佳', '75', '93', '66', '85', '88'],
['李思', '86', '76', '96', '93', '67'],
['郑君', '88', '98', '76', '90', '89'],
['王雪', '99', '96', '91', '88', '86']]
with open('../data/csv/score.csv','r',encoding='utf-8') as data:
score_ls = [] # 创建空列表,容纳文件中的数据
for line in data:
score_ls.append(line.strip().split(','))
print(score_ls)
with open('../data/csv/score.csv','r',encoding='utf-8') as data:
score_ls = [] # 创建空列表,容纳文件中的数据
for line in data:
score_ls.append(line.strip().split(','))
score = []
for ls in score_ls[1:]: # 遍历列表中序号1以后的元素
score = score + ls # 将子列表拼接到一个列表中
print(score)
['罗明', '95', '96', '85', '63', '91', '朱佳', '75', '93', '66', '85', '88', '李思', '86', '76', '96', '93', '67', '郑君', '88', '98', '76', '90', '89', '王雪', '99', '96', '91', '88', '86']
with open('../data/csv/score.csv','r',encoding='utf-8') as data:
score_ls = [] # 创建空列表,容纳文件中的数据
for line in data:
score_ls.append(line.strip().split(','))
print(score_ls)
score = sum(score_ls[1:],[]) # 作用同前面4条语句,将子列表拼接到一个列表中
print(score)
print(score[::6]) # 切片获取姓名,['罗明', '朱佳', '李思', '郑君', '王雪']
print(score[1::6]) # 切片获取C语言成绩,['95', '75', '86', '88', '99']
print(score[3::6]) # 切片获取Python成绩,['85', '66', '96', '76', '91']
print(','.join(score[::6])) # 拼接姓名为字符串,'罗明,朱佳,李思,郑君,王雪'
print(','.join(score[::6])+'\n') # 拼接姓名为字符串,'罗明,朱佳,李思,郑君,王雪\n'
[['姓名', 'C语言', 'Java', 'Python', 'C#', 'C++'],
['罗明', '95', '96', '85', '63', '91'],
['朱佳', '75', '93', '66', '85', '88'],
['李思', '86', '76', '96', '93', '67'],
['郑君', '88', '98', '76', '90', '89'],
['王雪', '99', '96', '91', '88', '86']]
['罗明', '95', '96', '85', '63', '91', '朱佳', '75', '93', '66', '85', '88', '李思', '86', '76', '96', '93', '67', '郑君', '88', '98', '76', '90', '89', '王雪', '99', '96', '91', '88', '86']
['罗明', '朱佳', '李思', '郑君', '王雪']
['95', '75', '86', '88', '99']
['85', '66', '96', '76', '91']
罗明,朱佳,李思,郑君,王雪
罗明,朱佳,李思,郑君,王雪
能力点3 字符串格式化
<模板字符串>.format(<逗号分隔的参数>)
format()方法中<模板字符串>的大括号中除了包括参数序号,还可以包括格式控制信息。此时,位置的内部样式如下:
{<参数序号>: <格式控制标记>}
其中,<格式控制标记>用来控制参数显示时的格式,包括:
<填充><对齐><宽度>,<.精度><类型>6 个字段,format格式控制标记如表5.10所示。
表 5.10 format格式控制标记
| 整数 | : | 填充 | 对齐 | 宽度 | , | .精度 | 类别 |
|---|---|---|---|---|---|---|---|
| 参数序号 | 引导符号 | 填充字符 | 左对齐:< 右对齐:> 居中: ^ |
输出宽度 | 数字千位分隔符 | 浮点数小数位数 字符串最大输出长度 |
c Unicode 字符 d 十进制 b/o/x 二/八/十六进制 e/E 浮点数指数形式 f/F 浮点数标准形式 |
format_spec ::= [[fill]align][sign][#][0][width][grouping_option][.precision][type]
fill ::= <any character>
align ::= "<" | ">" | "=" | "^"
sign ::= "+" | "-" | " "
width ::= digit+
grouping_option ::= "_" | ","
precision ::= digit+
type ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" | "n" | "o" | "s" | "x" | "X" | "%"
‘#’ 选项可让“替代形式”被用于执行转换,替代形式会针对不同的类型分别定义,此选项仅适用于整数、浮点数和复数类型。
对于整数类型,当使用二进制、八进制或十六进制输出时,此选项会为输出值分别添加相应的 ‘0b’, ‘0o’, ‘0x’ 或 ‘0X’ 前缀。
对于浮点数和复数类型,替代形式会使得转换结果总是包含小数点符号,即使其不带小数部分。 通常只有在带有小数部分的情况下,此类转换的结果中才会出现小数点符号。
此外,对于 ‘g’ 和 ‘G’ 转换,末尾的零不会从结果中被移除。
示例5.9 格式化输出
width = 6 # 输出宽度
for num in range(90, 100): # 遍历90-99的整数
for base in 'dxobc': # 遍历类别符号,分别表示10、16、8、2进制和字符
print('{0:<{width}{base}}'.format(num, base=base, width=width), end=' ')
# print(f'{num:<{width}{base}}', end=' ') # 作用同上一行
print() # 换行
90 5a 132 1011010 Z
91 5b 133 1011011 [
92 5c 134 1011100 \
93 5d 135 1011101 ]
94 5e 136 1011110 ^
95 5f 137 1011111 _
96 60 140 1100000 `
97 61 141 1100001 a
98 62 142 1100010 b
99 63 143 1100011 c
能力点4:获得随机数字与元素
5.4 random模块及其应用
import random
表 5.15 random模块主要函数
| 函数 | 描述与示例 |
|---|---|
| random.seed() | 初始化随机数生成器,缺省时用系统时间做种子。seed 必须是下列类型之一: NoneType、int、float、str、bytes或bytearray。 random.seed( 10 ) # 用整数10做种子 |
| random.randint(a, b) | 产生[a,b]之间(包括b)的一个随机整数 print(random.randint(1,3)) # 输出3 |
| random.random() | 产生[0.0,1.0)之间的一个随机浮点数 print(random.random()) # 0.5714025946899135 |
| random.choice(seq) | 从非空序列seq中随机产生一个元素,当序列为空时,触发索引异常 print(random.choice([‘win’, ‘lose’, ‘draw’])) # 输出’draw’ |
| random.choices(population, weights=None, *, cum_weights=None, k=1) | 从population中选择替换,返回大小为 k 的元素列表。 |
| random.shuffle(x[,random]) | 将可变序列x顺序打乱 deck=[‘ace’,’two’, ‘three’, ‘four’] random.shuffle(deck) print(deck) # 输出[‘four’, ‘three’, ‘two’, ‘ace’] |
| random.sample(population, k) | 从列表、元组、字符串、集合、range对象等分布式序列中随机选取k个元素,以列表形式返回。 print(random.sample([10, 20, 30, 40, 50], k=4)) # 输出 [50, 10, 20, 30] 打乱不可变序列,返回列表: x = ‘123456’ print(random.sample(x, k=len(x))) # [‘5’, ‘2’, ‘1’, ‘4’, ‘6’, ‘3’] |
实例 5.10 模拟校验验证码
用户在网络上注册或登录各平台时,经常需要输入验证码。这些验证码采取随机生成的方式产生,包含大小写字母和数字。用户输入验证码时,一般不区分大小写,请编写程序对用户的输入的验证码进行验证。
用户输入时不区分大小写,在验证前可以将用户输入的字符串和验证码中的大写字母都转为小写字母;或反过来,将所有小写字母转换为大写字母,再进行匹配验证。
import random # 导入随机数模块
import string # 导入字符串模块
# sample()方法从包含字母与数字的字符串中随机获取6个元素,返回列表
code = random.sample(string.ascii_letters+string.digits, 6)
print(code) # ['v', '8', 'G', 'Z', 'w', '7']
vcode = ''.join(code).upper() # 列表code元素连接为字符串,字母转大写
print(vcode) # V8GZW7
check_code = input().upper() # 将输入中的字母转为大写
if check_code == vcode: # 将输入和产生的验证码进行比较
print('验证码正确')
else:
print('验证码错误,请重新输入')
import random
import string
def generate_code(s, length):
"""根据字符集s生成一个长度为length的校验码,将字母转为大写,
返回字符串"""
code = random.sample(s, length) # 列表['v', '8', 'G', 'Z', 'w', '7']
sys_code = ''.join(code).upper() # 列表code元素连接为字符串,字母转大写
return sys_code # V8GZW7
def check_code(sys_code, user_code):
"""核对校验码,检查用户输入与系统校验码是否相同,返回布尔值"""
if sys_code == user_code: # 将输入和产生的验证码进行比较
return True
else:
return False
if __name__ == '__main__':
code_str = string.ascii_letters + string.digits
s_code = generate_code(code_str, 6)
print(s_code) # 显示产生的验证码,用于测试程序
u_code = input().upper() # 将输入中的字母转为大写
if check_code(s_code, u_code):
print('验证码正确')
else:
print('验证码错误,请重新输入')
实例 5.11 模拟微软序列号
微软产品一般都一个25位的、用于区分每份微软产品的产品序列号。产品序列号由五组被“-”分隔开,由字母数字混合编制的字符串组成,每组字符串是由五个字符串组成。例如:
3CVX3-BJWXM-6HCYX-QEK9R-CVG4R
每个字符是取自于以下24个字母及数字之中的一个:
B C E F G H J K M P Q R T V W X Y 2 3 4 6 7 8 9
采用这24个字符的原因是为了避免混淆相似的字母和数字,如I 和1,O 和0等,减少不必要的麻烦。
import random # 导入随机数模块
keySn = '' # 创建一个空字符串,容纳序列号
code = 'BCEFGHJKMPQRTVWXY2346789' # 限定字符集合
for i in range(5):
s = '' # 创建空字符串,容纳序列号一节
for j in range(5): # 每次产生1个字符,5字符一组
s = s + random.choice(code) # 产生一个字符,拼接在字符串后
if i == 0: # 判断是否为第一个字符串
keySn = keySn + s # 直接拼接在字符串keySn上
else:
keySn = keySn + '-' + s # 用“-”拼接字符串
print(keySn) # EPMQW-RJFBR-T99EG-CT968-XE9PR
import random
def generate_sn(txt):
"""根据字符集s生成一个长度为length的校验码,将字母转为大写,
返回字符串"""
sn = '' # 创建一个空字符串,容纳序列号
for i in range(5):
s = '' # 创建空字符串,容纳序列号一节
for j in range(5): # 每次产生1个字符,5字符一组
s = s + random.choice(txt) # 产生一个字符,拼接在字符串后
if i == 0: # 判断是否为第一个字符串
sn = sn + s # 直接拼接在字符串keySn上
else:
sn = sn + '-' + s # 用“-”拼接字符串
return sn # EPMQW-RJFBR-T99EG-CT968-XE9PR
if __name__ == '__main__':
text = 'BCEFGHJKMPQRTVWXY2346789' # 限定字符集合
print(generate_sn(text))
也可以借助列表,并使用join()方法实现字符串的连接:
import random # 导入随机数模块
keySn = [] # 创建一个空列表,用于容纳序列号
code = 'BCEFGHJKMPQRTVWXY2346789' # 字符集合
for i in range(5):
s = random.sample(code, 5) # 从code中随机取5个字符
keySn.append(''.join(s)) # 将5个字符连接为字符串附加到列表
print(keySn) # ['WCMRQ', 'Y4MCR', 'BGPJ6', '3KPB9', '23RGQ']
print('-'.join(keySn))# 用‘-’将列表中的元素连接起来
算法1:蒙特卡洛模拟
蒙特卡罗法也称统计模拟法、统计试验法。是把概率现象作为研究对象的数值模拟方法。是按抽样调查法求取统计值来推定未知特性量的计算方法。蒙特卡罗是摩纳哥的著名赌城,该法为表明其随机抽样的本质而命名。故适用于对离散系统进行计算仿真试验。在计算仿真中,通过构造一个和系统性能相近似的概率模型,并在数字计算机上进行随机试验,可以模拟系统的随机特性。
蒙特卡罗法 (又称统计试验法)是描述装备运用过程中各种随机现象的基本方法,而且它特别适用于一些解析法难以求解甚至不可能求解的问题
蒙特卡罗法的基本思想是:
为了求解问题,首先建立一个概率模型或随机过程,使它的参数或数字特征等于问题的解:然后通过对模型或过程的观察或抽样试验来计算这些参数或数字特征,最后给出所求解的近似值。解的精确度用估计值的标准误差来表示。
蒙特卡罗法 的主要理论基础是概率统计理论,主要手段是随机抽样、统计试验。用蒙特卡罗法求解实际问题的基本步骤为:
(1)根据实际问题的特点.构造简单而又便于实现的概率统计模型.使所求的解恰好是所求问题的概率分布或数学期望;
(2)给出模型中各种不同分布随机变量的抽样方法;
(3)统计处理模拟结果,给出问题解的统计估计值和精度估计值。
示例5.12 蒙特卡洛法解百钱百鸡
import random
def monte_carlo_cock(num):
answer = []
for i in range(num):
hen = random.randint(1, 20)
cock = random.randint(1, 33)
chicken = 100 - cock - hen
if chicken % 3 == 0 and 5 * cock + 3 * hen + chicken // 3 == 100 and cock + hen + chicken == 100:
group = [cock, hen, chicken]
if group not in answer:
answer.append(group)
return answer
if __name__ == '__main__':
result = monte_carlo_cock(10000)
print(result)
示例5.13 赌徒博弈(思政)
如果赌博输赢的概率都是50%,为什么长久赌博的人多会倾家荡产?
设定:
· 设定我们假设有 1000 个玩家,每人手里有 10000 元的筹码,可以用来赌博。
· 每一局游戏,玩家都可以抵押 500 元的筹码。输了,筹码不退还;赢了,筹码翻倍。
· 输赢的概率各占 50%。
· 所有玩家一共进行 100 局游戏。一旦任何玩家筹码为0,必须中途退出游戏。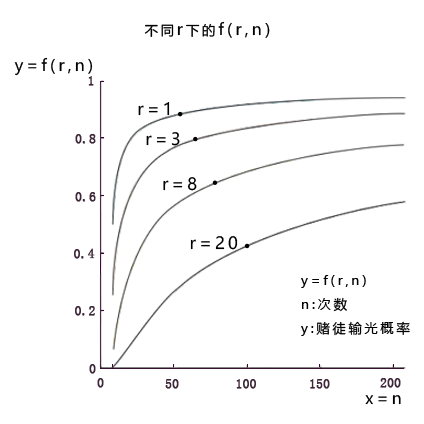
import random
def gamble(dealer, player, bet, n):
"""接收庄家和玩家资本,每局赌资和赌局数量,返回100局后或有一方赌资输光时的资本数值"""
for i in range(n):
r = random.randint(0, 1)
if r == 1:
dealer = dealer + bet
player = player - bet
else:
dealer = dealer - bet
player = player + bet
if dealer <= 0 or player <= 0:
return dealer, player, i
else:
return dealer, player, n
if __name__ == '__main__':
dealer, player = 1000000, 10000 # 庄家和玩家的资本
n = 100 # 每个玩家赌100局
for bet in [500, 1000, 1500, 2000, 2500, 3000]: # 每次赌资500
result = []
for i in range(1000): # 共1000个玩家
result.append(gamble(dealer, player, bet, n))
print(f'每次押注{bet}元')
print(f'剩余筹码最大值',max([x[1] for x in result]))
print(f'剩余筹码最小值',min([x[1] for x in result]))
print('余额大于等于本金的人数',len([x[1] for x in result if x[1] >= 10000])) # 余额大于等于本金的人数
print('余额小于等于0的人数',len([x[1] for x in result if x[1] <= 0])) # 余额小于等于0的人数
print()
押注500
28000 # 筹码最大值
0 # 筹码最小值
553 # 余额大于等于本金的人数
46 # 余额小于等于0的人数
押注1000
42000
0
516 # 余额大于等于本金的人数
318 # 余额小于等于0的人数
押注1500
58000
-500
426 # 余额大于等于本金的人数
505 # 余额小于等于0的人数
押注2000
82000
0
374 # 余额大于等于本金的人数
599 # 余额小于等于0的人数
押注2500
85000
0
281 # 余额大于等于本金的人数
713 # 余额小于等于0的人数
押注3000
100000
-2000
306 # 余额大于等于本金的人数
683 # 余额小于等于0的人数
示例5.14 随机出题的四则运算
import random
def calculator(n, maximum):
"""随机产生n道正整数四则运算的题目,用户输入计算结果,
判断输入正确与否,并统计正确率。题目保证减法不出现负数."""
correct = 0
for i in range(n): # 循环n次,每次产生一个新问题
b = random.randint(0, maximum) # 随机产生一个maximum以内整数
a = random.randint(b, maximum) # 随机产生一个b到maximum以内整数,避免减法出现负数
sign = random.choice('+-*/') # 随机获取一个运算符号
print(f'{a}{sign}{b}=', end='') # 5+10=,格式化输出
result = float(input()) # 用户输入计算结果,转浮点数
if result == eval(f'{a}{sign}{b}'): # eval()将字符串转表达式并计算
print('恭喜你,回答正确')
correct = correct + 1 # 统计回答正确的题目数量
else:
print('回答错误,你要加油哦!')
print(f'答对{correct}题,正确率为{correct/n * 100}%')
if __name__ == '__main__':
num = int(input('请输入出题数量:'))
m = int(input('请输入参与计算的最大数字:'))
calculator(num, m)
9/3=3
恭喜你,回答正确
4-4=0
恭喜你,回答正确
7-4=3
恭喜你,回答正确
9+4=13
恭喜你,回答正确
3+1=4
恭喜你,回答正确
6*5=30
恭喜你,回答正确
9-9=0
恭喜你,回答正确
10-4=6
恭喜你,回答正确
9+8=17
恭喜你,回答正确
3-2=1
恭喜你,回答正确
答对10题,正确率为100.0%

若有收获,就点个赞吧
0 人点赞
